 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAID: Retrieval-Augmented Anomaly Detection
Feb 23, 2026Unsupervised Anomaly Detection (UAD) aims to identify abnormal regions by establishing correspondences between test images and normal templates. Existing methods primarily rely on image reconstruction or template retrieval but face a fundamental challenge: matching between test images and normal templates inevitably introduces noise due to intra-class variations, imperfect correspondences, and limited templates. Observing that Retrieval-Augmented Generation (RAG) leverages retrieved samples directly in the generation process, we reinterpret UAD through this lens and introduce \textbf{RAID}, a retrieval-augmented UAD framework designed for noise-resilient anomaly detection and localization. Unlike standard RAG that enriches context or knowledge, we focus on using retrieved normal samples to guide noise suppression in anomaly map generation. RAID retrieves class-, semantic-, and instance-level representations from a hierarchical vector database, forming a coarse-to-fine pipeline. A matching cost volume correlates the input with retrieved exemplars, followed by a guided Mixture-of-Experts (MoE) network that leverages the retrieved samples to adaptively suppress matching noise and produce fine-grained anomaly maps. RAID achieves state-of-the-art performance across full-shot, few-shot, and multi-dataset settings on MVTec, VisA, MPDD, and BTAD benchmarks. \href{https://github.com/Mingxiu-Cai/RAID}{https://github.com/Mingxiu-Cai/RAID}.
CostFilter-AD: Enhancing Anomaly Detection through Matching Cost Filtering
May 02, 2025



Unsupervised anomaly detection (UAD) seeks to localize the anomaly mask of an input image with respect to normal samples. Either by reconstructing normal counterparts (reconstruction-based) or by learning an image feature embedding space (embedding-based), existing approaches fundamentally rely on image-level or feature-level matching to derive anomaly scores. Often, such a matching process is inaccurate yet overlooked, leading to sub-optimal detection. To address this issue, we introduce the concept of cost filtering, borrowed from classical matching tasks, such as depth and flow estimation, into the UAD problem. We call this approach {\em CostFilter-AD}. Specifically, we first construct a matching cost volume between the input and normal samples, comprising two spatial dimensions and one matching dimension that encodes potential matches. To refine this, we propose a cost volume filtering network, guided by the input observation as an attention query across multiple feature layers, which effectively suppresses matching noise while preserving edge structures and capturing subtle anomalies. Designed as a generic post-processing plug-in, CostFilter-AD can be integrated with either reconstruction-based or embedding-based methods. Extensive experiments on MVTec-AD and VisA benchmarks validate the generic benefits of CostFilter-AD for both single- and multi-class UAD tasks. Code and models will be released at https://github.com/ZHE-SAPI/CostFilter-AD.
One-Point Sampling for Distributed Bandit Convex Optimization with Time-Varying Constraints
Apr 24, 2025This paper considers the distributed bandit convex optimization problem with time-varying constraints. In this problem, the global loss function is the average of all the local convex loss functions, which are unknown beforehand. Each agent iteratively makes its own decision subject to time-varying inequality constraints which can be violated but are fulfilled in the long run. For a uniformly jointly strongly connected time-varying directed graph, a distributed bandit online primal-dual projection algorithm with one-point sampling is proposed. We show that sublinear dynamic network regret and network cumulative constraint violation are achieved if the path-length of the benchmark also increases in a sublinear manner. In addition, an $\mathcal{O}({T^{3/4 + g}})$ static network regret bound and an $\mathcal{O}( {{T^{1 - {g}/2}}} )$ network cumulative constraint violation bound are established, where $T$ is the total number of iterations and $g \in ( {0,1/4} )$ is a trade-off parameter. Moreover, a reduced static network regret bound $\mathcal{O}( {{T^{2/3 + 4g /3}}} )$ is established for strongly convex local loss functions. Finally, a numerical example is presented to validate the theoretical results.
