 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalized, High-resolution Geographic Representations with Slepian Functions
Jan 30, 2026Geographic data is fundamentally local. Disease outbreaks cluster in population centers, ecological patterns emerge along coastlines, and economic activity concentrates within country borders. Machine learning models that encode geographic location, however, distribute representational capacity uniformly across the globe, struggling at the fine-grained resolutions that localized applications require. We propose a geographic location encoder built from spherical Slepian functions that concentrate representational capacity inside a region-of-interest and scale to high resolutions without extensive computational demands. For settings requiring global context, we present a hybrid Slepian-Spherical Harmonic encoder that efficiently bridges the tradeoff between local-global performance, while retaining desirable properties such as pole-safety and spherical-surface-distance preservation. Across five tasks spanning classification, regression, and image-augmented prediction, Slepian encodings outperform baselines and retain performance advantages across a wide range of neural network architectures.
Deep Pre-trained Time Series Features for Tree Species Classification in the Dutch Forest Inventory
Aug 26, 2025



National Forest Inventory (NFI)s serve as the primary source of forest information, providing crucial tree species distribution data. However, maintaining these inventories requires labor-intensive on-site campaigns. Remote sensing approaches, particularly when combined with machine learning, offer opportunities to update NFIs more frequently and at larger scales. While the use of Satellite Image Time Series has proven effective for distinguishing tree species through seasonal canopy reflectance patterns, current approaches rely primarily on Random Forest classifiers with hand-designed features and phenology-based metrics. Using deep features from an available pre-trained remote sensing foundation models offers a complementary strategy. These pre-trained models leverage unannotated global data and are meant to used for general-purpose applications and can then be efficiently fine-tuned with smaller labeled datasets for specific classification tasks. This work systematically investigates how deep features improve tree species classification accuracy in the Netherlands with few annotated data. Data-wise, we extracted time-series data from Sentinel-1, Sentinel-2 and ERA5 satellites data and SRTM data using Google Earth Engine. Our results demonstrate that fine-tuning a publicly available remote sensing time series foundation model outperforms the current state-of-the-art in NFI classification in the Netherlands by a large margin of up to 10% across all datasets. This demonstrates that classic hand-defined harmonic features are too simple for this task and highlights the potential of using deep AI features for data-limited application like NFI classification. By leveraging openly available satellite data and pre-trained models, this approach significantly improves classification accuracy compared to traditional methods and can effectively complement existing forest inventory processes.
AirCast: Improving Air Pollution Forecasting Through Multi-Variable Data Alignment
Feb 25, 2025Air pollution remains a leading global health risk, exacerbated by rapid industrialization and urbanization, contributing significantly to morbidity and mortality rates. In this paper, we introduce AirCast, a novel multi-variable air pollution forecasting model, by combining weather and air quality variables. AirCast employs a multi-task head architecture that simultaneously forecasts atmospheric conditions and pollutant concentrations, improving its understanding of how weather patterns affect air quality. Predicting extreme pollution events is challenging due to their rare occurrence in historic data, resulting in a heavy-tailed distribution of pollution levels. To address this, we propose a novel Frequency-weighted Mean Absolute Error (fMAE) loss, adapted from the class-balanced loss for regression tasks. Informed from domain knowledge, we investigate the selection of key variables known to influence pollution levels. Additionally, we align existing weather and chemical datasets across spatial and temporal dimensions. AirCast's integrated approach, combining multi-task learning, frequency weighted loss and domain informed variable selection, enables more accurate pollution forecasts. Our source code and models are made public here (https://github.com/vishalned/AirCast.git)
Imbalance-aware Presence-only Loss Function for Species Distribution Modeling
Mar 12, 2024

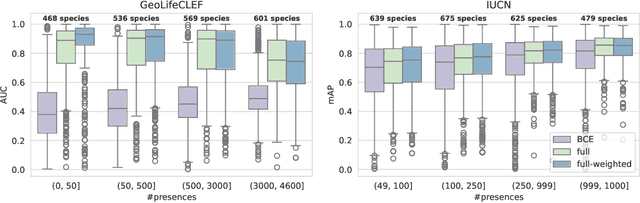

In the face of significant biodiversity decline, species distribution models (SDMs) are essential for understanding the impact of climate change on species habitats by connecting environmental conditions to species occurrences. Traditionally limited by a scarcity of species observations, these models have significantly improved in performance through the integration of larger datasets provided by citizen science initiatives. However, they still suffer from the strong class imbalance between species within these datasets, often resulting in the penalization of rare species--those most critical for conservation efforts. To tackle this issue, this study assesses the effectiveness of training deep learning models using a balanced presence-only loss function on large citizen science-based datasets. We demonstrate that this imbalance-aware loss function outperforms traditional loss functions across various datasets and tasks, particularly in accurately modeling rare species with limited observations.
