 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-TCAV: Formalizing Penultimate Proxies for Efficient Concept Based Interpretability
May 11, 2026TCAV (Testing with Concept Activation Vectors) is an interpretability method that assesses the alignment between the internal representations of a trained neural network and human-understandable, high-level concepts. Though effective, TCAV suffers from significant computational overhead, inter-layer disagreement of TCAV scores, and statistical instability. This work takes a step toward addressing these challenges by introducing E-TCAV, a framework for efficient approximation of TCAV scores, which is based on extensive investigation into three key aspects of the TCAV methodology: 1) the effect of latent classifiers on the stability of TCAV scores, 2) the inter-layer agreement of TCAV scores, and 3) the use of the penultimate layer as a fast proxy for earlier layers for TCAV computation. To ensure a solid foundation for E-TCAV, we conduct extensive evaluations across four different architectures and five datasets, encompassing problems from both computer vision and natural language domains. Our results show that the layers in the final block of the neural network strongly agree with the penultimate layer in terms of the TCAV scores, and the commonly observed variance of the TCAV scores can be attributed to the choice of the latent classifier. Leveraging this inter-layer agreement and the degeneracy of directional sensitivities at the penultimate layer, E-TCAV guarantees linearly scaling speed-ups with respect to the network's size and the number of evaluation samples, marking a step towards efficient model debugging and real-time concept-guided training.
SLUM-i: Semi-supervised Learning for Urban Mapping of Informal Settlements and Data Quality Benchmarking
Feb 04, 2026Rapid urban expansion has fueled the growth of informal settlements in major cities of low- and middle-income countries, with Lahore and Karachi in Pakistan and Mumbai in India serving as prominent examples. However, large-scale mapping of these settlements is severely constrained not only by the scarcity of annotations but by inherent data quality challenges, specifically high spectral ambiguity between formal and informal structures and significant annotation noise. We address this by introducing a benchmark dataset for Lahore, constructed from scratch, along with companion datasets for Karachi and Mumbai, which were derived from verified administrative boundaries, totaling 1,869 $\text{km}^2$ of area. To evaluate the global robustness of our framework, we extend our experiments to five additional established benchmarks, encompassing eight cities across three continents, and provide comprehensive data quality assessments of all datasets. We also propose a new semi-supervised segmentation framework designed to mitigate the class imbalance and feature degradation inherent in standard semi-supervised learning pipelines. Our method integrates a Class-Aware Adaptive Thresholding mechanism that dynamically adjusts confidence thresholds to prevent minority class suppression and a Prototype Bank System that enforces semantic consistency by anchoring predictions to historically learned high-fidelity feature representations. Extensive experiments across a total of eight cities spanning three continents demonstrate that our approach outperforms state-of-the-art semi-supervised baselines. Most notably, our method demonstrates superior domain transfer capability whereby a model trained on only 10% of source labels reaches a 0.461 mIoU on unseen geographies and outperforms the zero-shot generalization of fully supervised models.
Brain-Gen: Towards Interpreting Neural Signals for Stimulus Reconstruction Using Transformers and Latent Diffusion Models
Dec 21, 2025Advances in neuroscience and artificial intelligence have enabled preliminary decoding of brain activity. However, despite the progress, the interpretability of neural representations remains limited. A significant challenge arises from the intrinsic properties of electroencephalography (EEG) signals, including high noise levels, spatial diffusion, and pronounced temporal variability. To interpret the neural mechanism underlying thoughts, we propose a transformers-based framework to extract spatial-temporal representations associated with observed visual stimuli from EEG recordings. These features are subsequently incorporated into the attention mechanisms of Latent Diffusion Models (LDMs) to facilitate the reconstruction of visual stimuli from brain activity. The quantitative evaluations on publicly available benchmark datasets demonstrate that the proposed method excels at modeling the semantic structures from EEG signals; achieving up to 6.5% increase in latent space clustering accuracy and 11.8% increase in zero shot generalization across unseen classes while having comparable Inception Score and Fréchet Inception Distance with existing baselines. Our work marks a significant step towards generalizable semantic interpretation of the EEG signals.