Cross-Modal Learning for Anomaly Detection in Fused Magnesium Smelting Process: Methodology and Benchmark
Jun 13, 2024Fused Magnesium Furnace (FMF) is a crucial industrial equipment in the production of magnesia, and anomaly detection plays a pivotal role in ensuring its efficient, stable, and secure operation. Existing anomaly detection methods primarily focus on analyzing dominant anomalies using the process variables (such as arc current) or constructing neural networks based on abnormal visual features, while overlooking the intrinsic correlation of cross-modal information. This paper proposes a cross-modal Transformer (dubbed FmFormer), designed to facilitate anomaly detection in fused magnesium smelting processes by exploring the correlation between visual features (video) and process variables (current). Our approach introduces a novel tokenization paradigm to effectively bridge the substantial dimensionality gap between the 3D video modality and the 1D current modality in a multiscale manner, enabling a hierarchical reconstruction of pixel-level anomaly detection. Subsequently, the FmFormer leverages self-attention to learn internal features within each modality and bidirectional cross-attention to capture correlations across modalities. To validate the effectiveness of the proposed method, we also present a pioneering cross-modal benchmark of the fused magnesium smelting process, featuring synchronously acquired video and current data for over 2.2 million samples. Leveraging cross-modal learning, the proposed FmFormer achieves state-of-the-art performance in detecting anomalies, particularly under extreme interferences such as current fluctuations and visual occlusion caused by heavy water mist. The presented methodology and benchmark may be applicable to other industrial applications with some amendments. The benchmark will be released at https://github.com/GaochangWu/FMF-Benchmark.
DA-STC: Domain Adaptive Video Semantic Segmentation via Spatio-Temporal Consistency
Nov 22, 2023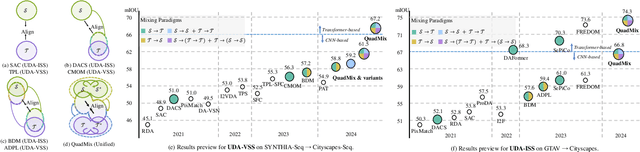
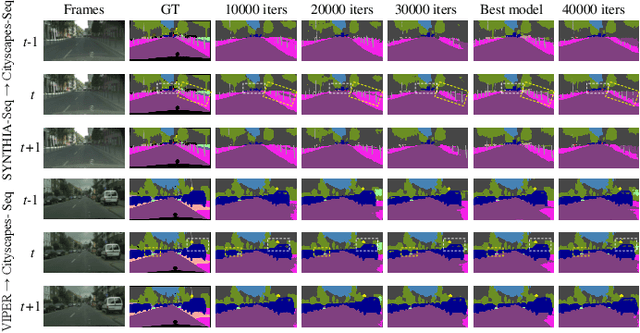
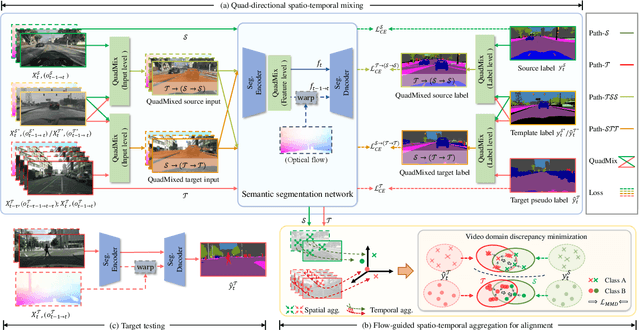
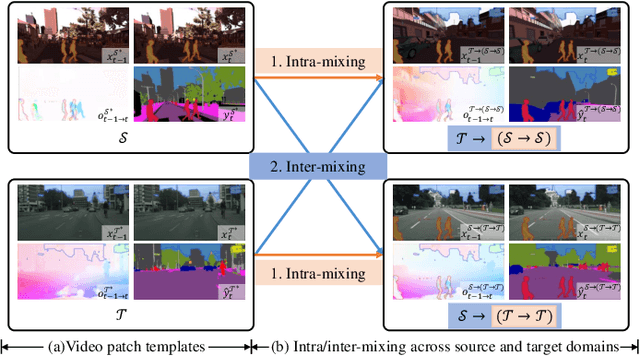
Video semantic segmentation is a pivotal aspect of video representation learning. However, significant domain shifts present a challenge in effectively learning invariant spatio-temporal features across the labeled source domain and unlabeled target domain for video semantic segmentation. To solve the challenge, we propose a novel DA-STC method for domain adaptive video semantic segmentation, which incorporates a bidirectional multi-level spatio-temporal fusion module and a category-aware spatio-temporal feature alignment module to facilitate consistent learning for domain-invariant features. Firstly, we perform bidirectional spatio-temporal fusion at the image sequence level and shallow feature level, leading to the construction of two fused intermediate video domains. This prompts the video semantic segmentation model to consistently learn spatio-temporal features of shared patch sequences which are influenced by domain-specific contexts, thereby mitigating the feature gap between the source and target domain. Secondly, we propose a category-aware feature alignment module to promote the consistency of spatio-temporal features, facilitating adaptation to the target domain. Specifically, we adaptively aggregate the domain-specific deep features of each category along spatio-temporal dimensions, which are further constrained to achieve cross-domain intra-class feature alignment and inter-class feature separation. Extensive experiments demonstrate the effectiveness of our method, which achieves state-of-the-art mIOUs on multiple challenging benchmarks. Furthermore, we extend the proposed DA-STC to the image domain, where it also exhibits superior performance for domain adaptive semantic segmentation. The source code and models will be made available at \url{https://github.com/ZHE-SAPI/DA-STC}.
