 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTFMN: Guided Texture and Feature Modulation Network for Low-Light Image Enhancement and Super-Resolution
Jan 27, 2026Low-light image super-resolution (LLSR) is a challenging task due to the coupled degradation of low resolution and poor illumination. To address this, we propose the Guided Texture and Feature Modulation Network (GTFMN), a novel framework that decouples the LLSR task into two sub-problems: illumination estimation and texture restoration. First, our network employs a dedicated Illumination Stream whose purpose is to predict a spatially varying illumination map that accurately captures lighting distribution. Further, this map is utilized as an explicit guide within our novel Illumination Guided Modulation Block (IGM Block) to dynamically modulate features in the Texture Stream. This mechanism achieves spatially adaptive restoration, enabling the network to intensify enhancement in poorly lit regions while preserving details in well-exposed areas. Extensive experiments demonstrate that GTFMN achieves the best performance among competing methods on the OmniNormal5 and OmniNormal15 datasets, outperforming them in both quantitative metrics and visual quality.
U-Harmony: Enhancing Joint Training for Segmentation Models with Universal Harmonization
Jan 21, 2026In clinical practice, medical segmentation datasets are often limited and heterogeneous, with variations in modalities, protocols, and anatomical targets across institutions. Existing deep learning models struggle to jointly learn from such diverse data, often sacrificing either generalization or domain-specific knowledge. To overcome these challenges, we propose a joint training method called Universal Harmonization (U-Harmony), which can be integrated into deep learning-based architectures with a domain-gated head, enabling a single segmentation model to learn from heterogeneous datasets simultaneously. By integrating U-Harmony, our approach sequentially normalizes and then denormalizes feature distributions to mitigate domain-specific variations while preserving original dataset-specific knowledge. More appealingly, our framework also supports universal modality adaptation, allowing the seamless learning of new imaging modalities and anatomical classes. Extensive experiments on cross-institutional brain lesion datasets demonstrate the effectiveness of our approach, establishing a new benchmark for robust and adaptable 3D medical image segmentation models in real-world clinical settings.
Breaking Dataset Boundaries: Class-Agnostic Targeted Adversarial Attacks
May 27, 2025We present Cross-Domain Multi-Targeted Attack (CD-MTA), a method for generating adversarial examples that mislead image classifiers toward any target class, including those not seen during training. Traditional targeted attacks are limited to one class per model, requiring expensive retraining for each target. Multi-targeted attacks address this by introducing a perturbation generator with a conditional input to specify the target class. However, existing methods are constrained to classes observed during training and require access to the black-box model's training data--introducing a form of data leakage that undermines realistic evaluation in practical black-box scenarios. We identify overreliance on class embeddings as a key limitation, leading to overfitting and poor generalization to unseen classes. To address this, CD-MTA replaces class-level supervision with an image-based conditional input and introduces class-agnostic losses that align the perturbed and target images in the feature space. This design removes dependence on class semantics, thereby enabling generalization to unseen classes across datasets. Experiments on ImageNet and seven other datasets show that CD-MTA outperforms prior multi-targeted attacks in both standard and cross-domain settings--without accessing the black-box model's training data.
Joint Low-level and High-level Textual Representation Learning with Multiple Masking Strategies
May 11, 2025Most existing text recognition methods are trained on large-scale synthetic datasets due to the scarcity of labeled real-world datasets. Synthetic images, however, cannot faithfully reproduce real-world scenarios, such as uneven illumination, irregular layout, occlusion, and degradation, resulting in performance disparities when handling complex real-world images. Recent self-supervised learning techniques, notably contrastive learning and masked image modeling (MIM), narrow this domain gap by exploiting unlabeled real text images. This study first analyzes the original Masked AutoEncoder (MAE) and observes that random patch masking predominantly captures low-level textural features but misses high-level contextual representations. To fully exploit the high-level contextual representations, we introduce random blockwise and span masking in the text recognition task. These strategies can mask the continuous image patches and completely remove some characters, forcing the model to infer relationships among characters within a word. Our Multi-Masking Strategy (MMS) integrates random patch, blockwise, and span masking into the MIM frame, which jointly learns low and high-level textual representations. After fine-tuning with real data, MMS outperforms the state-of-the-art self-supervised methods in various text-related tasks, including text recognition, segmentation, and text-image super-resolution.
Controlling Rate, Distortion, and Realism: Towards a Single Comprehensive Neural Image Compression Model
May 27, 2024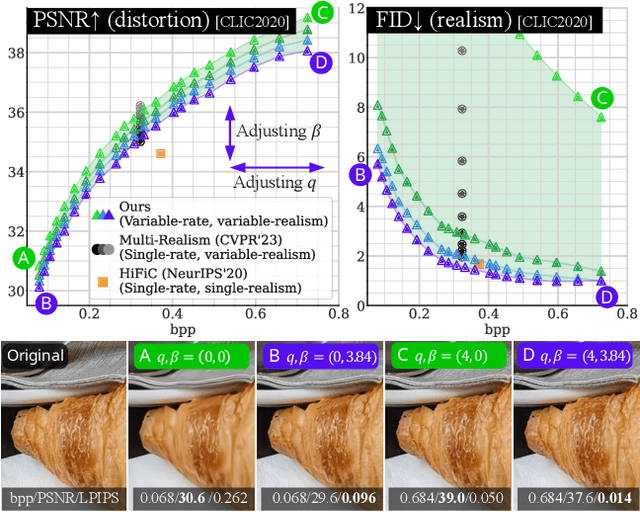

