 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantitative knowledge retrieval from large language models
Feb 12, 2024Large language models (LLMs) have been extensively studied for their abilities to generate convincing natural language sequences, however their utility for quantitative information retrieval is less well understood. In this paper we explore the feasibility of LLMs as a mechanism for quantitative knowledge retrieval to aid data analysis tasks such as elicitation of prior distributions for Bayesian models and imputation of missing data. We present a prompt engineering framework, treating an LLM as an interface to a latent space of scientific literature, comparing responses in different contexts and domains against more established approaches. Implications and challenges of using LLMs as 'experts' are discussed.
Confidence-Aware Learning Assistant
Feb 15, 2021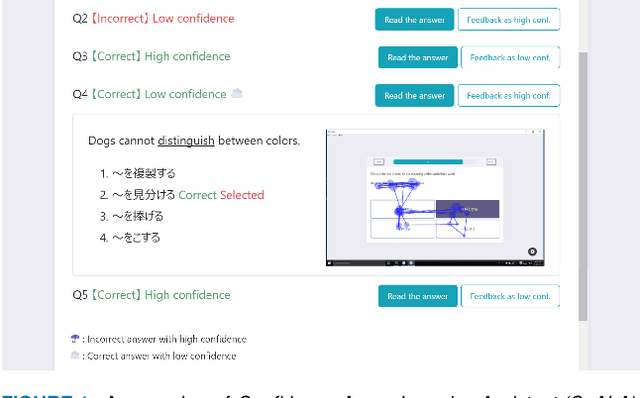


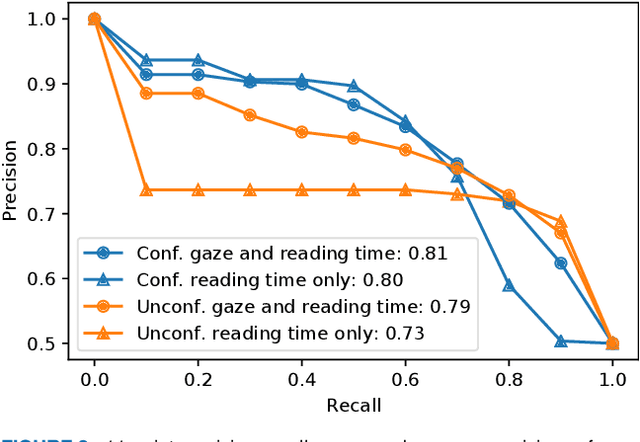
Not only correctness but also self-confidence play an important role in improving the quality of knowledge. Undesirable situations such as confident incorrect and unconfident correct knowledge prevent learners from revising their knowledge because it is not always easy for them to perceive the situations. To solve this problem, we propose a system that estimates self-confidence while solving multiple-choice questions by eye tracking and gives feedback about which question should be reviewed carefully. We report the results of three studies measuring its effectiveness. (1) On a well-controlled dataset with 10 participants, our approach detected confidence and unconfidence with 81% and 79% average precision. (2) With the help of 20 participants, we observed that correct answer rates of questions were increased by 14% and 17% by giving feedback about correct answers without confidence and incorrect answers with confidence, respectively. (3) We conducted a large-scale data recording in a private school (72 high school students solved 14,302 questions) to investigate effective features and the number of required training samples.