Distributed Online Convex Optimization with Adversarial Constraints: Reduced Cumulative Constraint Violation Bounds under Slater's Condition
May 31, 2023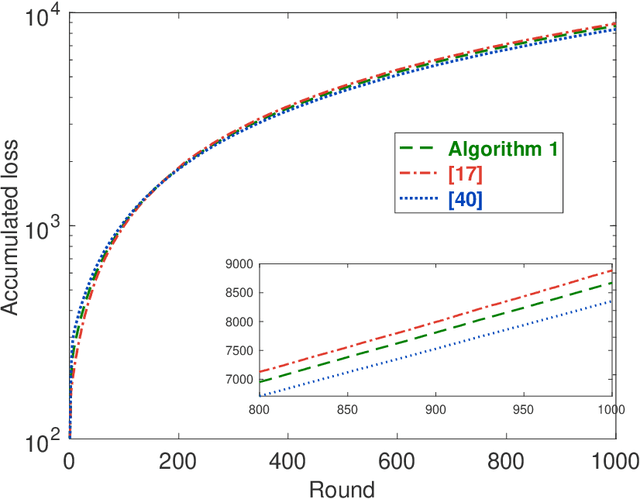
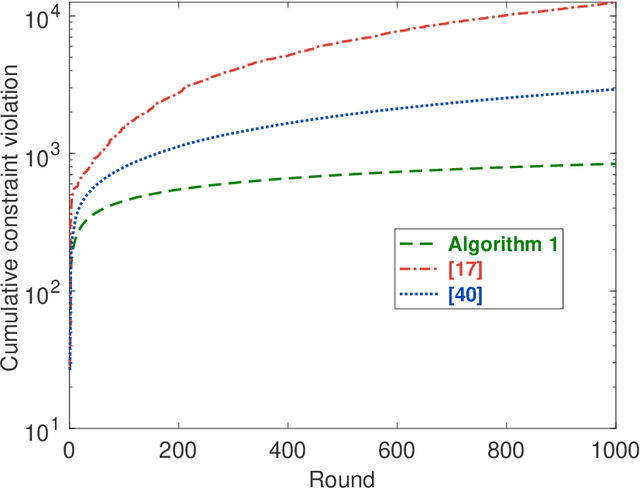
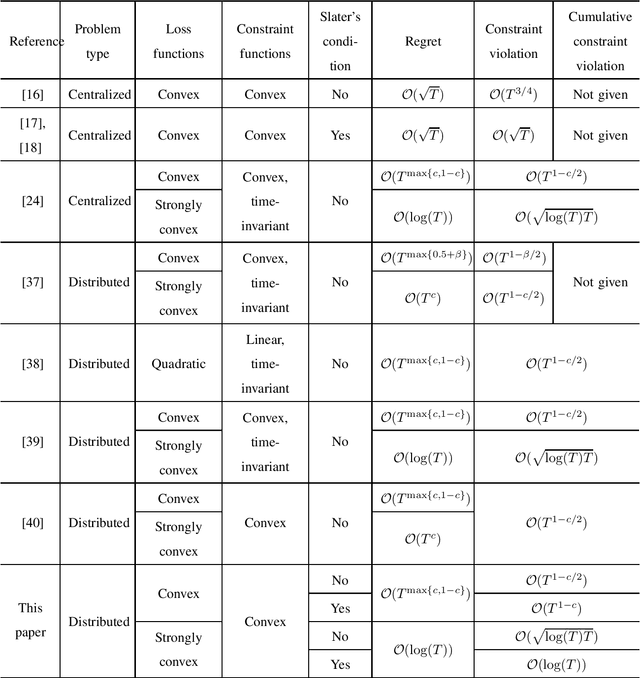

This paper considers distributed online convex optimization with adversarial constraints. In this setting, a network of agents makes decisions at each round, and then only a portion of the loss function and a coordinate block of the constraint function are privately revealed to each agent. The loss and constraint functions are convex and can vary arbitrarily across rounds. The agents collaborate to minimize network regret and cumulative constraint violation. A novel distributed online algorithm is proposed and it achieves an $\mathcal{O}(T^{\max\{c,1-c\}})$ network regret bound and an $\mathcal{O}(T^{1-c/2})$ network cumulative constraint violation bound, where $T$ is the number of rounds and $c\in(0,1)$ is a user-defined trade-off parameter. When Slater's condition holds (i.e, there is a point that strictly satisfies the inequality constraints), the network cumulative constraint violation bound is reduced to $\mathcal{O}(T^{1-c})$. Moreover, if the loss functions are strongly convex, then the network regret bound is reduced to $\mathcal{O}(\log(T))$, and the network cumulative constraint violation bound is reduced to $\mathcal{O}(\sqrt{\log(T)T})$ and $\mathcal{O}(\log(T))$ without and with Slater's condition, respectively. To the best of our knowledge, this paper is the first to achieve reduced (network) cumulative constraint violation bounds for (distributed) online convex optimization with adversarial constraints under Slater's condition. Finally, the theoretical results are verified through numerical simulations.
Data-Driven Inverse Reinforcement Learning for Expert-Learner Zero-Sum Games
Jan 05, 2023



In this paper, we formulate inverse reinforcement learning (IRL) as an expert-learner interaction whereby the optimal performance intent of an expert or target agent is unknown to a learner agent. The learner observes the states and controls of the expert and hence seeks to reconstruct the expert's cost function intent and thus mimics the expert's optimal response. Next, we add non-cooperative disturbances that seek to