 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCBEN -- A Multimodal Machine Learning Dataset for Cloud Robust Remote Sensing Image Understanding
Feb 13, 2026Clouds are a common phenomenon that distorts optical satellite imagery, which poses a challenge for remote sensing. However, in the literature cloudless analysis is often performed where cloudy images are excluded from machine learning datasets and methods. Such an approach cannot be applied to time sensitive applications, e.g., during natural disasters. A possible solution is to apply cloud removal as a preprocessing step to ensure that cloudfree solutions are not failing under such conditions. But cloud removal methods are still actively researched and suffer from drawbacks, such as generated visual artifacts. Therefore, it is desirable to develop cloud robust methods that are less affected by cloudy weather. Cloud robust methods can be achieved by combining optical data with radar, a modality unaffected by clouds. While many datasets for machine learning combine optical and radar data, most researchers exclude cloudy images. We identify this exclusion from machine learning training and evaluation as a limitation that reduces applicability to cloudy scenarios. To investigate this, we assembled a dataset, named CloudyBigEarthNet (CBEN), of paired optical and radar images with cloud occlusion for training and evaluation. Using average precision (AP) as the evaluation metric, we show that state-of-the-art methods trained on combined clear-sky optical and radar imagery suffer performance drops of 23-33 percentage points when evaluated on cloudy images. We then adapt these methods to cloudy optical data during training, achieving relative improvement of 17.2-28.7 percentage points on cloudy test cases compared with the original approaches. Code and dataset are publicly available at: https://github.com/mstricker13/CBEN
On the Importance of Feature Representation for Flood Mapping using Classical Machine Learning Approaches
Mar 01, 2023Climate change has increased the severity and frequency of weather disasters all around the world. Flood inundation mapping based on earth observation data can help in this context, by providing cheap and accurate maps depicting the area affected by a flood event to emergency-relief units in near-real-time. Building upon the recent development of the Sen1Floods11 dataset, which provides a limited amount of hand-labeled high-quality training data, this paper evaluates the potential of five traditional machine learning approaches such as gradient boosted decision trees, support vector machines or quadratic discriminant analysis. By performing a grid-search-based hyperparameter optimization on 23 feature spaces we can show that all considered classifiers are capable of outperforming the current state-of-the-art neural network-based approaches in terms of total IoU on their best-performing feature spaces. With total and mean IoU values of 0.8751 and 0.7031 compared to 0.70 and 0.5873 as the previous best-reported results, we show that a simple gradient boosting classifier can significantly improve over deep neural network based approaches, despite using less training data. Furthermore, an analysis of the regional distribution of the Sen1Floods11 dataset reveals a problem of spatial imbalance. We show that traditional machine learning models can learn this bias and argue that modified metric evaluations are required to counter artifacts due to spatial imbalance. Lastly, a qualitative analysis shows that this pixel-wise classifier provides highly-precise surface water classifications indicating that a good choice of a feature space and pixel-wise classification can generate high-quality flood maps using optical and SAR data. We make our code publicly available at: https://github.com/DFKI-Earth-And-Space-Applications/Flood_Mapping_Feature_Space_Importance
Facial Landmark Detection for Manga Images
Nov 08, 2018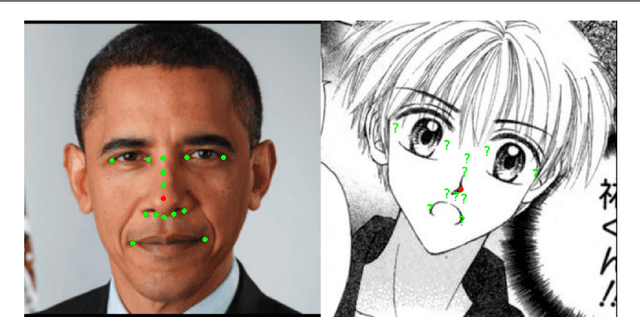



The topic of facial landmark detection has been widely covered for pictures of human faces, but it is still a challenge for drawings. Indeed, the proportions and symmetry of standard human faces are not always used for comics or mangas. The personal style of the author, the limitation of colors, etc. makes the landmark detection on faces in drawings a difficult task. Detecting the landmarks on manga images will be useful to provide new services for easily editing the character faces, estimating the character emotions, or generating automatically some animations such as lip or eye movements. This paper contains two main contributions: 1) a new landmark annotation model for manga faces, and 2) a deep learning approach to detect these landmarks. We use the "Deep Alignment Network", a multi stage architecture where the first stage makes an initial estimation which gets refined in further stages. The first results show that the proposed method succeed to accurately find the landmarks in more than 80% of the cases.