Block Induced Signature Generative Adversarial Network (BISGAN): Signature Spoofing Using GANs and Their Evaluation
Oct 08, 2024



Deep learning is actively being used in biometrics to develop efficient identification and verification systems. Handwritten signatures are a common subset of biometric data for authentication purposes. Generative adversarial networks (GANs) learn from original and forged signatures to generate forged signatures. While most GAN techniques create a strong signature verifier, which is the discriminator, there is a need to focus more on the quality of forgeries generated by the generator model. This work focuses on creating a generator that produces forged samples that achieve a benchmark in spoofing signature verification systems. We use CycleGANs infused with Inception model-like blocks with attention heads as the generator and a variation of the SigCNN model as the base Discriminator. We train our model with a new technique that results in 80% to 100% success in signature spoofing. Additionally, we create a custom evaluation technique to act as a goodness measure of the generated forgeries. Our work advocates generator-focused GAN architectures for spoofing data quality that aid in a better understanding of biometric data generation and evaluation.
A Perspective Analysis of Handwritten Signature Technology
May 22, 2024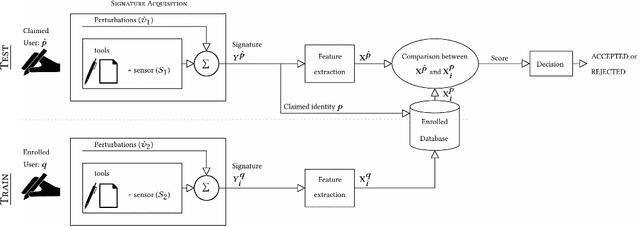
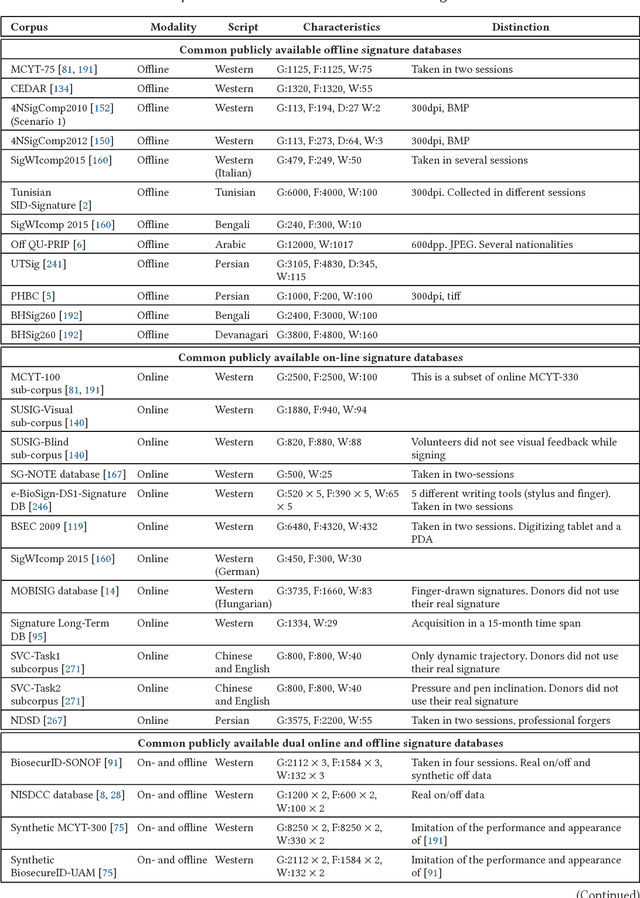

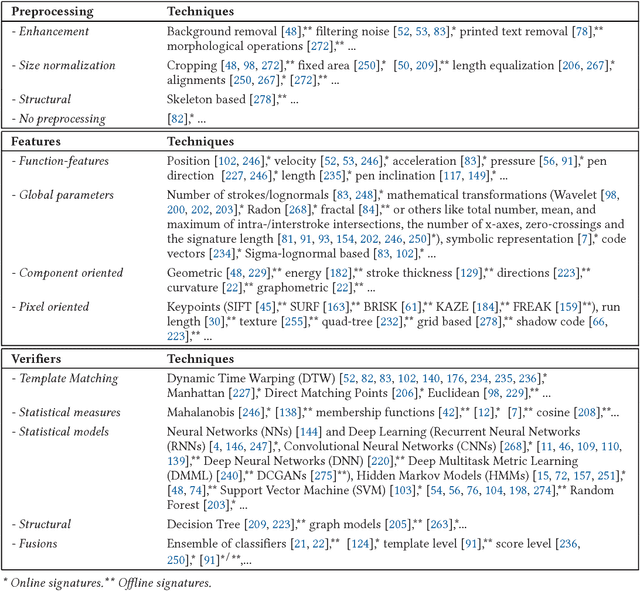
Handwritten signatures are biometric traits at the center of debate in the scientific community. Over the last 40 years, the interest in signature studies has grown steadily, having as its main reference the application of automatic signature verification, as previously published reviews in 1989, 2000, and 2008 bear witness. Ever since, and over the last 10 years, the application of handwritten signature technology has strongly evolved, and much research has focused on the possibility of applying systems based on handwritten signature analysis and processing to a multitude of new fields. After several years of haphazard growth of this research area, it is time to assess its current developments for their applicability in order to draw a structured way forward. This perspective reports a systematic review of the last 10 years of the literature on handwritten signatures with respect to the new scenario, focusing on the most promising domains of research and trying to elicit possible future research directions in this subject.