disrupt the learning and stability of the learner agent. This leads to the formulation of a new interaction we call zero-sum game IRL. We develop a framework to solve the zero-sum game IRL problem that is a modified extension of RL policy iteration (PI) to allow unknown expert performance intentions to be computed and non-cooperative disturbances to be rejected. The framework has two parts: a value function and control action update based on an extension of PI, and a cost function update based on standard inverse optimal control. Then, we eventually develop an off-policy IRL algorithm that does not require knowledge of the expert and learner agent dynamics and performs single-loop learning. Rigorous proofs and analyses are given. Finally, simulation experiments are presented to show the effectiveness of the new approach.
Geo-NI: Geometry-aware Neural Interpolation for Light Field Rendering
Jun 20, 2022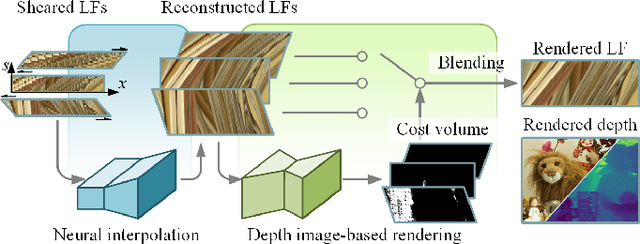
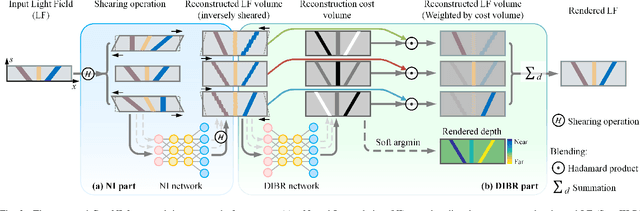


In this paper, we present a Geometry-aware Neural Interpolation (Geo-NI) framework for light field rendering. Previous learning-based approaches either rely on the capability of neural networks to perform direct interpolation, which we dubbed Neural Interpolation (NI), or explore scene geometry for novel view synthesis, also known as Depth Image-Based Rendering (DIBR). Instead, we incorporate the ideas behind these two kinds of approaches by launching the NI with a novel DIBR pipeline. Specifically, the proposed Geo-NI first performs NI using input light field sheared by a set of depth hypotheses. Then the DIBR is implemented by assigning the sheared light fields with a novel reconstruction cost volume according to the reconstruction quality under different depth hypotheses. The reconstruction cost is interpreted as a blending weight to render the final output light field by blending the reconstructed light fields along the dimension of depth hypothesis. By combining the superiorities of NI and DIBR, the proposed Geo-NI is able to render views with large disparity with the help of scene geometry while also reconstruct non-Lambertian effect when depth is prone to be ambiguous. Extensive experiments on various datasets demonstrate the superior performance of the proposed geometry-aware light field rendering framework.