Data-Centric Machine Learning for Geospatial Remote Sensing Data
Dec 08, 2023



Recent developments and research in modern machine learning have led to substantial improvements in the geospatial field. Although numerous deep learning models have been proposed, the majority of them have been developed on benchmark datasets that lack strong real-world relevance. Furthermore, the performance of many methods has already saturated on these datasets. We argue that shifting the focus towards a complementary data-centric perspective is necessary to achieve further improvements in accuracy, generalization ability, and real impact in end-user applications. This work presents a definition and precise categorization of automated data-centric learning approaches for geospatial data. It highlights the complementary role of data-centric learning with respect to model-centric in the larger machine learning deployment cycle. We review papers across the entire geospatial field and categorize them into different groups. A set of representative experiments shows concrete implementation examples. These examples provide concrete steps to act on geospatial data with data-centric machine learning approaches.
SatCLIP: Global, General-Purpose Location Embeddings with Satellite Imagery
Nov 30, 2023



Geographic location is essential for modeling tasks in fields ranging from ecology to epidemiology to the Earth system sciences. However, extracting relevant and meaningful characteristics of a location can be challenging, often entailing expensive data fusion or data distillation from global imagery datasets. To address this challenge, we introduce Satellite Contrastive Location-Image Pretraining (SatCLIP), a global, general-purpose geographic location encoder that learns an implicit representation of locations from openly available satellite imagery. Trained location encoders provide vector embeddings summarizing the characteristics of any given location for convenient usage in diverse downstream tasks. We show that SatCLIP embeddings, pretrained on globally sampled multi-spectral Sentinel-2 satellite data, can be used in various predictive tasks that depend on location information but not necessarily satellite imagery, including temperature prediction, animal recognition in imagery, and population density estimation. Across tasks, SatCLIP embeddings consistently outperform embeddings from existing pretrained location encoders, ranging from models trained on natural images to models trained on semantic context. SatCLIP embeddings also help to improve geographic generalization. This demonstrates the potential of general-purpose location encoders and opens the door to learning meaningful representations of our planet from the vast, varied, and largely untapped modalities of geospatial data.
