 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn assessment of data-centric methods for label noise identification in remote sensing data sets
Mar 17, 2026Label noise in the sense of incorrect labels is present in many real-world data sets and is known to severely limit the generalizability of deep learning models. In the field of remote sensing, however, automated treatment of label noise in data sets has received little attention to date. In particular, there is a lack of systematic analysis of the performance of data-centric methods that not only cope with label noise but also explicitly identify and isolate noisy labels. In this paper, we examine three such methods and evaluate their behavior under different label noise assumptions. To do this, we inject different types of label noise with noise levels ranging from 10 to 70% into two benchmark data sets, followed by an analysis of how well the selected methods filter the label noise and how this affects task performances. With our analyses, we clearly prove the value of data-centric methods for both parts - label noise identification and task performance improvements. Our analyses provide insights into which method is the best choice depending on the setting and objective. Finally, we show in which areas there is still a need for research in the transfer of data-centric label noise methods to remote sensing data. As such, our work is a step forward in bridging the methodological establishment of data-centric label noise methods and their usage in practical settings in the remote sensing domain.
LC-SLab -- An Object-based Deep Learning Framework for Large-scale Land Cover Classification from Satellite Imagery and Sparse In-situ Labels
Sep 19, 2025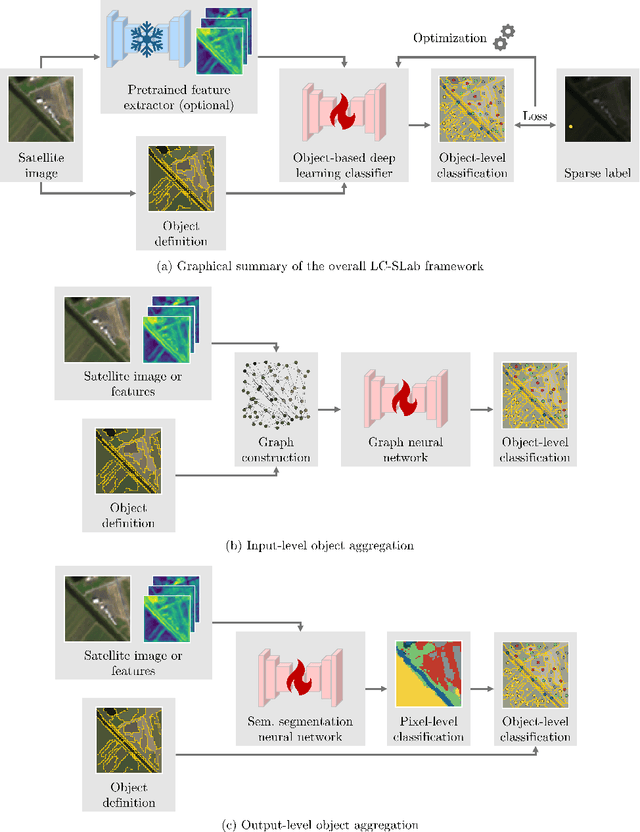
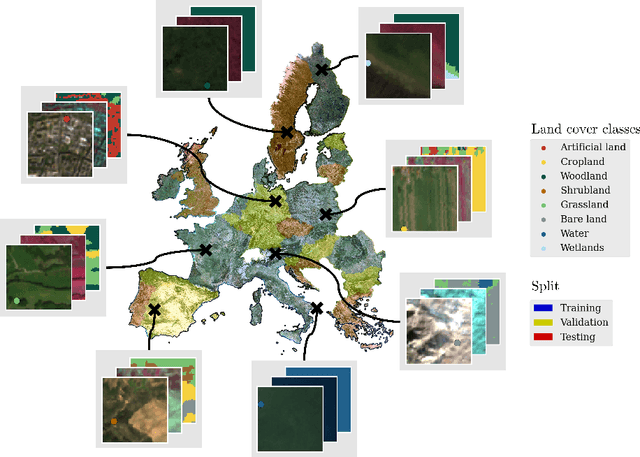
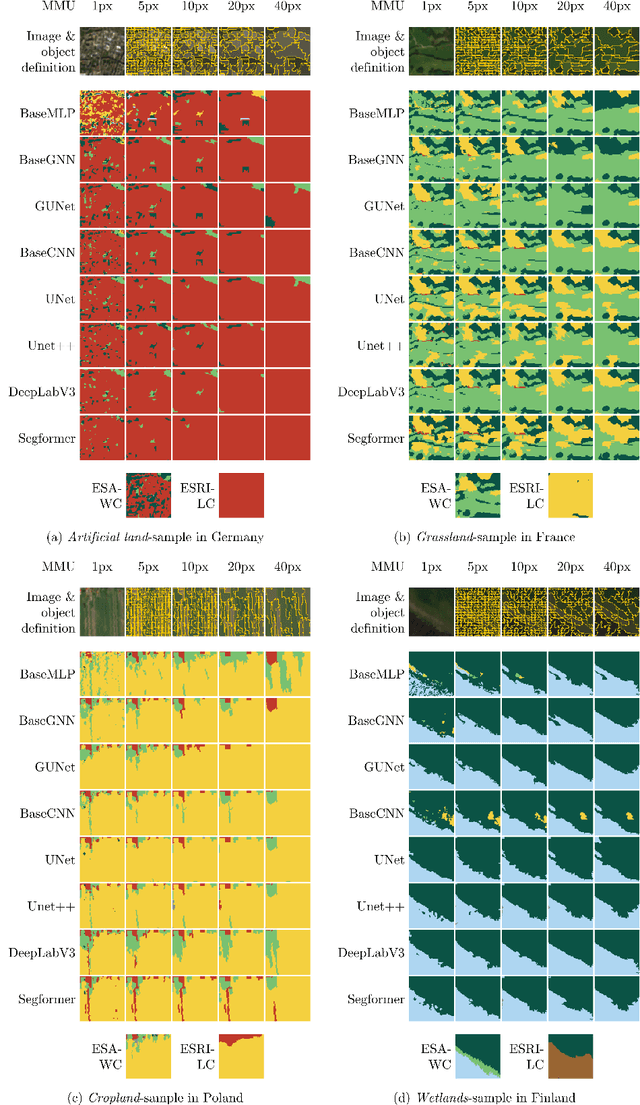
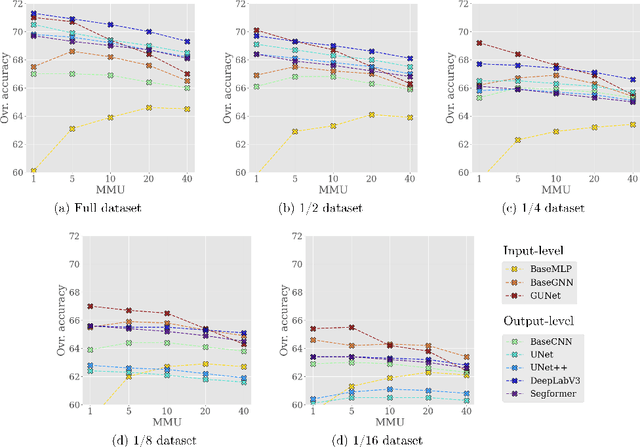
