 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theoretical Formulation of Many-body Message Passing Neural Networks
Jul 16, 2024We present many-body Message Passing Neural Network (MPNN) framework that models higher-order node interactions ($\ge 2$ nodes). We model higher-order terms as tree-shaped motifs, comprising a central node with its neighborhood, and apply localized spectral filters on motif Laplacian, weighted by global edge Ricci curvatures. We prove our formulation is invariant to neighbor node permutation, derive its sensitivity bound, and bound the range of learned graph potential. We run regression on graph energies to demonstrate that it scales well with deeper and wider network topology, and run classification on synthetic graph datasets with heterophily and show its consistently high Dirichlet energy growth. We open-source our code at https://github.com/JThh/Many-Body-MPNN.
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs
Jun 22, 2024We propose semantic entropy probes (SEPs), a cheap and reliable method for uncertainty quantification in Large Language Models (LLMs). Hallucinations, which are plausible-sounding but factually incorrect and arbitrary model generations, present a major challenge to the practical adoption of LLMs. Recent work by Farquhar et al. (2024) proposes semantic entropy (SE), which can detect hallucinations by estimating uncertainty in the space semantic meaning for a set of model generations. However, the 5-to-10-fold increase in computation cost associated with SE computation hinders practical adoption. To address this, we propose SEPs, which directly approximate SE from the hidden states of a single generation. SEPs are simple to train and do not require sampling multiple model generations at test time, reducing the overhead of semantic uncertainty quantification to almost zero. We show that SEPs retain high performance for hallucination detection and generalize better to out-of-distribution data than previous probing methods that directly predict model accuracy. Our results across models and tasks suggest that model hidden states capture SE, and our ablation studies give further insights into the token positions and model layers for which this is the case.
Exemplar-based Video Colorization with Long-term Spatiotemporal Dependency
Mar 27, 2023
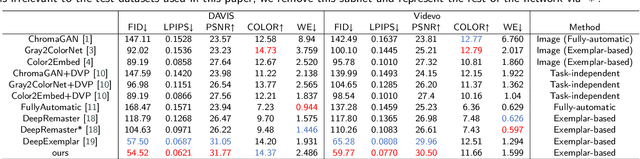
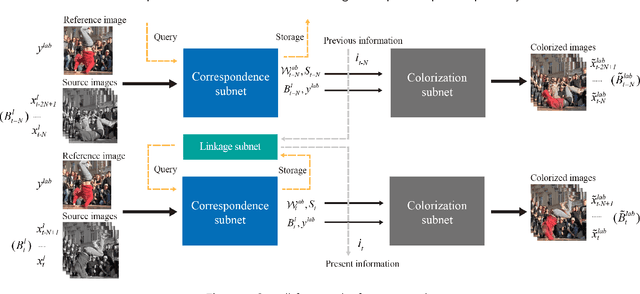

Exemplar-based video colorization is an essential technique for applications like old movie restoration. Although recent methods perform well in still scenes or scenes with regular movement, they always lack robustness in moving scenes due to their weak ability in modeling long-term dependency both spatially and temporally, leading to color fading, color discontinuity or other artifacts. To solve this problem, we propose an exemplar-based video colorization framework with long-term spatiotemporal dependency. To enhance the long-term spatial dependency, a parallelized CNN-Transformer block and a double head non-local operation are designed. The proposed CNN-Transformer block can better incorporate long-term spatial dependency with local texture and structural features, and the double head non-local operation further leverages the performance of augmented feature. While for long-term temporal dependency enhancement, we further introduce the novel linkage subnet. The linkage subnet propagate motion information across adjacent frame blocks and help to maintain temporal continuity. Experiments demonstrate that our model outperforms recent state-of-the-art methods both quantitatively and qualitatively. Also, our model can generate more colorful, realistic and stabilized results, especially for scenes where objects change greatly and irregularly.
A Frequency-aware Software Cache for Large Recommendation System Embeddings
Aug 08, 2022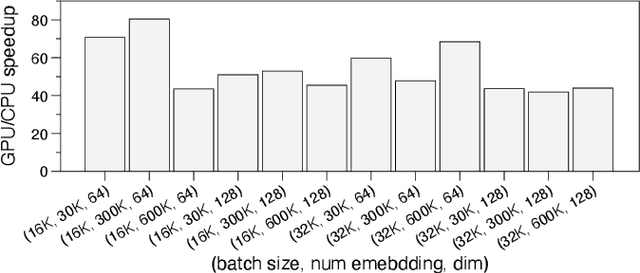
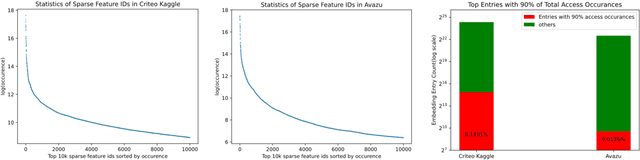
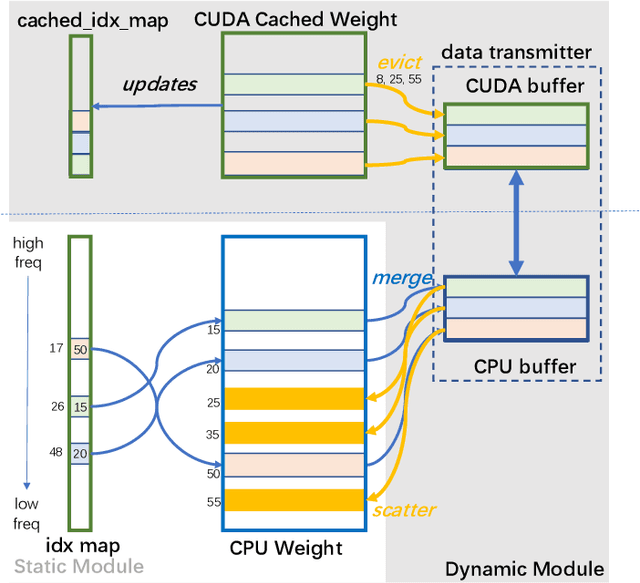
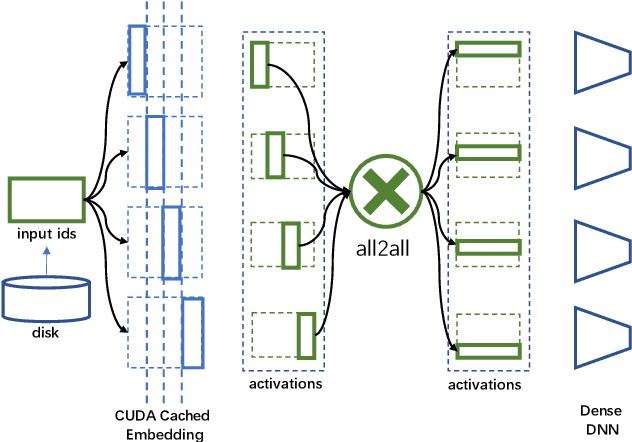
Deep learning recommendation models (DLRMs) have been widely applied in Internet companies. The embedding tables of DLRMs are too large to fit on GPU memory entirely. We propose a GPU-based software cache approaches to dynamically manage the embedding table in the CPU and GPU memory space by leveraging the id's frequency statistics of the target dataset. Our proposed software cache is efficient in training entire DLRMs on GPU in a synchronized update manner. It is also scaled to multiple GPUs in combination with the widely used hybrid parallel training approaches. Evaluating our prototype system shows that we can keep only 1.5% of the embedding parameters in the GPU to obtain a decent end-to-end training speed.