 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic Explainability of Multimodal Learning for Crop Yield Prediction
Aug 09, 2025Multimodal learning enables various machine learning tasks to benefit from diverse data sources, effectively mimicking the interplay of different factors in real-world applications, particularly in agriculture. While the heterogeneous nature of involved data modalities may necessitate the design of complex architectures, the model interpretability is often overlooked. In this study, we leverage the intrinsic explainability of Transformer-based models to explain multimodal learning networks, focusing on the task of crop yield prediction at the subfield level. The large datasets used cover various crops, regions, and years, and include four different input modalities: multispectral satellite and weather time series, terrain elevation maps and soil properties. Based on the self-attention mechanism, we estimate feature attributions using two methods, namely the Attention Rollout (AR) and Generic Attention (GA), and evaluate their performance against Shapley-based model-agnostic estimations, Shapley Value Sampling (SVS). Additionally, we propose the Weighted Modality Activation (WMA) method to assess modality attributions and compare it with SVS attributions. Our findings indicate that Transformer-based models outperform other architectures, specifically convolutional and recurrent networks, achieving R2 scores that are higher by 0.10 and 0.04 at the subfield and field levels, respectively. AR is shown to provide more robust and reliable temporal attributions, as confirmed through qualitative and quantitative evaluation, compared to GA and SVS values. Information about crop phenology stages was leveraged to interpret the explanation results in the light of established agronomic knowledge. Furthermore, modality attributions revealed varying patterns across the two methods compared.[...]
Data-Centric Machine Learning for Earth Observation: Necessary and Sufficient Features
Aug 21, 2024The availability of temporal geospatial data in multiple modalities has been extensively leveraged to enhance the performance of machine learning models. While efforts on the design of adequate model architectures are approaching a level of saturation, focusing on a data-centric perspective can complement these efforts to achieve further enhancements in data usage efficiency and model generalization capacities. This work contributes to this direction. We leverage model explanation methods to identify the features crucial for the model to reach optimal performance and the smallest set of features sufficient to achieve this performance. We evaluate our approach on three temporal multimodal geospatial datasets and compare multiple model explanation techniques. Our results reveal that some datasets can reach their optimal accuracy with less than 20% of the temporal instances, while in other datasets, the time series of a single band from a single modality is sufficient.
XAI-Guided Enhancement of Vegetation Indices for Crop Mapping
Jul 11, 2024Vegetation indices allow to efficiently monitor vegetation growth and agricultural activities. Previous generations of satellites were capturing a limited number of spectral bands, and a few expert-designed vegetation indices were sufficient to harness their potential. New generations of multi- and hyperspectral satellites can however capture additional bands, but are not yet efficiently exploited. In this work, we propose an explainable-AI-based method to select and design suitable vegetation indices. We first train a deep neural network using multispectral satellite data, then extract feature importance to identify the most influential bands. We subsequently select suitable existing vegetation indices or modify them to incorporate the identified bands and retrain our model. We validate our approach on a crop classification task. Our results indicate that models trained on individual indices achieve comparable results to the baseline model trained on all bands, while the combination of two indices surpasses the baseline in certain cases.
