 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelation Sketches for Approximate Join-Correlation Queries
Paper and Code
Apr 07, 2021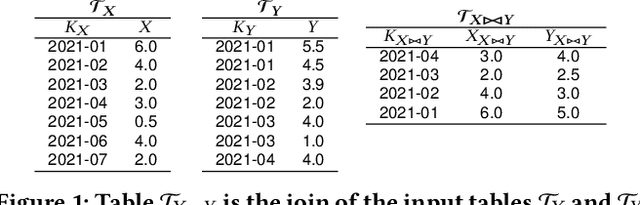


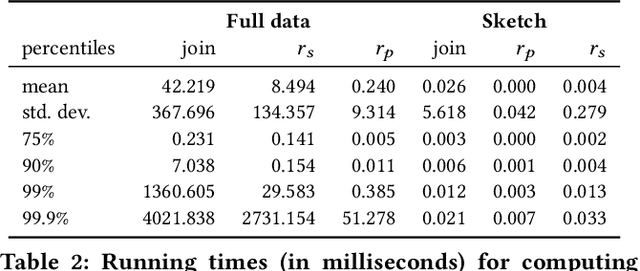
The increasing availability of structured datasets, from Web tables and open-data portals to enterprise data, opens up opportunities~to enrich analytics and improve machine learning models through relational data augmentation. In this paper, we introduce a new class of data augmentation queries: join-correlation queries. Given a column $Q$ and a join column $K_Q$ from a query table $\mathcal{T}_Q$, retrieve tables $\mathcal{T}_X$ in a dataset collection such that $\mathcal{T}_X$ is joinable with $\mathcal{T}_Q$ on $K_Q$ and there is a column $C \in \mathcal{T}_X$ such that $Q$ is correlated with $C$. A na\"ive approach to evaluate these queries, which first finds joinable tables and then explicitly joins and computes correlations between $Q$ and all columns of the discovered tables, is prohibitively expensive. To efficiently support correlated column discovery, we 1) propose a sketching method that enables the construction of an index for a large number of tables and that provides accurate estimates for join-correlation queries, and 2) explore different scoring strategies that effectively rank the query results based on how well the columns are correlated with the query. We carry out a detailed experimental evaluation, using both synthetic and real data, which shows that our sketches attain high accuracy and the scoring strategies lead to high-quality rankings.