Distortion-Adaptive Grape Bunch Counting for Omnidirectional Images
Aug 28, 2020

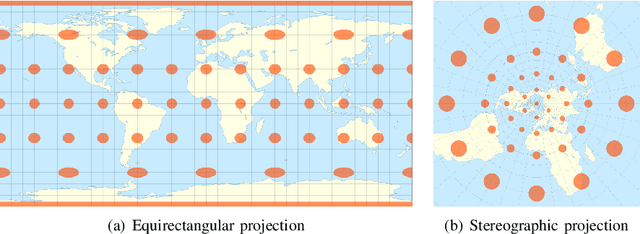
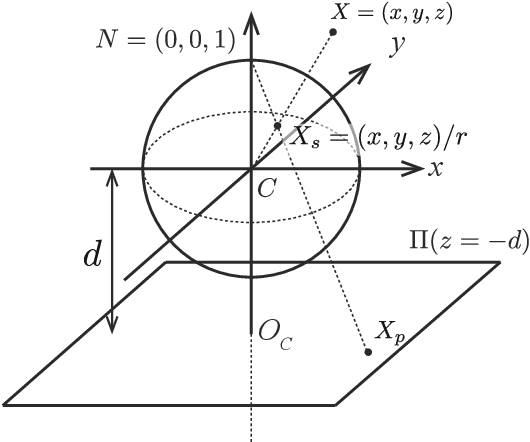
This paper proposes the first object counting method for omnidirectional images. Because conventional object counting methods cannot handle the distortion of omnidirectional images, we propose to process them using stereographic projection, which enables conventional methods to obtain a good approximation of the density function. However, the images obtained by stereographic projection are still distorted. Hence, to manage this distortion, we propose two methods. One is a new data augmentation method designed for the stereographic projection of omnidirectional images. The other is a distortion-adaptive Gaussian kernel that generates a density map ground truth while taking into account the distortion of stereographic projection. Using the counting of grape bunches as a case study, we constructed an original grape-bunch image dataset consisting of omnidirectional images and conducted experiments to evaluate the proposed method. The results show that the proposed method performs better than a direct application of the conventional method, improving mean absolute error by 14.7% and mean squared error by 10.5%.
Facial Landmark Detection for Manga Images
Nov 08, 2018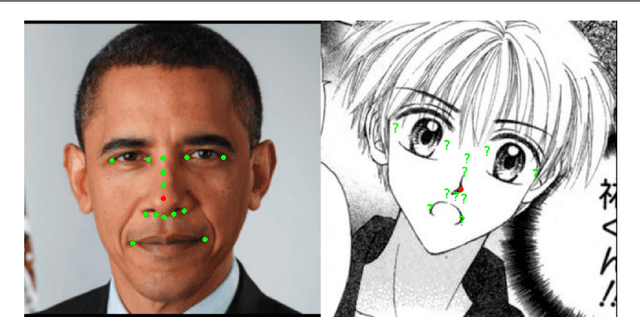



The topic of facial landmark detection has been widely covered for pictures of human faces, but it is still a challenge for drawings. Indeed, the proportions and symmetry of standard human faces are not always used for comics or mangas. The personal style of the author, the limitation of colors, etc. makes the landmark detection on faces in drawings a difficult task. Detecting the landmarks on manga images will be useful to provide new services for easily editing the character faces, estimating the character emotions, or generating automatically some animations such as lip or eye movements. This paper contains two main contributions: 1) a new landmark annotation model for manga faces, and 2) a deep learning approach to detect these landmarks. We use the "Deep Alignment Network", a multi stage architecture where the first stage makes an initial estimation which gets refined in further stages. The first results show that the proposed method succeed to accurately find the landmarks in more than 80% of the cases.