Explainability of Sub-Field Level Crop Yield Prediction using Remote Sensing
Jul 11, 2024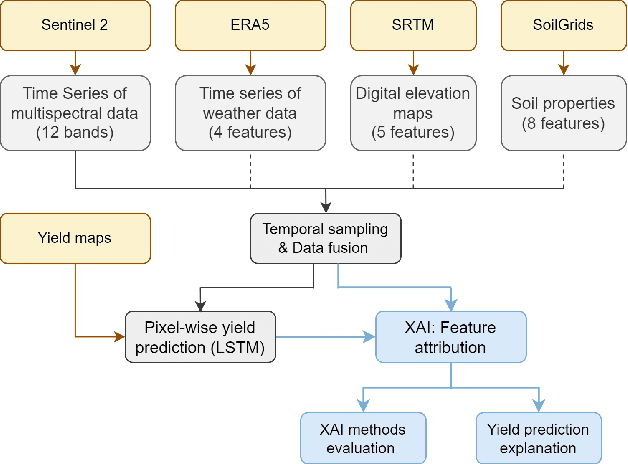
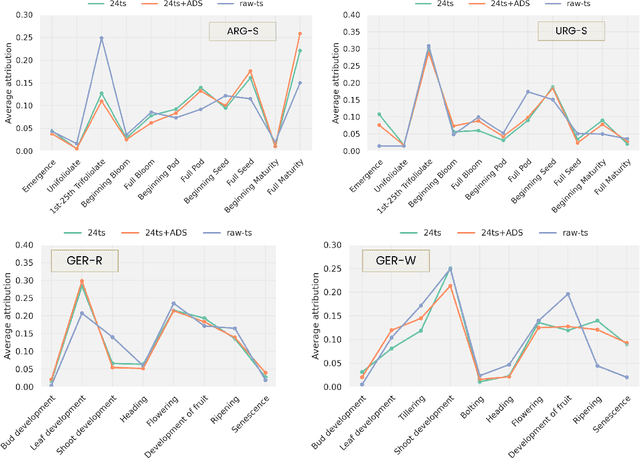
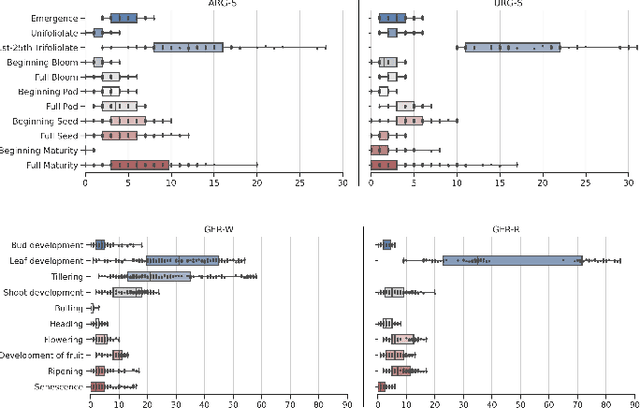
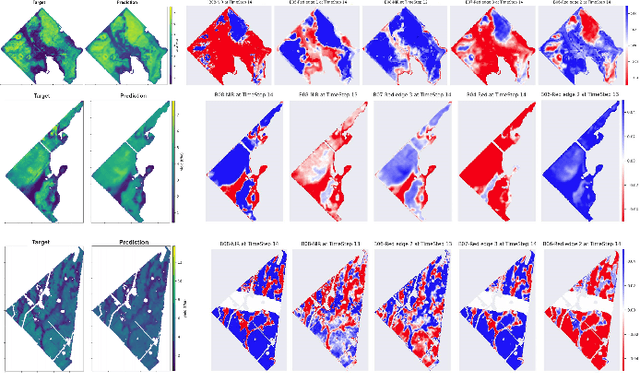
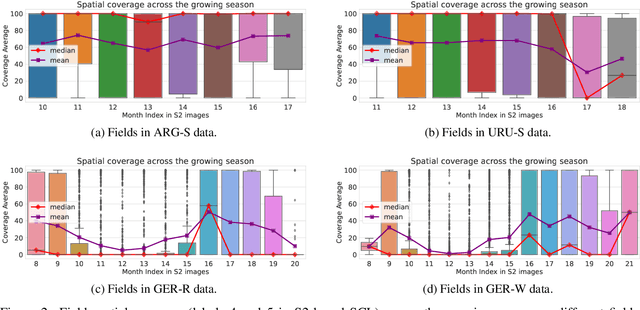
Crop yield forecasting plays a significant role in addressing growing concerns about food security and guiding decision-making for policymakers and farmers. When deep learning is employed, understanding the learning and decision-making processes of the models, as well as their interaction with the input data, is crucial for establishing trust in the models and gaining insight into their reliability. In this study, we focus on the task of crop yield prediction, specifically for soybean, wheat, and rapeseed crops in Argentina, Uruguay, and Germany. Our goal is to develop and explain predictive models for these crops, using a large dataset of satellite images, additional data modalities, and crop yield maps. We employ a long short-term memory network and investigate the impact of using different temporal samplings of the satellite data and the benefit of adding more relevant modalities. For model explainability, we utilize feature attribution methods to quantify input feature contributions, identify critical growth stages, analyze yield variability at the field level, and explain less accurate predictions. The modeling results show an improvement when adding more modalities or using all available instances of satellite data. The explainability results reveal distinct feature importance patterns for each crop and region. We further found that the most influential growth stages on the prediction are dependent on the temporal sampling of the input data. We demonstrated how these critical growth stages, which hold significant agronomic value, closely align with the existing literature in agronomy and crop development biology.
