 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStroke-Based Scene Text Erasing Using Synthetic Data
Apr 23, 2021



Scene text erasing, which replaces text regions with reasonable content in natural images, has drawn attention in the computer vision community in recent years. There are two potential subtasks in scene text erasing: text detection and image inpainting. Either sub-task requires considerable data to achieve better performance; however, the lack of a large-scale real-world scene-text removal dataset allows the existing methods to not work in full strength. To avoid the limitation of the lack of pairwise real-world data, we enhance and make full use of the synthetic text and consequently train our model only on the dataset generated by the improved synthetic text engine. Our proposed network contains a stroke mask prediction module and background inpainting module that can extract the text stroke as a relatively small hole from the text image patch to maintain more background content for better inpainting results. This model can partially erase text instances in a scene image with a bounding box provided or work with an existing scene text detector for automatic scene text erasing. The experimental results of qualitative evaluation and quantitative evaluation on the SCUT-Syn, ICDAR2013, and SCUT-EnsText datasets demonstrate that our method significantly outperforms existing state-of-the-art methods even when trained on real-world data.
Fidelity-Controllable Extreme Image Compression with Generative Adversarial Networks
Aug 24, 2020
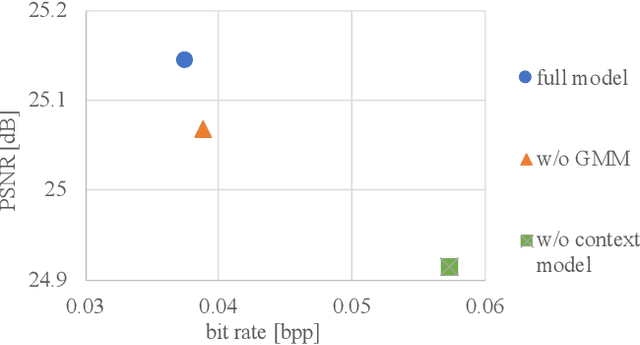

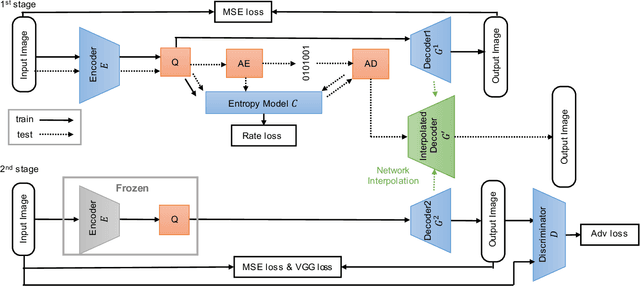
We propose a GAN-based image compression method working at extremely low bitrates below 0.1bpp. Most existing learned image compression methods suffer from blur at extremely low bitrates. Although GAN can help to reconstruct sharp images, there are two drawbacks. First, GAN makes training unstable. Second, the reconstructions often contain unpleasing noise or artifacts. To address both of the drawbacks, our method adopts two-stage training and network interpolation. The two-stage training is effective to stabilize the training. Moreover, the network interpolation utilizes the models in both stages and reduces undesirable noise and artifacts, while maintaining important edges. Hence, we can control the trade-off between perceptual quality and fidelity without re-training models. The experimental results show that our model can reconstruct high quality images. Furthermore, our user study confirms that our reconstructions are preferable to state-of-the-art GAN-based image compression model. The code will be available.
