 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDA-STC: Domain Adaptive Video Semantic Segmentation via Spatio-Temporal Consistency
Paper and Code
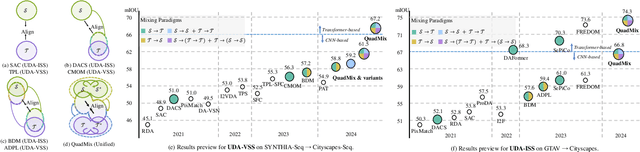
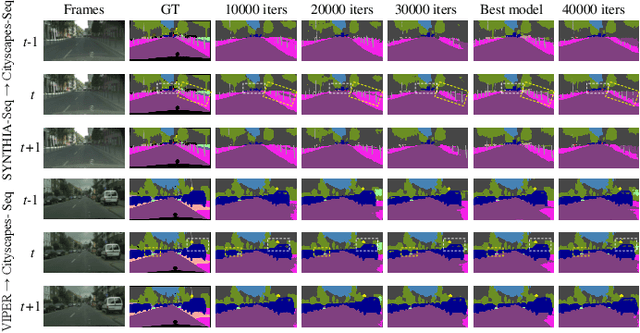
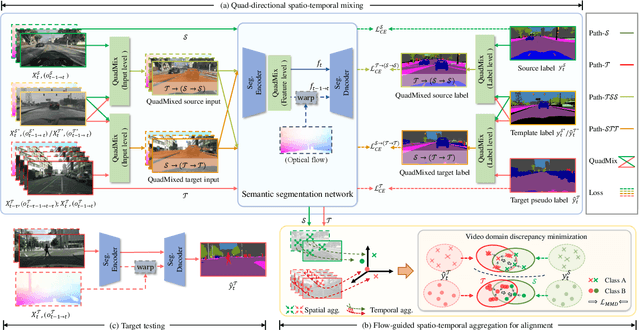
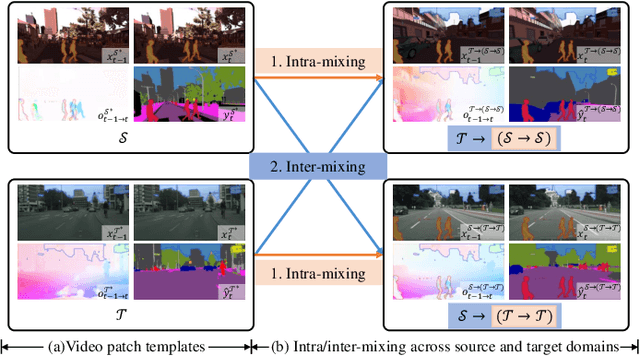
Video semantic segmentation is a pivotal aspect of video representation learning. However, significant domain shifts present a challenge in effectively learning invariant spatio-temporal features across the labeled source domain and unlabeled target domain for video semantic segmentation. To solve the challenge, we propose a novel DA-STC method for domain adaptive video semantic segmentation, which incorporates a bidirectional multi-level spatio-temporal fusion module and a category-aware spatio-temporal feature alignment module to facilitate consistent learning for domain-invariant features. Firstly, we perform bidirectional spatio-temporal fusion at the image sequence level and shallow feature level, leading to the construction of two fused intermediate video domains. This prompts the video semantic segmentation model to consistently learn spatio-temporal features of shared patch sequences which are influenced by domain-specific contexts, thereby mitigating the feature gap between the source and target domain. Secondly, we propose a category-aware feature alignment module to promote the consistency of spatio-temporal features, facilitating adaptation to the target domain. Specifically, we adaptively aggregate the domain-specific deep features of each category along spatio-temporal dimensions, which are further constrained to achieve cross-domain intra-class feature alignment and inter-class feature separation. Extensive experiments demonstrate the effectiveness of our method, which achieves state-of-the-art mIOUs on multiple challenging benchmarks. Furthermore, we extend the proposed DA-STC to the image domain, where it also exhibits superior performance for domain adaptive semantic segmentation. The source code and models will be made available at \url{https://github.com/ZHE-SAPI/DA-STC}.