Qubit-efficient Variational Quantum Algorithms for Image Segmentation
May 23, 2024



Quantum computing is expected to transform a range of computational tasks beyond the reach of classical algorithms. In this work, we examine the application of variational quantum algorithms (VQAs) for unsupervised image segmentation to partition images into separate semantic regions. Specifically, we formulate the task as a graph cut optimization problem and employ two established qubit-efficient VQAs, which we refer to as Parametric Gate Encoding (PGE) and Ancilla Basis Encoding (ABE), to find the optimal segmentation mask. In addition, we propose Adaptive Cost Encoding (ACE), a new approach that leverages the same circuit architecture as ABE but adopts a problem-dependent cost function. We benchmark PGE, ABE and ACE on synthetically generated images, focusing on quality and trainability. ACE shows consistently faster convergence in training the parameterized quantum circuits in comparison to PGE and ABE. Furthermore, we provide a theoretical analysis of the scalability of these approaches against the Quantum Approximate Optimization Algorithm (QAOA), showing a significant cutback in the quantum resources, especially in the number of qubits that logarithmically depends on the number of pixels. The results validate the strengths of ACE, while concurrently highlighting its inherent limitations and challenges. This paves way for further research in quantum-enhanced computer vision.
Impact Assessment of Missing Data in Model Predictions for Earth Observation Applications
Mar 21, 2024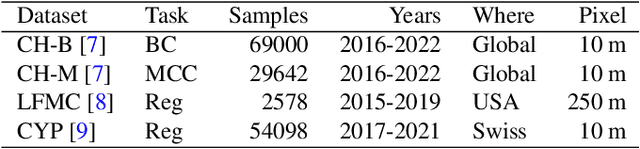
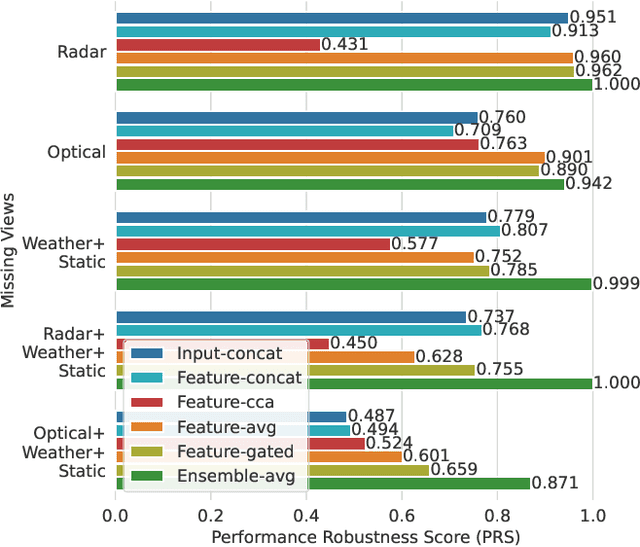

Earth observation (EO) applications involving complex and heterogeneous data sources are commonly approached with machine learning models. However, there is a common assumption that data sources will be persistently available. Different situations could affect the availability of EO sources, like noise, clouds, or satellite mission failures. In this work, we assess the impact of missing temporal and static EO sources in trained models across four datasets with classification and regression tasks. We compare the predictive quality of different methods and find that some are naturally more robust to missing data. The Ensemble strategy, in particular, achieves a prediction robustness up to 100%. We evidence that missing scenarios are significantly more challenging in regression than classification tasks. Finally, we find that the optical view is the most critical view when it is missing individually.