Geographic Location Encoding with Spherical Harmonics and Sinusoidal Representation Networks
Oct 10, 2023



Learning feature representations of geographical space is vital for any machine learning model that integrates geolocated data, spanning application domains such as remote sensing, ecology, or epidemiology. Recent work mostly embeds coordinates using sine and cosine projections based on Double Fourier Sphere (DFS) features -- these embeddings assume a rectangular data domain even on global data, which can lead to artifacts, especially at the poles. At the same time, relatively little attention has been paid to the exact design of the neural network architectures these functional embeddings are combined with. This work proposes a novel location encoder for globally distributed geographic data that combines spherical harmonic basis functions, natively defined on spherical surfaces, with sinusoidal representation networks (SirenNets) that can be interpreted as learned Double Fourier Sphere embedding. We systematically evaluate the cross-product of positional embeddings and neural network architectures across various classification and regression benchmarks and synthetic evaluation datasets. In contrast to previous approaches that require the combination of both positional encoding and neural networks to learn meaningful representations, we show that both spherical harmonics and sinusoidal representation networks are competitive on their own but set state-of-the-art performances across tasks when combined. We provide source code at www.github.com/marccoru/locationencoder
Large-scale Detection of Marine Debris in Coastal Areas with Sentinel-2
Jul 05, 2023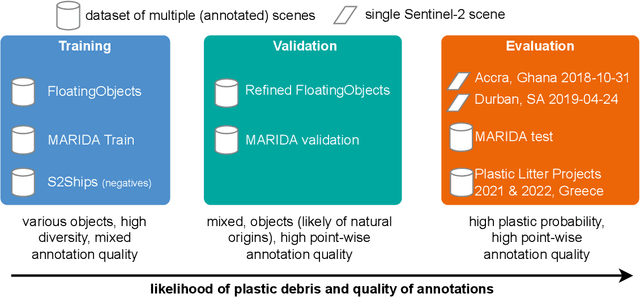
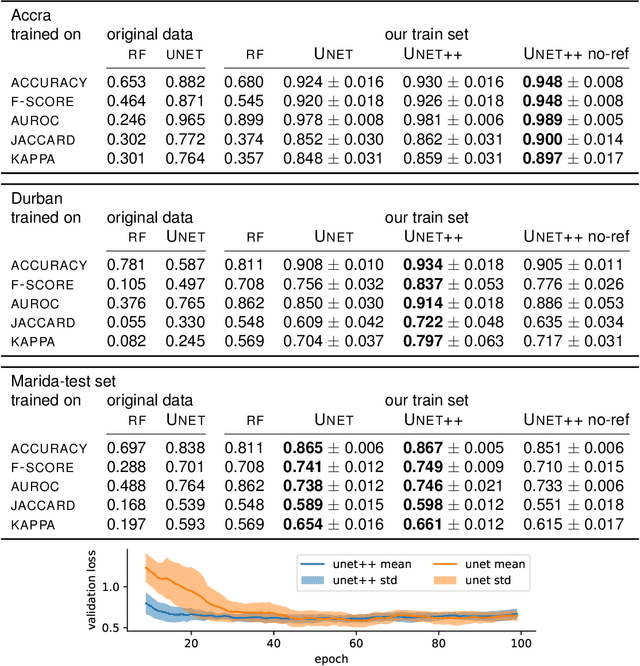
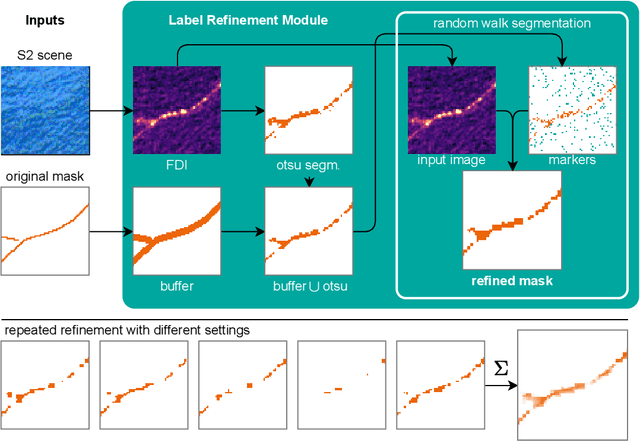

Detecting and quantifying marine pollution and macro-plastics is an increasingly pressing ecological issue that directly impacts ecology and human health. Efforts to quantify marine pollution are often conducted with sparse and expensive beach surveys, which are difficult to conduct on a large scale. Here, remote sensing can provide reliable estimates of plastic pollution by regularly monitoring and detecting marine debris in coastal areas. Medium-resolution satellite data of coastal areas is readily available and can be leveraged to detect aggregations of marine debris containing