ShakeDrop regularization
Feb 07, 2018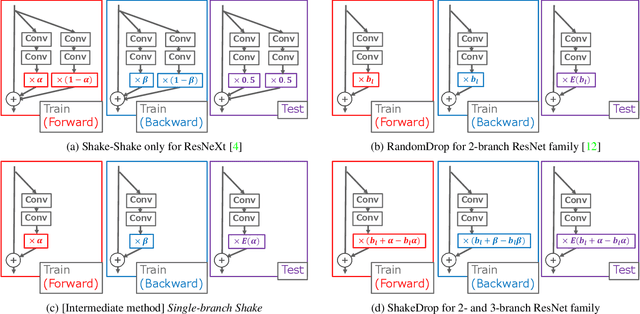
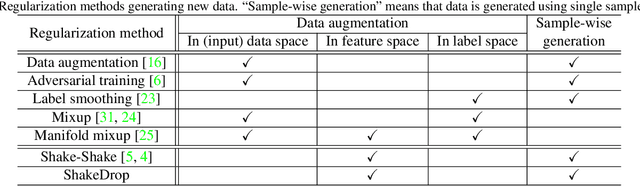
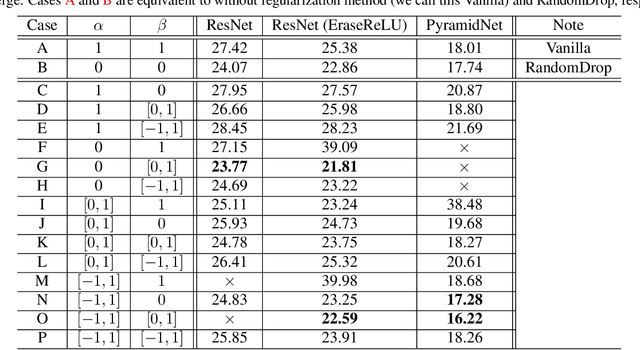
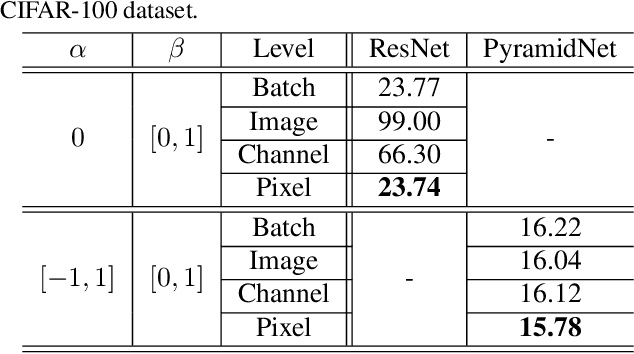
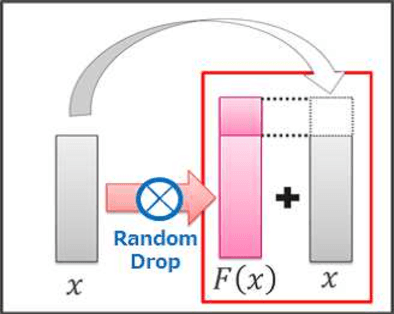
This paper proposes a powerful regularization method named ShakeDrop regularization. ShakeDrop is inspired by Shake-Shake regularization that decreases error rates by disturbing learning. While Shake-Shake can be applied to only ResNeXt which has multiple branches, ShakeDrop can be applied to not only ResNeXt but also ResNet, Wide ResNet and PyramidNet in a memory efficient way. Important and interesting feature of ShakeDrop is that it strongly disturbs learning by multiplying even a negative factor to the output of a convolutional layer in the forward training pass. The effectiveness of ShakeDrop is confirmed by experiments on CIFAR-10/100 and Tiny ImageNet datasets.