Adaptive Fusion of Multi-view Remote Sensing data for Optimal Sub-field Crop Yield Prediction
Jan 22, 2024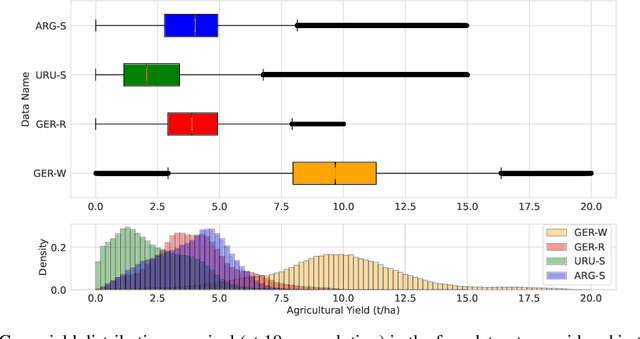


Accurate crop yield prediction is of utmost importance for informed decision-making in agriculture, aiding farmers, and industry stakeholders. However, this task is complex and depends on multiple factors, such as environmental conditions, soil properties, and management practices. Combining heterogeneous data views poses a fusion challenge, like identifying the view-specific contribution to the predictive task. We present a novel multi-view learning approach to predict crop yield for different crops (soybean, wheat, rapeseed) and regions (Argentina, Uruguay, and Germany). Our multi-view input data includes multi-spectral optical images from Sentinel-2 satellites and weather data as dynamic features during the crop growing season, complemented by static features like soil properties and topographic information. To effectively fuse the data, we introduce a Multi-view Gated Fusion (MVGF) model, comprising dedicated view-encoders and a Gated Unit (GU) module. The view-encoders handle the heterogeneity of data sources with varying temporal resolutions by learning a view-specific representation. These representations are adaptively fused via a weighted sum. The fusion weights are computed for each sample by the GU using a concatenation of the view-representations. The MVGF model is trained at sub-field level with 10 m resolution pixels. Our evaluations show that the MVGF outperforms conventional models on the same task, achieving the best results by incorporating all the data sources, unlike the usual fusion results in the literature. For Argentina, the MVGF model achieves an R2 value of 0.68 at sub-field yield prediction, while at field level evaluation (comparing field averages), it reaches around 0.80 across different countries. The GU module learned different weights based on the country and crop-type, aligning with the variable significance of each data source to the prediction task.
Q-Seg: Quantum Annealing-based Unsupervised Image Segmentation
Nov 30, 2023

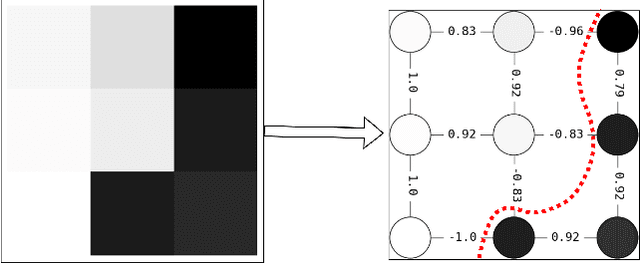
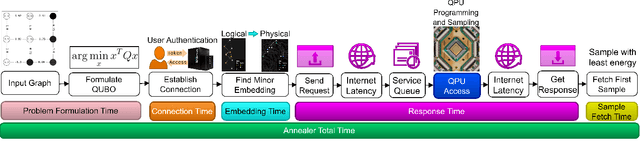
In this study, we present Q-Seg, a novel unsupervised image segmentation method based on quantum annealing, tailored for existing quantum hardware. We formulate the pixel-wise segmentation problem, which assimilates spectral and spatial information of the image, as a graph-cut optimization task. Our method efficiently leverages the interconnected qubit topology of the D-Wave Advantage device, offering superior scalability over existing quantum approaches and outperforming state-of-the-art classical methods. Our empirical evaluations on synthetic datasets reveal that Q-Seg offers better runtime performance against the classical optimizer Gurobi. Furthermore, we evaluate our method on segmentation of Earth Observation images, an area of application where the amount of labeled data is usually very limited. In this case, Q-Seg demonstrates near-optimal results in flood mapping detection with respect to classical supervised state-of-the-art machine learning methods. Also, Q-Seg provides enhanced segmentation for forest coverage compared to existing annotated masks. Thus, Q-Seg emerges as a viable alternative for real-world applications using available quantum hardware, particularly in scenarios where the lack of labeled data and computational runtime are critical.