Few-Shot Learning for Biometric Verification
Nov 12, 2022



In machine learning applications, it is common practice to feed as much information as possible. In most cases, the model can handle large data sets that allow to predict more accurately. In the presence of data scarcity, a Few-Shot learning (FSL) approach aims to build more accurate algorithms with limited training data. We propose a novel end-to-end lightweight architecture that verifies biometric data by producing competitive results as compared to state-of-the-art accuracies through Few-Shot learning methods. The dense layers add to the complexity of state-of-the-art deep learning models which inhibits them to be used in low-power applications. In presented approach, a shallow network is coupled with a conventional machine learning technique that exploits hand-crafted features to verify biometric images from multi-modal sources such as signatures, periocular region, iris, face, fingerprints etc. We introduce a self-estimated threshold that strictly monitors False Acceptance Rate (FAR) while generalizing its results hence eliminating user-defined thresholds from ROC curves that are likely to be biased on local data distribution. This hybrid model benefits from few-shot learning to make up for scarcity of data in biometric use-cases. We have conducted extensive experimentation with commonly used biometric datasets. The obtained results provided an effective solution for biometric verification systems.
KENN: Enhancing Deep Neural Networks by Leveraging Knowledge for Time Series Forecasting
Feb 16, 2022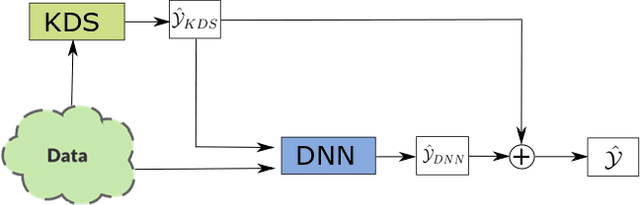

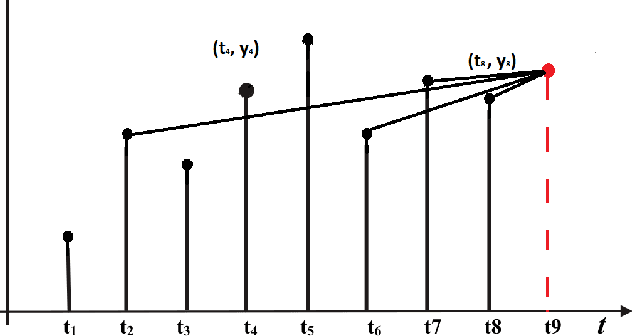
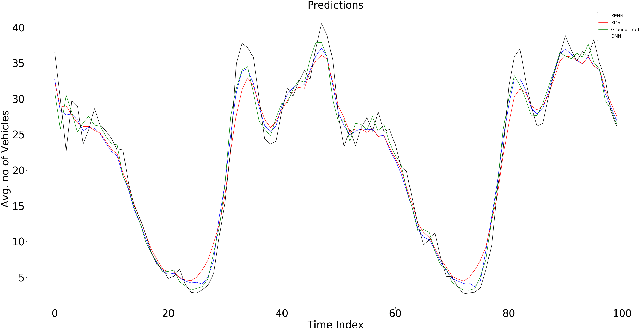
End-to-end data-driven machine learning methods often have exuberant requirements in terms of quality and quantity of training data which are often impractical to fulfill in real-world applications. This is specifically true in time series domain where problems like disaster prediction, anomaly detection, and demand prediction often do not have a large amount of historical data. Moreover, relying purely on past examples for training can be sub-optimal since in doing so we ignore one very important domain i.e knowledge, which has its own distinct advantages. In this paper, we propose a novel knowledge fusion architecture, Knowledge Enhanced Neural Network (KENN), for time series forecasting that specifically aims towards combining strengths of both knowledge and data domains while mitigating their individual weaknesses. We show that KENN not only reduces data dependency of the overall framework but also improves performance by producing predictions that are better than the ones produced by purely knowledge and data driven domains. We also compare KENN with state-of-the-art forecasting methods and show that predictions produced by KENN are significantly better even when trained on only 50\% of the data.