Automatic Generation of Typographic Font from a Small Font Subset
Jan 20, 2017
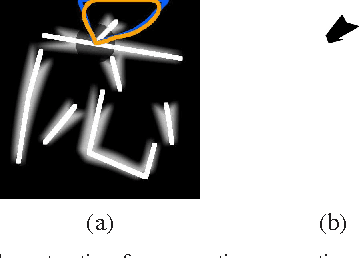
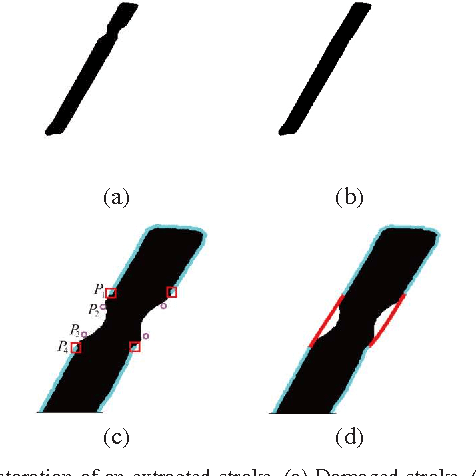
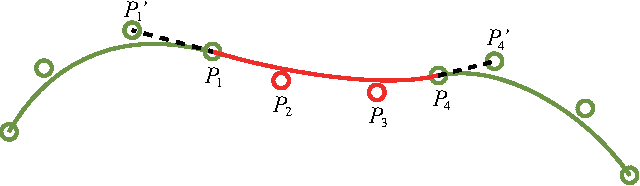
This paper addresses the automatic generation of a typographic font from a subset of characters. Specifically, we use a subset of a typographic font to extrapolate additional characters. Consequently, we obtain a complete font containing a number of characters sufficient for daily use. The automated generation of Japanese fonts is in high demand because a Japanese font requires over 1,000 characters. Unfortunately, professional typographers create most fonts, resulting in significant financial and time investments for font generation. The proposed method can be a great aid for font creation because designers do not need to create the majority of the characters for a new font. The proposed method uses strokes from given samples for font generation. The strokes, from which we construct characters, are extracted by exploiting a character skeleton dataset. This study makes three main contributions: a novel method of extracting strokes from characters, which is applicable to both standard fonts and their variations; a fully automated approach for constructing characters; and a selection method for sample characters. We demonstrate our proposed method by generating 2,965 characters in 47 fonts. Objective and subjective evaluations verify that the generated characters are similar to handmade characters.
Deep Pyramidal Residual Networks with Separated Stochastic Depth
Dec 05, 2016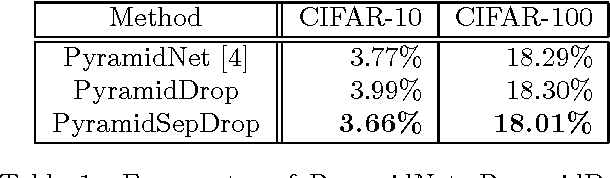


On general object recognition, Deep Convolutional Neural Networks (DCNNs) achieve high accuracy. In particular, ResNet and its improvements have broken the lowest error rate records. In this paper, we propose a method to successfully combine two ResNet improvements, ResDrop and PyramidNet. We confirmed that the proposed network outperformed the conventional methods; on CIFAR-100, the proposed network achieved an error rate of 16.18% in contrast to PiramidNet achieving that of 18.29% and ResNeXt 17.31%.
A Generic Method for Automatic Ground Truth Generation of Camera-captured Documents
May 04, 2016


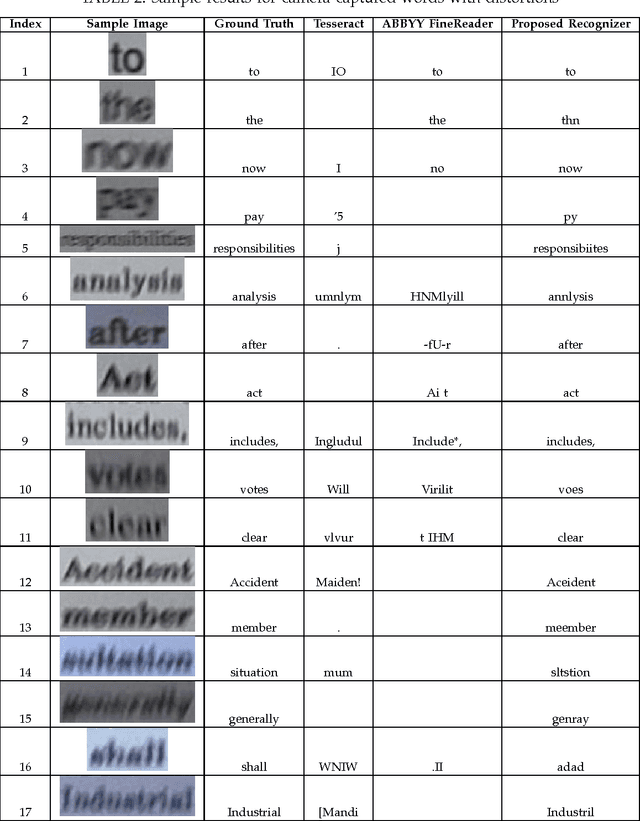