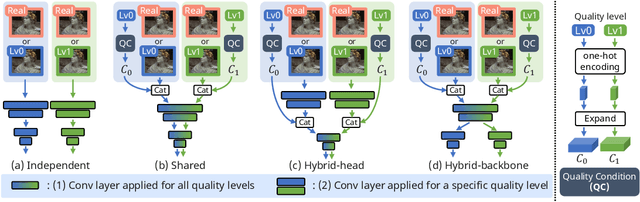
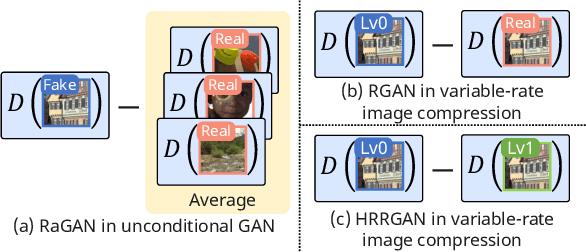
In recent years, neural network-driven image compression (NIC) has gained significant attention. Some works adopt deep generative models such as GANs and diffusion models to enhance perceptual quality (realism). A critical obstacle of these generative NIC methods is that each model is optimized for a single bit rate. Consequently, multiple models are required to compress images to different bit rates, which is impractical for real-world applications. To tackle this issue, we propose a variable-rate generative NIC model. Specifically, we explore several discriminator designs tailored for the variable-rate approach and introduce a novel adversarial loss. Moreover, by incorporating the newly proposed multi-realism technique, our method allows the users to adjust the bit rate, distortion, and realism with a single model, achieving ultra-controllability. Unlike existing variable-rate generative NIC models, our method matches or surpasses the performance of state-of-the-art single-rate generative NIC models while covering a wide range of bit rates using just one model. Code will be available at https://github.com/iwa-shi/CRDR
IRSRMamba: Infrared Image Super-Resolution via Mamba-based Wavelet Transform Feature Modulation Model
May 16, 2024



Infrared (IR) image super-resolution faces challenges from homogeneous background pixel distributions and sparse target regions, requiring models that effectively handle long-range dependencies and capture detailed local-global information. Recent advancements in Mamba-based (Selective Structured State Space Model) models, employing state space models, have shown significant potential in visual tasks, suggesting their applicability for IR enhancement. In this work, we introduce IRSRMamba: Infrared Image Super-Resolution via Mamba-based Wavelet Transform Feature Modulation Model, a novel Mamba-based model designed specifically for IR image super-resolution. This model enhances the restoration of context-sparse target details through its advanced dependency modeling capabilities. Additionally, a new wavelet transform feature modulation block improves multi-scale receptive field representation, capturing both global and local information efficiently. Comprehensive evaluations confirm that IRSRMamba outperforms existing models on multiple benchmarks. This research advances IR super-resolution and demonstrates the potential of Mamba-based models in IR image processing. Code are available at \url{https://github.com/yongsongH/IRSRMamba}.
Learn From Orientation Prior for Radiograph Super-Resolution: Orientation Operator Transformer
Dec 27, 2023