ExAID: A Multimodal Explanation Framework for Computer-Aided Diagnosis of Skin Lesions
Jan 04, 2022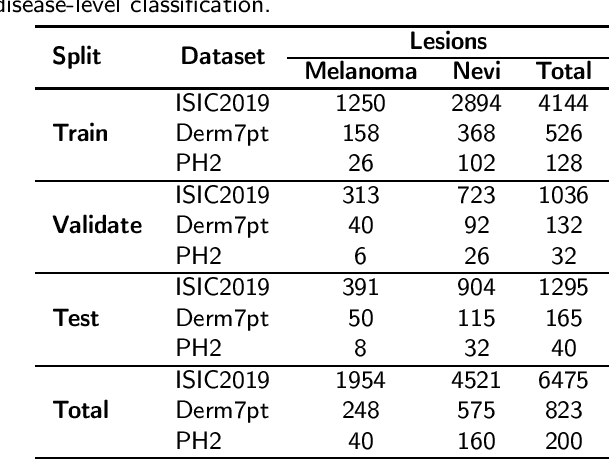
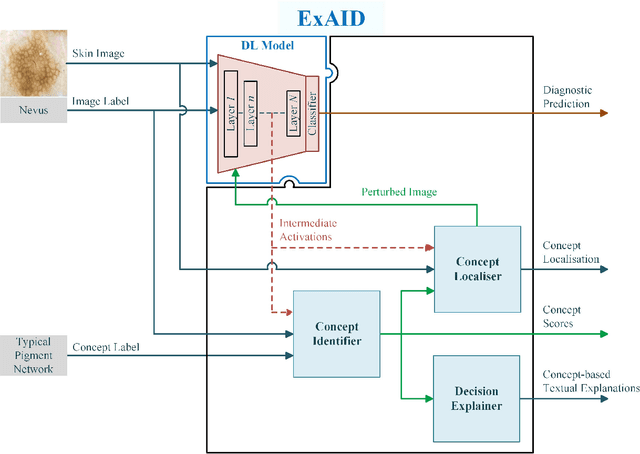
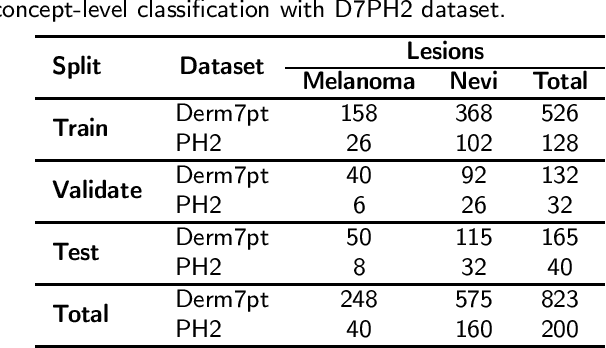
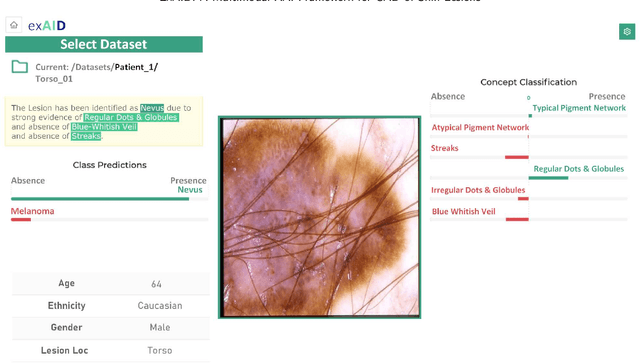
One principal impediment in the successful deployment of AI-based Computer-Aided Diagnosis (CAD) systems in clinical workflows is their lack of transparent decision making. Although commonly used eXplainable AI methods provide some insight into opaque algorithms, such explanations are usually convoluted and not readily comprehensible except by highly trained experts. The explanation of decisions regarding the malignancy of skin lesions from dermoscopic images demands particular clarity, as the underlying medical problem definition is itself ambiguous. This work presents ExAID (Explainable AI for Dermatology), a novel framework for biomedical image analysis, providing multi-modal concept-based explanations consisting of easy-to-understand textual explanations supplemented by visual maps justifying the predictions. ExAID relies on Concept Activation Vectors to map human concepts to those learnt by arbitrary Deep Learning models in latent space, and Concept Localization Maps to highlight concepts in the input space. This identification of relevant concepts is then used to construct fine-grained textual explanations supplemented by concept-wise location information to provide comprehensive and coherent multi-modal explanations. All information is comprehensively presented in a diagnostic interface for use in clinical routines. An educational mode provides dataset-level explanation statistics and tools for data and model exploration to aid medical research and education. Through rigorous quantitative and qualitative evaluation of ExAID, we show the utility of multi-modal explanations for CAD-assisted scenarios even in case of wrong predictions. We believe that ExAID will provide dermatologists an effective screening tool that they both understand and trust. Moreover, it will be the basis for similar applications in other biomedical imaging fields.