Large-scale land cover maps generated using deep learning play a critical role across a wide range of Earth science applications. Open in-situ datasets from principled land cover surveys offer a scalable alternative to manual annotation for training such models. However, their sparse spatial coverage often leads to fragmented and noisy predictions when used with existing deep learning-based land cover mapping approaches. A promising direction to address this issue is object-based classification, which assigns labels to semantically coherent image regions rather than individual pixels, thereby imposing a minimum mapping unit. Despite this potential, object-based methods remain underexplored in deep learning-based land cover mapping pipelines, especially in the context of medium-resolution imagery and sparse supervision. To address this gap, we propose LC-SLab, the first deep learning framework for systematically exploring object-based deep learning methods for large-scale land cover classification under sparse supervision. LC-SLab supports both input-level aggregation via graph neural networks, and output-level aggregation by postprocessing results from established semantic segmentation models. Additionally, we incorporate features from a large pre-trained network to improve performance on small datasets. We evaluate the framework on annual Sentinel-2 composites with sparse LUCAS labels, focusing on the tradeoff between accuracy and fragmentation, as well as sensitivity to dataset size. Our results show that object-based methods can match or exceed the accuracy of common pixel-wise models while producing substantially more coherent maps. Input-level aggregation proves more robust on smaller datasets, whereas output-level aggregation performs best with more data. Several configurations of LC-SLab also outperform existing land cover products, highlighting the framework's practical utility.