Regret and Cumulative Constraint Violation Analysis for Online Convex Optimization with Long Term Constraints
Jun 09, 2021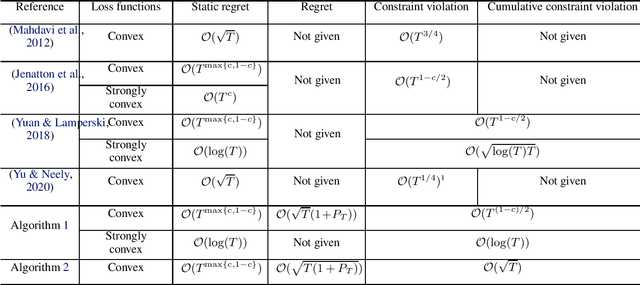
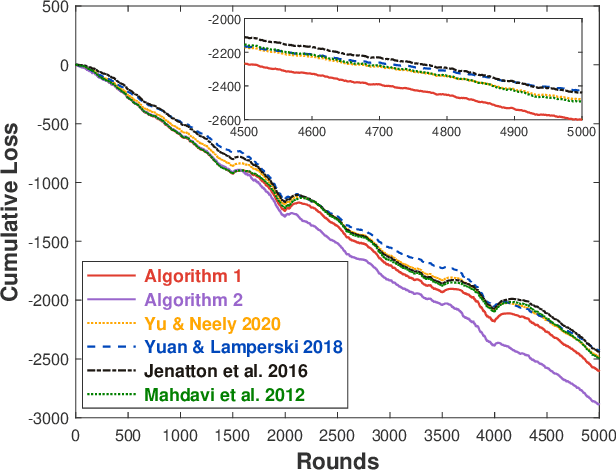
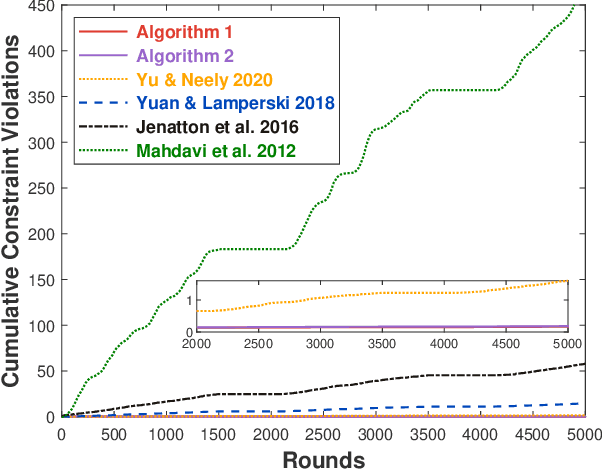
This paper considers online convex optimization with long term constraints, where constraints can be violated in intermediate rounds, but need to be satisfied in the long run. The cumulative constraint violation is used as the metric to measure constraint violations, which excludes the situation that strictly feasible constraints can compensate the effects of violated constraints. A novel algorithm is first proposed and it achieves an $\mathcal{O}(T^{\max\{c,1-c\}})$ bound for static regret and an $\mathcal{O}(T^{(1-c)/2})$ bound for cumulative constraint violation, where $c\in(0,1)$ is a user-defined trade-off parameter, and thus has improved performance compared with existing results. Both static regret and cumulative constraint violation bounds are reduced to $\mathcal{O}(\log(T))$ when the loss functions are strongly convex, which also improves existing results. %In order to bound the regret with respect to any comparator sequence, In order to achieve the optimal regret with respect to any comparator sequence, another algorithm is then proposed and it achieves the optimal $\mathcal{O}(\sqrt{T(1+P_T)})$ regret and an $\mathcal{O}(\sqrt{T})$ cumulative constraint violation, where $P_T$ is the path-length of the comparator sequence. Finally, numerical simulations are provided to illustrate the effectiveness of the theoretical results.
