 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModularizing Deep Learning via Pairwise Learning With Kernels
Paper and Code
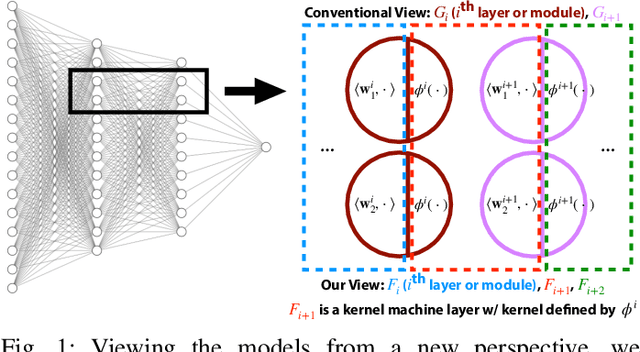
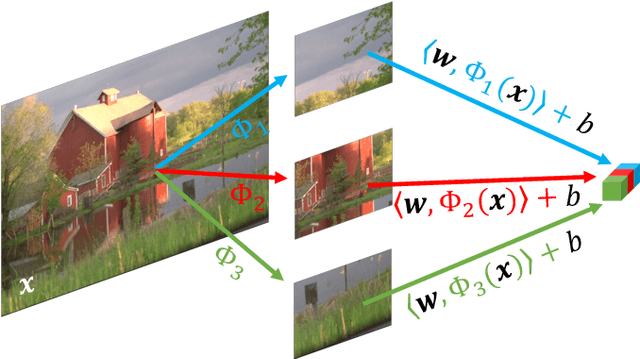
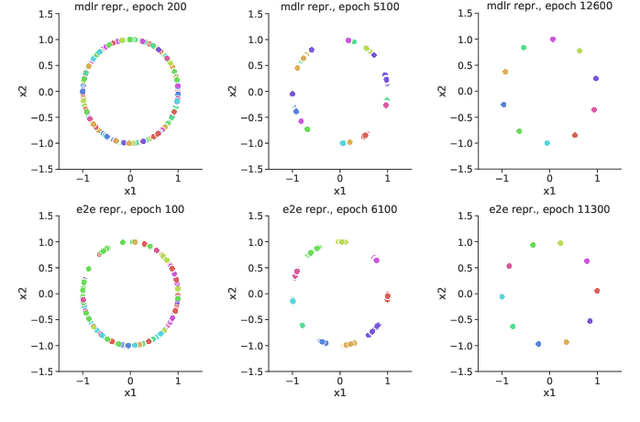
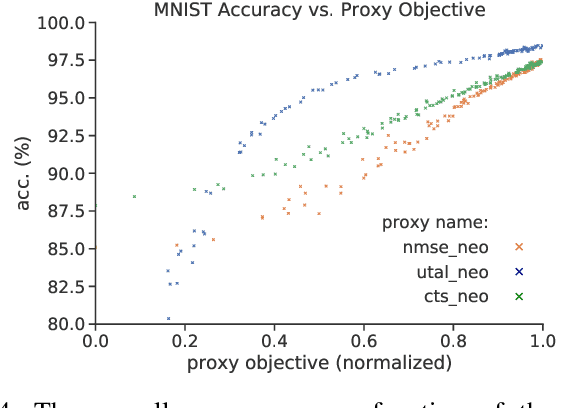
By redefining the conventional notions of layers, we present an alternative view on finitely wide, fully trainable deep neural networks as stacked linear models in feature spaces, leading to a kernel machine interpretation. Based on this construction, we then propose a provably optimal modular learning framework for classification, avoiding between-module backpropagation. This modular training approach brings new insights into the label requirement of deep learning: It leverages weak pairwise labels when learning the hidden modules. When training the output module, on the other hand, it requires full supervision but achieves high label efficiency, needing as few as 10 randomly selected labeled examples (one from each class) to achieve 94.88\% accuracy on CIFAR-10 using a ResNet-18 backbone. Moreover, modular training enables fully modularized deep learning workflows, which then simplify the design and implementation of pipelines and improve the maintainability and reusability of models. To showcase the advantages of such a modularized workflow, we describe a simple yet reliable method for estimating reusability of pre-trained modules as well as task transferability in a transfer learning setting. At practically no computation overhead, it precisely described the task space structure of 15 binary classification tasks from CIFAR-10.