BuzzSet v1.0: A Dataset for Pollinator Detection in Field Conditions
Aug 27, 2025

Pollinator insects such as honeybees and bumblebees are vital to global food production and ecosystem stability, yet their populations are declining due to increasing anthropogenic and environmental stressors. To support scalable, automated pollinator monitoring, we introduce BuzzSet, a new large-scale dataset of high-resolution pollinator images collected in real agricultural field conditions. BuzzSet contains 7856 manually verified and labeled images, with over 8000 annotated instances across three classes: honeybees, bumblebees, and unidentified insects. Initial annotations were generated using a YOLOv12 model trained on external data and refined via human verification using open-source labeling tools. All images were preprocessed into 256~$\times$~256 tiles to improve the detection of small insects. We provide strong baselines using the RF-DETR transformer-based object detector. The model achieves high F1-scores of 0.94 and 0.92 for honeybee and bumblebee classes, respectively, with confusion matrix results showing minimal misclassification between these categories. The unidentified class remains more challenging due to label ambiguity and lower sample frequency, yet still contributes useful insights for robustness evaluation. Overall detection quality is strong, with a best mAP@0.50 of 0.559. BuzzSet offers a valuable benchmark for small object detection, class separation under label noise, and ecological computer vision.
Confidence-Filtered Relevance (CFR): An Interpretable and Uncertainty-Aware Machine Learning Framework for Naturalness Assessment in Satellite Imagery
Jul 17, 2025Protected natural areas play a vital role in ecological balance and ecosystem services. Monitoring these regions at scale using satellite imagery and machine learning is promising, but current methods often lack interpretability and uncertainty-awareness, and do not address how uncertainty affects naturalness assessment. In contrast, we propose Confidence-Filtered Relevance (CFR), a data-centric framework that combines LRP Attention Rollout with Deep Deterministic Uncertainty (DDU) estimation to analyze how model uncertainty influences the interpretability of relevance heatmaps. CFR partitions the dataset into subsets based on uncertainty thresholds, enabling systematic analysis of how uncertainty shapes the explanations of naturalness in satellite imagery. Applied to the AnthroProtect dataset, CFR assigned higher relevance to shrublands, forests, and wetlands, aligning with other research on naturalness assessment. Moreover, our analysis shows that as uncertainty increases, the interpretability of these relevance heatmaps declines and their entropy grows, indicating less selective and more ambiguous attributions. CFR provides a data-centric approach to assess the relevance of patterns to naturalness in satellite imagery based on their associated certainty.