Combining Fine- and Coarse-Grained Classifiers for Diabetic Retinopathy Detection
May 28, 2020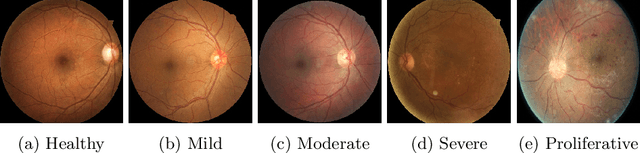
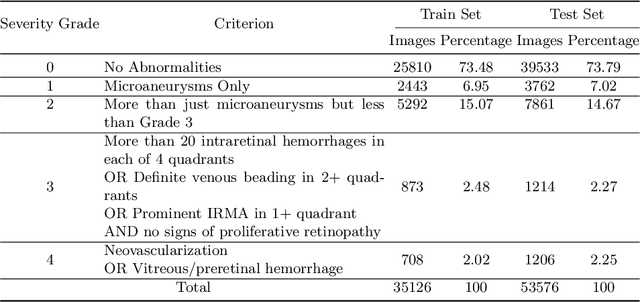
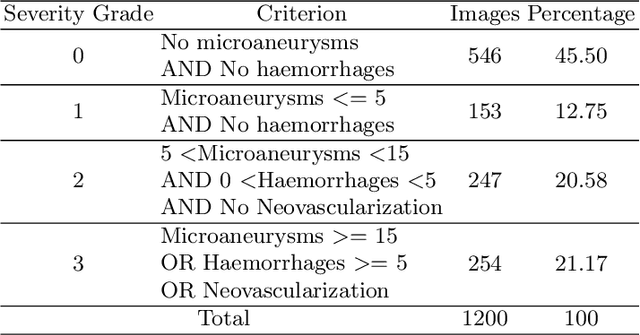
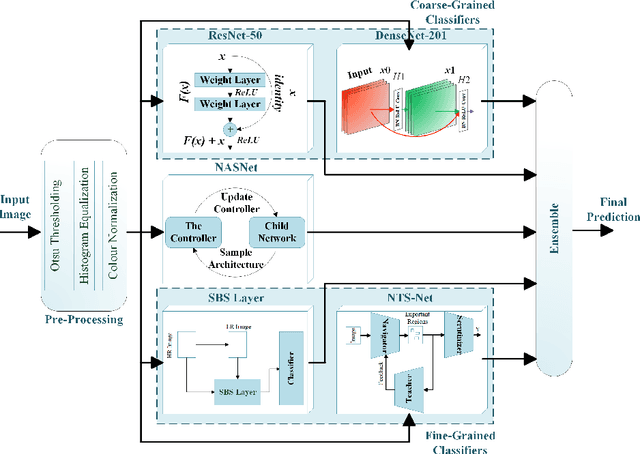
Visual artefacts of early diabetic retinopathy in retinal fundus images are usually small in size, inconspicuous, and scattered all over retina. Detecting diabetic retinopathy requires physicians to look at the whole image and fixate on some specific regions to locate potential biomarkers of the disease. Therefore, getting inspiration from ophthalmologist, we propose to combine coarse-grained classifiers that detect discriminating features from the whole images, with a recent breed of fine-grained classifiers that discover and pay particular attention to pathologically significant regions. To evaluate the performance of this proposed ensemble, we used publicly available EyePACS and Messidor datasets. Extensive experimentation for binary, ternary and quaternary classification shows that this ensemble largely outperforms individual image classifiers as well as most of the published works in most training setups for diabetic retinopathy detection. Furthermore, the performance of fine-grained classifiers is found notably superior than coarse-grained image classifiers encouraging the development of task-oriented fine-grained classifiers modelled after specialist ophthalmologists.
Two-stage framework for optic disc localization and glaucoma classification in retinal fundus images using deep learning
May 28, 2020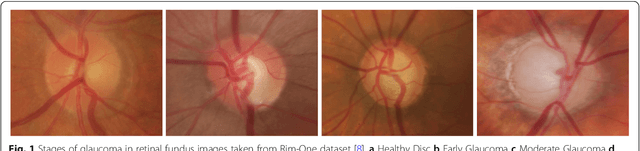
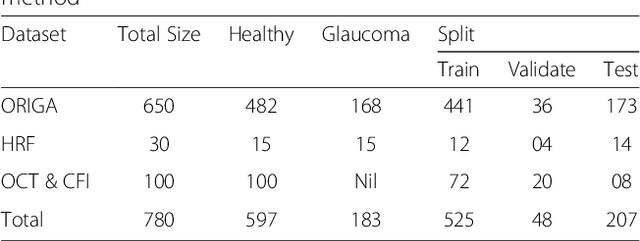

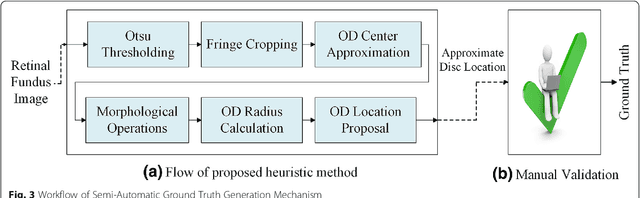