plastic litter. In this work, we present a detector for marine debris built on a deep segmentation model that outputs a probability for marine debris at the pixel level. We train this detector with a combination of annotated datasets of marine debris and evaluate it on specifically selected test sites where it is highly probable that plastic pollution is present in the detected marine debris. We demonstrate quantitatively and qualitatively that a deep learning model trained on this dataset issued from multiple sources outperforms existing detection models trained on previous datasets by a large margin. Our experiments show, consistent with the principles of data-centric AI, that this performance is due to our particular dataset design with extensive sampling of negative examples and label refinements rather than depending on the particular deep learning model. We hope to accelerate advances in the large-scale automated detection of marine debris, which is a step towards quantifying and monitoring marine litter with remote sensing at global scales, and release the model weights and training source code under https://github.com/marccoru/marinedebrisdetector
Meta-Learning for Few-Shot Land Cover Classification
Apr 28, 2020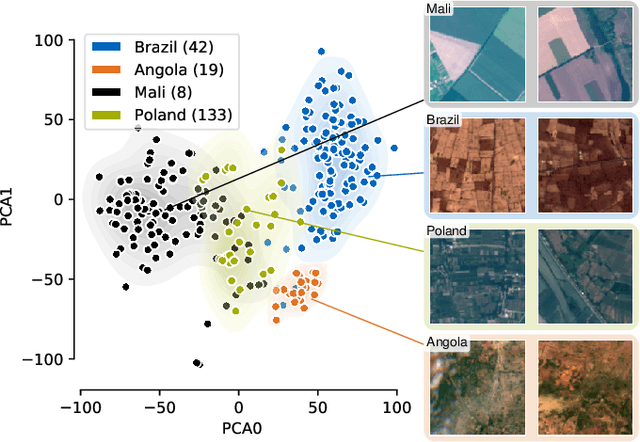
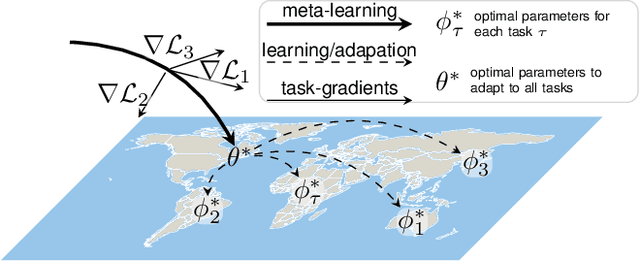
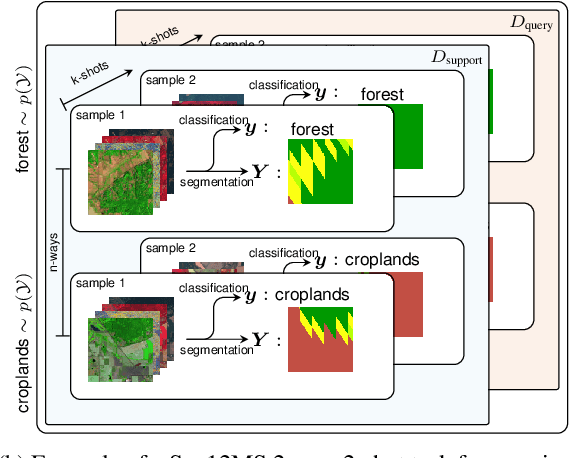
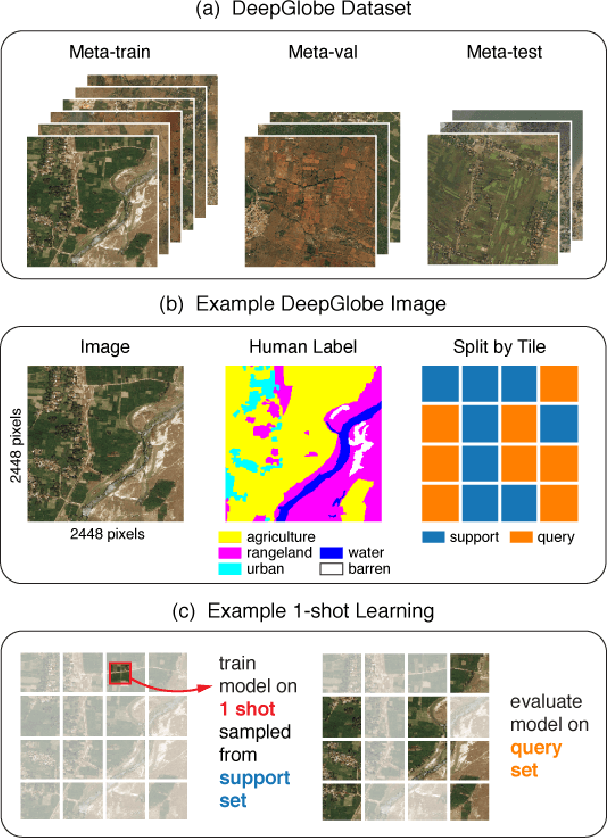
The representations of the Earth's surface vary from one geographic region to another. For instance, the appearance of urban areas differs between continents, and seasonality influences the appearance of vegetation. To capture the diversity within a single category, like as urban or vegetation, requires a large model capacity and, consequently, large datasets. In this work, we propose a different perspective and view this diversity as an inductive transfer learning problem where few data samples from one region allow a model to adapt to an unseen region. We evaluate the model-agnostic meta-learning (MAML) algorithm on classification and segmentation tasks using globally and regionally distributed datasets. We find that few-shot model adaptation outperforms pre-training with regular gradient descent and fine-tuning on (1) the Sen12MS dataset and (2) DeepGlobe data when the source domain and target domain differ. This indicates that model optimization with meta-learning may benefit tasks in the Earth sciences whose data show a high degree of diversity from region to region, while traditional gradient-based supervised learning remains suitable in the absence of a feature or label shift.