Core-Set Selection for Data-efficient Land Cover Segmentation
May 02, 2025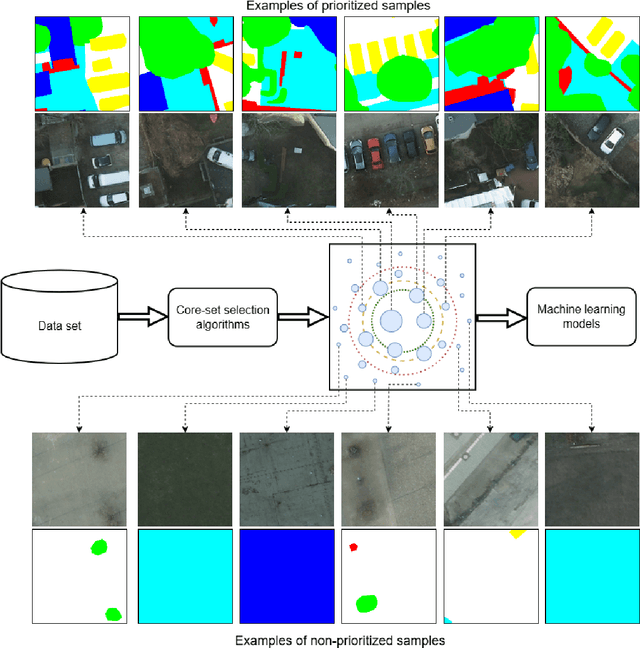


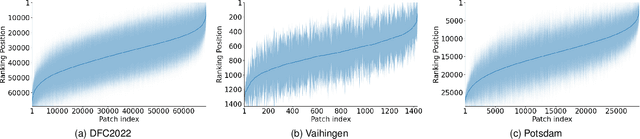
The increasing accessibility of remotely sensed data and the potential of such data to inform large-scale decision-making has driven the development of deep learning models for many Earth Observation tasks. Traditionally, such models must be trained on large datasets. However, the common assumption that broadly larger datasets lead to better outcomes tends to overlook the complexities of the data distribution, the potential for introducing biases and noise, and the computational resources required for processing and storing vast datasets. Therefore, effective solutions should consider both the quantity and quality of data. In this paper, we propose six novel core-set selection methods for selecting important subsets of samples from remote sensing image segmentation datasets that rely on imagery only, labels only, and a combination of each. We benchmark these approaches against a random-selection baseline on three commonly used land cover classification datasets: DFC2022, Vaihingen, and Potsdam. In each of the datasets, we demonstrate that training on a subset of samples outperforms the random baseline, and some approaches outperform training on all available data. This result shows the importance and potential of data-centric learning for the remote sensing domain. The code is available at https://github.com/keillernogueira/data-centric-rs-classification/.
Explainability of Sub-Field Level Crop Yield Prediction using Remote Sensing
Jul 11, 2024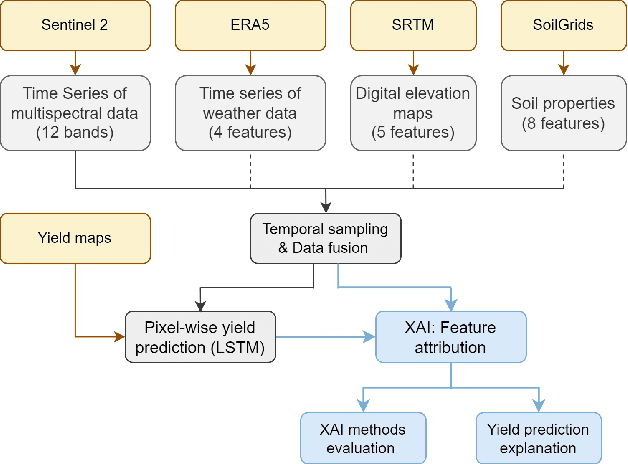
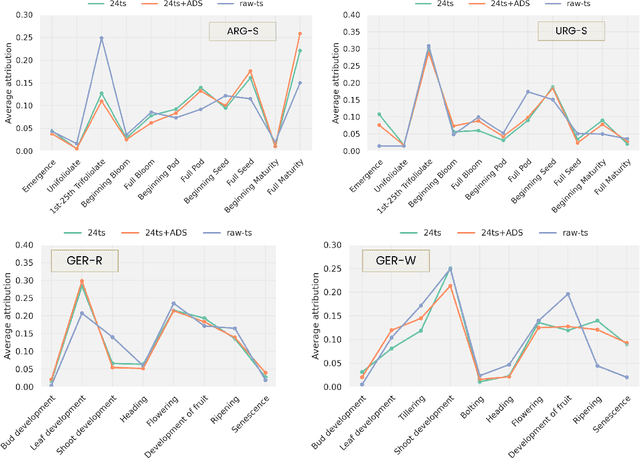
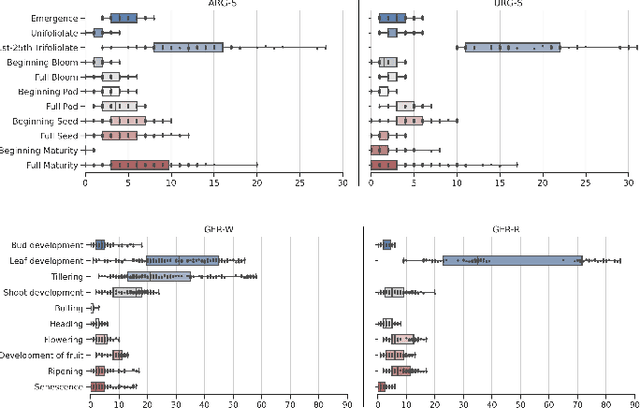
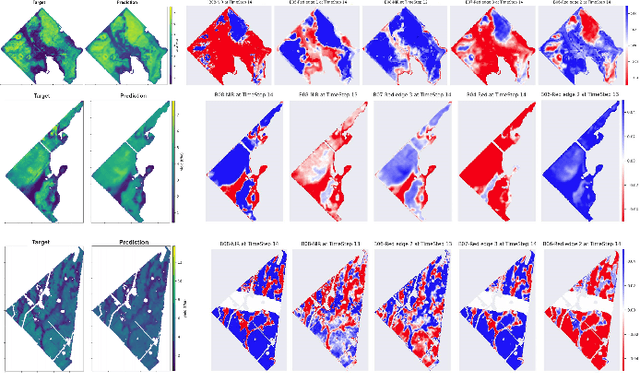
Crop yield forecasting plays a significant role in addressing growing concerns about food security and guiding decision-making for policymakers and farmers. When deep learning is employed, understanding the learning and decision-making processes of the models, as well as their interaction with the input data, is crucial for establishing trust in the models and gaining insight into their reliability. In this study, we focus on the task of crop yield prediction, specifically for soybean, wheat, and rapeseed crops in