Regret and Cumulative Constraint Violation Analysis for Distributed Online Constrained Convex Optimization
May 01, 2021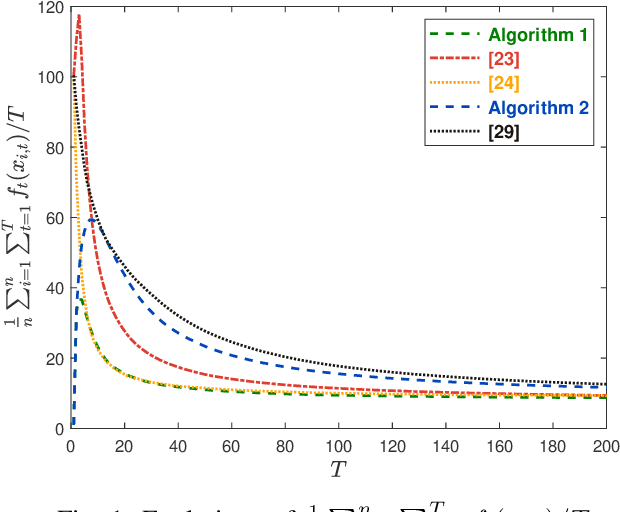
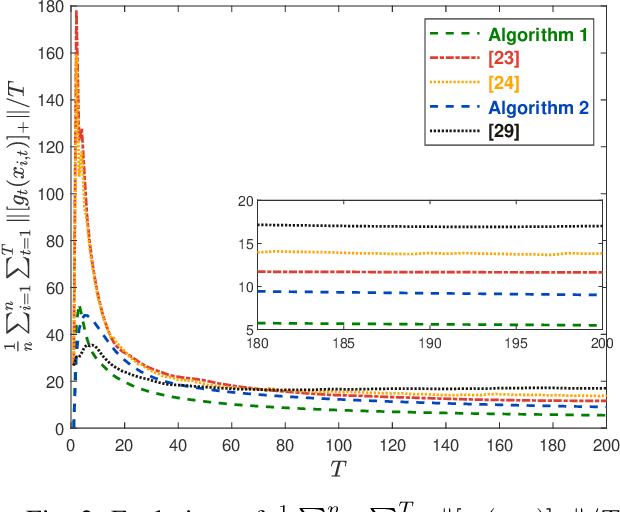
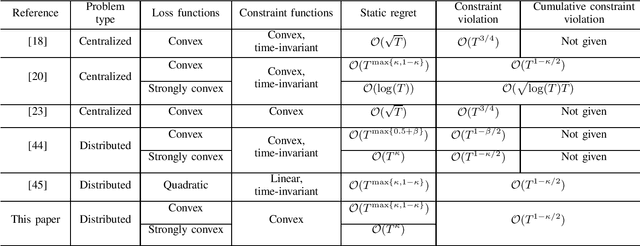
This paper considers the distributed online convex optimization problem with time-varying constraints over a network of agents. This is a sequential decision making problem with two sequences of arbitrarily varying convex loss and constraint functions. At each round, each agent selects a decision from the decision set, and then only a portion of the loss function and a coordinate block of the constraint function at this round are privately revealed to this agent. The goal of the network is to minimize network regret and constraint violation. Two distributed online algorithms with full-information and bandit feedback are proposed. Both dynamic and static network regret bounds are analyzed for the proposed algorithms, and network cumulative constraint violation is used to measure constraint violation, which excludes the situation that strictly feasible constraints can compensate the effects of violated constraints. In particular, we show that the proposed algorithms achieve $\mathcal{O}(T^{\max\{\kappa,1-\kappa\}})$ static network regret and $\mathcal{O}(T^{1-\kappa/2})$ network cumulative constraint violation, where $T$ is the total number of rounds and $\kappa\in(0,1)$ is a user-defined trade-off parameter. Moreover, if the loss functions are strongly convex, then the static network regret bound can be reduced to $\mathcal{O}(T^{\kappa})$. Finally, numerical simulations are provided to illustrate the effectiveness of the theoretical results.