Self-Attention for Raw Optical Satellite Time Series Classification
Oct 23, 2019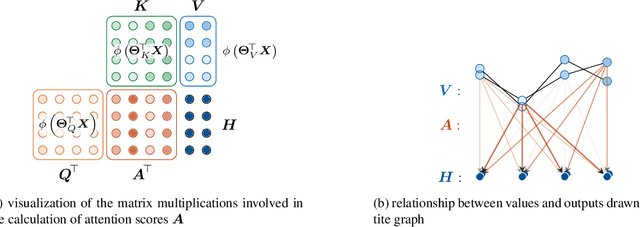
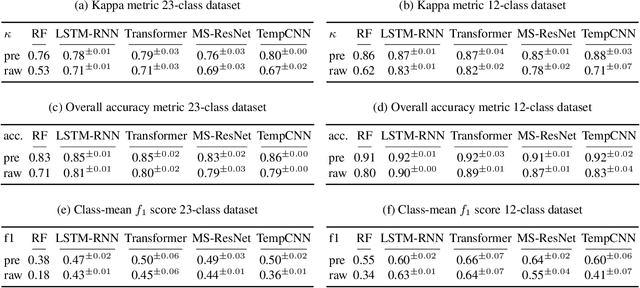
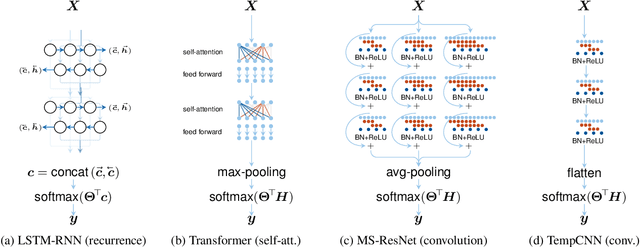
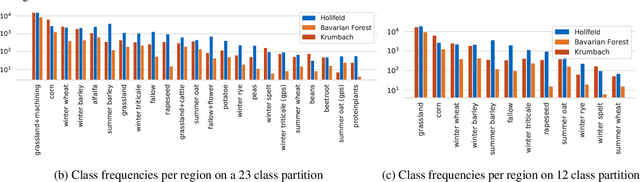
Deep learning methods have received increasing interest by the remote sensing community for multi-temporal land cover classification in recent years. Convolutional Neural networks that elementwise compare a time series with learned kernels, and recurrent neural networks that sequentially process temporal data have dominated the state-of-the-art in the classification of vegetation from satellite time series. Self-attention allows a neural network to selectively extract features from specific times in the input sequence thus suppressing non-classification relevant information. Today, self-attention based neural networks dominate the state-of-the-art in natural language processing but are hardly explored and tested in the remote sensing context. In this work, we embed self-attention in the canon of deep learning mechanisms for satellite time series classification for vegetation modeling and crop type identification. We compare it quantitatively to convolution, and recurrence and test four models that each exclusively relies on one of these mechanisms. The models are trained to identify the type of vegetation on crop parcels using raw and preprocessed Sentinel 2 time series over one entire year. To obtain an objective measure we find the best possible performance for each of the models by a large-scale hyperparameter search with more than 2400 validation runs. Beyond the quantitative comparison, we qualitatively analyze the models by an easy-to-implement, but yet effective feature importance analysis based on gradient back-propagation that exploits the differentiable nature of deep learning models. Finally, we look into the self-attention transformer model and visualize attention scores as bipartite graphs in the context of the input time series and a low-dimensional representation of internal hidden states using t-distributed stochastic neighborhood embedding (t-SNE).