Argentina, Uruguay, and Germany. Our goal is to develop and explain predictive models for these crops, using a large dataset of satellite images, additional data modalities, and crop yield maps. We employ a long short-term memory network and investigate the impact of using different temporal samplings of the satellite data and the benefit of adding more relevant modalities. For model explainability, we utilize feature attribution methods to quantify input feature contributions, identify critical growth stages, analyze yield variability at the field level, and explain less accurate predictions. The modeling results show an improvement when adding more modalities or using all available instances of satellite data. The explainability results reveal distinct feature importance patterns for each crop and region. We further found that the most influential growth stages on the prediction are dependent on the temporal sampling of the input data. We demonstrated how these critical growth stages, which hold significant agronomic value, closely align with the existing literature in agronomy and crop development biology.
Data-Centric Machine Learning for Geospatial Remote Sensing Data
Dec 08, 2023



Recent developments and research in modern machine learning have led to substantial improvements in the geospatial field. Although numerous deep learning models have been proposed, the majority of them have been developed on benchmark datasets that lack strong real-world relevance. Furthermore, the performance of many methods has already saturated on these datasets. We argue that shifting the focus towards a complementary data-centric perspective is necessary to achieve further improvements in accuracy, generalization ability, and real impact in end-user applications. This work presents a definition and precise categorization of automated data-centric learning approaches for geospatial data. It highlights the complementary role of data-centric learning with respect to model-centric in the larger machine learning deployment cycle. We review papers across the entire geospatial field and categorize them into different groups. A set of representative experiments shows concrete implementation examples. These examples provide concrete steps to act on geospatial data with data-centric machine learning approaches.