Multiple Visual-Semantic Embedding for Video Retrieval from Query Sentence
Apr 16, 2020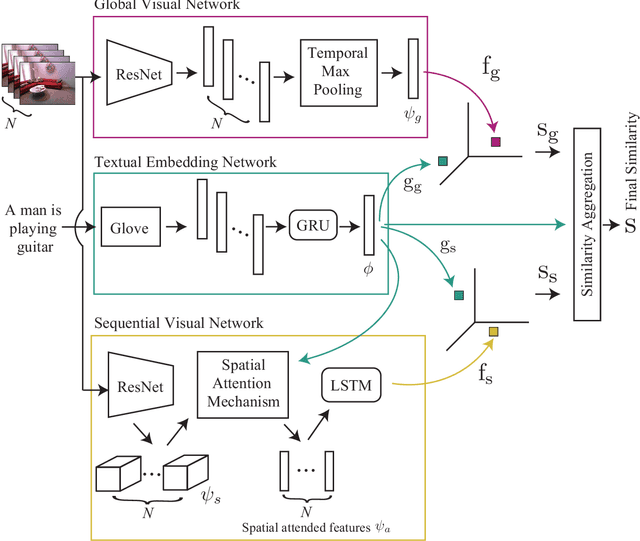
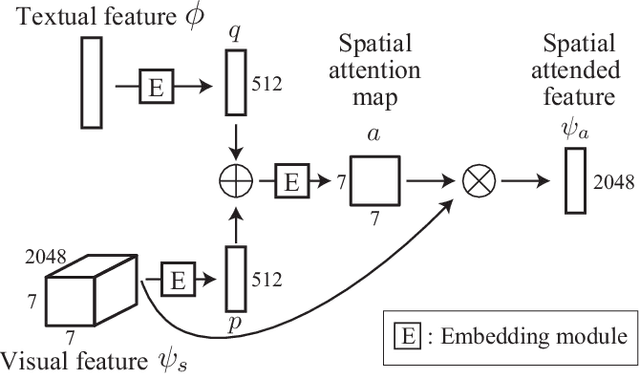
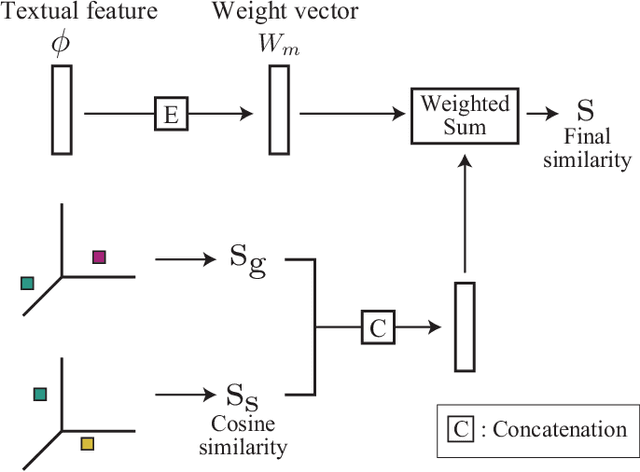
Visual-semantic embedding aims to learn a joint embedding space where related video and sentence instances are located close to each other. Most existing methods put instances in a single embedding space. However, they struggle to embed instances due to the difficulty of matching visual dynamics in videos to textual features in sentences. A single space is not enough to accommodate various videos and sentences. In this paper, we propose a novel framework that maps instances into multiple individual embedding spaces so that we can capture multiple relationships between instances, leading to compelling video retrieval. We propose to produce a final similarity between instances by fusing similarities measured in each embedding space using a weighted sum strategy. We determine the weights according to a sentence. Therefore, we can flexibly emphasize an embedding space. We conducted sentence-to-video retrieval experiments on a benchmark dataset. The proposed method achieved superior performance, and the results are competitive to state-of-the-art methods. These experimental results demonstrated the effectiveness of the proposed multiple embedding approach compared to existing methods.
Automatic Generation of Typographic Font from a Small Font Subset
Jan 20, 2017
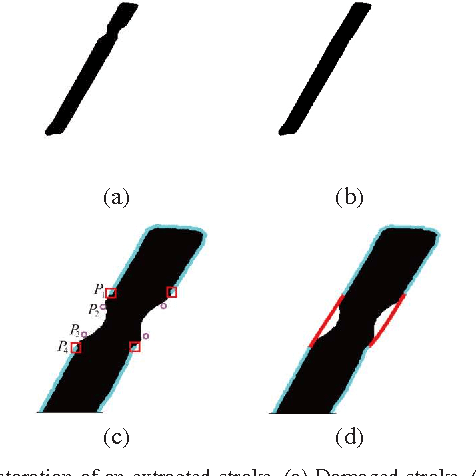
This paper addresses the automatic generation of a typographic font from a subset of characters. Specifically, we use a subset of a typographic font to extrapolate additional characters. Consequently, we obtain a complete font containing a number of characters sufficient for daily use. The automated generation of Japanese fonts is in high demand because a Japanese font requires over 1,000 characters. Unfortunately, professional typographers create most fonts, resulting in significant financial and time investments for font generation. The proposed method can be a great aid for font creation because designers do not need to create the majority of the characters for a new font. The proposed method uses strokes from given samples for font generation. The strokes, from which we construct characters, are extracted by exploiting a character skeleton dataset. This study makes three main contributions: a novel method of extracting strokes from characters, which is applicable to both standard fonts and their variations; a fully automated approach for constructing characters; and a selection method for sample characters. We demonstrate our proposed method by generating 2,965 characters in 47 fonts. Objective and subjective evaluations verify that the generated characters are similar to handmade characters.