The contribution of this paper is fourfold. The first contribution is a novel, generic method for automatic ground truth generation of camera-captured document images (books, magazines, articles, invoices, etc.). It enables us to build large-scale (i.e., millions of images) labeled camera-captured/scanned documents datasets, without any human intervention. The method is generic, language independent and can be used for generation of labeled documents datasets (both scanned and cameracaptured) in any cursive and non-cursive language, e.g., English, Russian, Arabic, Urdu, etc. To assess the effectiveness of the presented method, two different datasets in English and Russian are generated using the presented method. Evaluation of samples from the two datasets shows that 99:98% of the images were correctly labeled. The second contribution is a large dataset (called C3Wi) of camera-captured characters and words images, comprising 1 million word images (10 million character images), captured in a real camera-based acquisition. This dataset can be used for training as well as testing of character recognition systems on camera-captured documents. The third contribution is a novel method for the recognition of cameracaptured document images. The proposed method is based on Long Short-Term Memory and outperforms the state-of-the-art methods for camera based OCRs. As a fourth contribution, various benchmark tests are performed to uncover the behavior of commercial (ABBYY), open source (Tesseract), and the presented camera-based OCR using the presented C3Wi dataset. Evaluation results reveal that the existing OCRs, which already get very high accuracies on scanned documents, have limited performance on camera-captured document images; where ABBYY has an accuracy of 75%, Tesseract an accuracy of 50.22%, while the presented character recognition system has an accuracy of 95.10%.
Scalable Solution for Approximate Nearest Subspace Search
Mar 29, 2016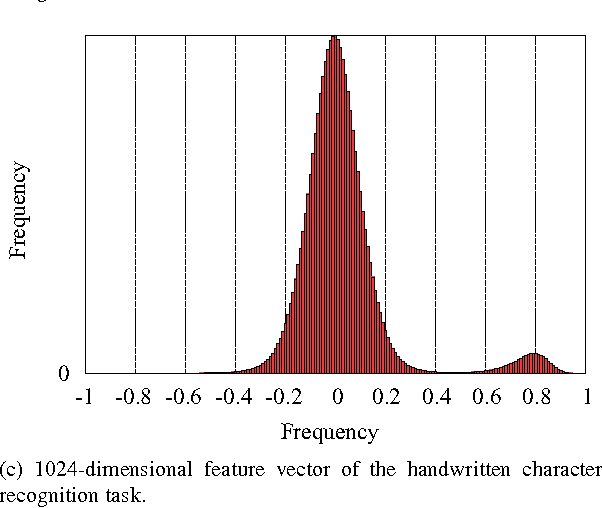
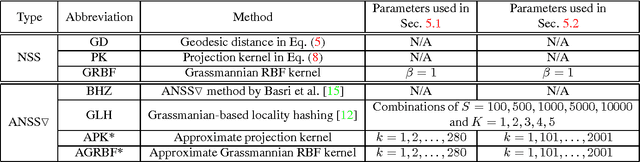


Finding the nearest subspace is a fundamental problem and influential to many applications. In particular, a scalable solution that is fast and accurate for a large problem has a great impact. The existing methods for the problem are, however, useless in a large-scale problem with a large number of subspaces and high dimensionality of the feature space. A cause is that they are designed based on the traditional idea to represent a subspace by a single point. In this paper, we propose a scalable solution for the approximate nearest subspace search (ANSS) problem. Intuitively, the proposed method represents a subspace by multiple points unlike the existing methods. This makes a large-scale ANSS problem tractable. In the experiment with 3036 subspaces in the 1024-dimensional space, we confirmed that the proposed method was 7.3 times faster than the previous state-of-the-art without loss of accuracy.