Data-driven Crop Growth Simulation on Time-varying Generated Images using Multi-conditional Generative Adversarial Networks
Dec 06, 2023Image-based crop growth modeling can substantially contribute to precision agriculture by revealing spatial crop development over time, which allows an early and location-specific estimation of relevant future plant traits, such as leaf area or biomass. A prerequisite for realistic and sharp crop image generation is the integration of multiple growth-influencing conditions in a model, such as an image of an initial growth stage, the associated growth time, and further information about the field treatment. We present a two-stage framework consisting first of an image prediction model and second of a growth estimation model, which both are independently trained. The image prediction model is a conditional Wasserstein generative adversarial network (CWGAN). In the generator of this model, conditional batch normalization (CBN) is used to integrate different conditions along with the input image. This allows the model to generate time-varying artificial images dependent on multiple influencing factors of different kinds. These images are used by the second part of the framework for plant phenotyping by deriving plant-specific traits and comparing them with those of non-artificial (real) reference images. For various crop datasets, the framework allows realistic, sharp image predictions with a slight loss of quality from short-term to long-term predictions. Simulations of varying growth-influencing conditions performed with the trained framework provide valuable insights into how such factors relate to crop appearances, which is particularly useful in complex, less explored crop mixture systems. Further results show that adding process-based simulated biomass as a condition increases the accuracy of the derived phenotypic traits from the predicted images. This demonstrates the potential of our framework to serve as an interface between an image- and process-based crop growth model.
Data-Centric Digital Agriculture: A Perspective
Dec 06, 2023



In response to the increasing global demand for food, feed, fiber, and fuel, digital agriculture is rapidly evolving to meet these demands while reducing environmental impact. This evolution involves incorporating data science, machine learning, sensor technologies, robotics, and new management strategies to establish a more sustainable agricultural framework. So far, machine learning research in digital agriculture has predominantly focused on model-centric approaches, focusing on model design and evaluation. These efforts aim to optimize model accuracy and efficiency, often treating data as a static benchmark. Despite the availability of agricultural data and methodological advancements, a saturation point has been reached, with many established machine learning methods achieving comparable levels of accuracy and facing similar limitations. To fully realize the potential of digital agriculture, it is crucial to have a comprehensive understanding of the role of data in the field and to adopt data-centric machine learning. This involves developing strategies to acquire and curate valuable data and implementing effective learning and evaluation strategies that utilize the intrinsic value of data. This approach has the potential to create accurate, generalizable, and adaptable machine learning methods that effectively and sustainably address agricultural tasks such as yield prediction, weed detection, and early disease identification
Confident Naturalness Explanation (CNE): A Framework to Explain and Assess Patterns Forming Naturalness
Nov 22, 2023Protected natural areas are regions that have been minimally affected by human activities such as urbanization, agriculture, and other human interventions. To better understand and map the naturalness of these areas, machine learning models can be used to analyze satellite imagery. Specifically, explainable machine learning methods show promise in uncovering patterns that contribute to the concept of naturalness within these protected environments. Additionally, addressing the uncertainty inherent in machine learning models is crucial for a comprehensive understanding of this concept. However, existing approaches have limitations. They either fail to provide explanations that are both valid and objective or struggle to offer a quantitative metric that accurately measures the contribution of specific patterns to naturalness, along with the associated confidence. In this paper, we propose a novel framework called the Confident Naturalness Explanation (CNE) framework. This framework combines explainable machine learning and uncertainty quantification to assess and explain naturalness. We introduce a new quantitative metric that describes the confident contribution of patterns to the concept of naturalness. Furthermore, we generate an uncertainty-aware segmentation mask for each input sample, highlighting areas where the model lacks knowledge. To demonstrate the effectiveness of our framework, we apply it to a study site in Fennoscandia using two open-source satellite datasets.