With the advancement of powerful image processing and machine learning techniques, CAD has become ever more prevalent in all fields of medicine including ophthalmology. Since optic disc is the most important part of retinal fundus image for glaucoma detection, this paper proposes a two-stage framework that first detects and localizes optic disc and then classifies it into healthy or glaucomatous. The first stage is based on RCNN and is responsible for localizing and extracting optic disc from a retinal fundus image while the second stage uses Deep CNN to classify the extracted disc into healthy or glaucomatous. In addition to the proposed solution, we also developed a rule-based semi-automatic ground truth generation method that provides necessary annotations for training RCNN based model for automated disc localization. The proposed method is evaluated on seven publicly available datasets for disc localization and on ORIGA dataset, which is the largest publicly available dataset for glaucoma classification. The results of automatic localization mark new state-of-the-art on six datasets with accuracy reaching 100% on four of them. For glaucoma classification we achieved AUC equal to 0.874 which is 2.7% relative improvement over the state-of-the-art results previously obtained for classification on ORIGA. Once trained on carefully annotated data, Deep Learning based methods for optic disc detection and localization are not only robust, accurate and fully automated but also eliminates the need for dataset-dependent heuristic algorithms. Our empirical evaluation of glaucoma classification on ORIGA reveals that reporting only AUC, for datasets with class imbalance and without pre-defined train and test splits, does not portray true picture of the classifier's performance and calls for additional performance metrics to substantiate the results.
* 16 Pages, 10 Figures