Background and objective: High-resolution radiographic images play a pivotal role in the early diagnosis and treatment of skeletal muscle-related diseases. It is promising to enhance image quality by introducing single-image super-resolution (SISR) model into the radiology image field. However, the conventional image pipeline, which can learn a mixed mapping between SR and denoising from the color space and inter-pixel patterns, poses a particular challenge for radiographic images with limited pattern features. To address this issue, this paper introduces a novel approach: Orientation Operator Transformer - $O^{2}$former. Methods: We incorporate an orientation operator in the encoder to enhance sensitivity to denoising mapping and to integrate orientation prior. Furthermore, we propose a multi-scale feature fusion strategy to amalgamate features captured by different receptive fields with the directional prior, thereby providing a more effective latent representation for the decoder. Based on these innovative components, we propose a transformer-based SISR model, i.e., $O^{2}$former, specifically designed for radiographic images. Results: The experimental results demonstrate that our method achieves the best or second-best performance in the objective metrics compared with the competitors at $\times 4$ upsampling factor. For qualitative, more objective details are observed to be recovered. Conclusions: In this study, we propose a novel framework called $O^{2}$former for radiological image super-resolution tasks, which improves the reconstruction model's performance by introducing an orientation operator and multi-scale feature fusion strategy. Our approach is promising to further promote the radiographic image enhancement field.
Target-oriented Domain Adaptation for Infrared Image Super-Resolution
Nov 15, 2023



Recent efforts have explored leveraging visible light images to enrich texture details in infrared (IR) super-resolution. However, this direct adaptation approach often becomes a double-edged sword, as it improves texture at the cost of introducing noise and blurring artifacts. To address these challenges, we propose the Target-oriented Domain Adaptation SRGAN (DASRGAN), an innovative framework specifically engineered for robust IR super-resolution model adaptation. DASRGAN operates on the synergy of two key components: 1) Texture-Oriented Adaptation (TOA) to refine texture details meticulously, and 2) Noise-Oriented Adaptation (NOA), dedicated to minimizing noise transfer. Specifically, TOA uniquely integrates a specialized discriminator, incorporating a prior extraction branch, and employs a Sobel-guided adversarial loss to align texture distributions effectively. Concurrently, NOA utilizes a noise adversarial loss to distinctly separate the generative and Gaussian noise pattern distributions during adversarial training. Our extensive experiments confirm DASRGAN's superiority. Comparative analyses against leading methods across multiple benchmarks and upsampling factors reveal that DASRGAN sets new state-of-the-art performance standards. Code are available at \url{https://github.com/yongsongH/DASRGAN}.
Deep Image Compression Using Scene Text Quality Assessment
May 19, 2023

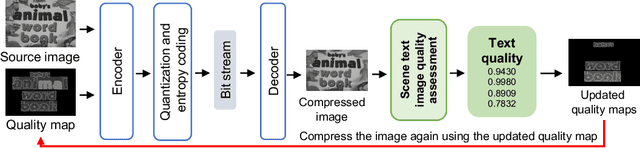

Image compression is a fundamental technology for Internet communication engineering. However, a high compression rate with general methods may degrade images, resulting in unreadable texts. In this paper, we propose an image compression method for maintaining text quality. We developed a scene text image quality assessment model to assess text quality in compressed images. The assessment model iteratively searches for the best-compressed image holding high-quality text. Objective and subjective results showed that the proposed method was superior to existing methods. Furthermore, the proposed assessment model outperformed other deep-learning regression models.
Infrared Image Super-Resolution: Systematic Review, and Future Trends
Dec 22, 2022



Image Super-Resolution (SR) is essential for a wide range of computer vision and image processing tasks. Investigating infrared (IR) image (or thermal images) super-resolution is a continuing concern within the development of deep learning. This survey aims to provide a comprehensive perspective of IR image super-resolution, including its applications, hardware imaging system dilemmas, and taxonomy of image processing methodologies. In addition, the datasets and evaluation metrics in IR image super-resolution tasks are also discussed. Furthermore, the deficiencies in current technologies and possible promising directions for the community to explore are highlighted. To cope with the rapid development in this field, we intend to regularly update the relevant excellent work at \url{https://github.com/yongsongH/Infrared_Image_SR_Survey