Predicting Crop Yield With Machine Learning: An Extensive Analysis Of Input Modalities And Models On a Field and sub-field Level
Aug 17, 2023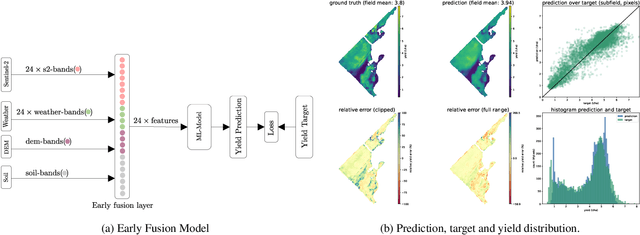
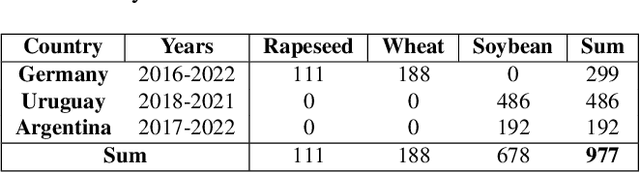
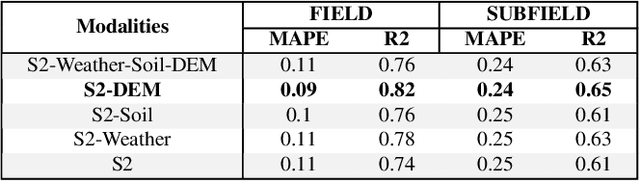
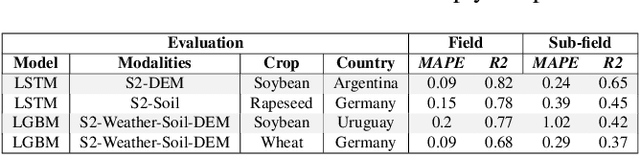
We introduce a simple yet effective early fusion method for crop yield prediction that handles multiple input modalities with different temporal and spatial resolutions. We use high-resolution crop yield maps as ground truth data to train crop and machine learning model agnostic methods at the sub-field level. We use Sentinel-2 satellite imagery as the primary modality for input data with other complementary modalities, including weather, soil, and DEM data. The proposed method uses input modalities available with global coverage, making the framework globally scalable. We explicitly highlight the importance of input modalities for crop yield prediction and emphasize that the best-performing combination of input modalities depends on region, crop, and chosen model.
A Comparative Assessment of Multi-view fusion learning for Crop Classification
Aug 10, 2023With a rapidly increasing amount and diversity of remote sensing (RS) data sources, there is a strong need for multi-view learning modeling. This is a complex task when considering the differences in resolution, magnitude, and noise of RS data. The typical approach for merging multiple RS sources has been input-level fusion, but other - more advanced - fusion strategies may outperform this traditional approach. This work assesses different fusion strategies for crop classification in the CropHarvest dataset. The fusion methods proposed in this work outperform models based on individual views and previous fusion methods. We do not find one single fusion method that consistently outperforms all other approaches. Instead, we present a comparison of multi-view fusion methods for three different datasets and show that, depending on the test region, different methods obtain the best performance. Despite this, we suggest a preliminary criterion for the selection of fusion methods.