 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLUM-i: Semi-supervised Learning for Urban Mapping of Informal Settlements and Data Quality Benchmarking
Feb 04, 2026Rapid urban expansion has fueled the growth of informal settlements in major cities of low- and middle-income countries, with Lahore and Karachi in Pakistan and Mumbai in India serving as prominent examples. However, large-scale mapping of these settlements is severely constrained not only by the scarcity of annotations but by inherent data quality challenges, specifically high spectral ambiguity between formal and informal structures and significant annotation noise. We address this by introducing a benchmark dataset for Lahore, constructed from scratch, along with companion datasets for Karachi and Mumbai, which were derived from verified administrative boundaries, totaling 1,869 $\text{km}^2$ of area. To evaluate the global robustness of our framework, we extend our experiments to five additional established benchmarks, encompassing eight cities across three continents, and provide comprehensive data quality assessments of all datasets. We also propose a new semi-supervised segmentation framework designed to mitigate the class imbalance and feature degradation inherent in standard semi-supervised learning pipelines. Our method integrates a Class-Aware Adaptive Thresholding mechanism that dynamically adjusts confidence thresholds to prevent minority class suppression and a Prototype Bank System that enforces semantic consistency by anchoring predictions to historically learned high-fidelity feature representations. Extensive experiments across a total of eight cities spanning three continents demonstrate that our approach outperforms state-of-the-art semi-supervised baselines. Most notably, our method demonstrates superior domain transfer capability whereby a model trained on only 10% of source labels reaches a 0.461 mIoU on unseen geographies and outperforms the zero-shot generalization of fully supervised models.
KENN: Enhancing Deep Neural Networks by Leveraging Knowledge for Time Series Forecasting
Feb 16, 2022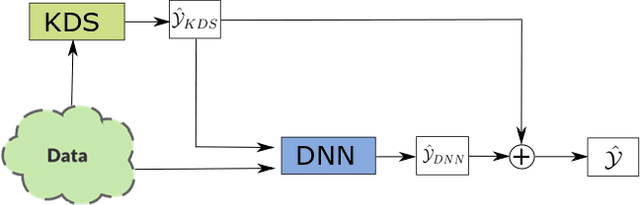

End-to-end data-driven machine learning methods often have exuberant requirements in terms of quality and quantity of training data which are often impractical to fulfill in real-world applications. This is specifically true in time series domain where problems like disaster prediction, anomaly detection, and demand prediction often do not have a large amount of historical data. Moreover, relying purely on past examples for training can be sub-optimal since in doing so we ignore one very important domain i.e knowledge, which has its own distinct advantages. In this paper, we propose a novel knowledge fusion architecture, Knowledge Enhanced Neural Network (KENN), for time series forecasting that specifically aims towards combining strengths of both knowledge and data domains while mitigating their individual weaknesses. We show that KENN not only reduces data dependency of the overall framework but also improves performance by producing predictions that are better than the ones produced by purely knowledge and data driven domains. We also compare KENN with state-of-the-art forecasting methods and show that predictions produced by KENN are significantly better even when trained on only 50\% of the data.
A Survey on Knowledge integration techniques with Artificial Neural Networks for seq-2-seq/time series models
Aug 13, 2020
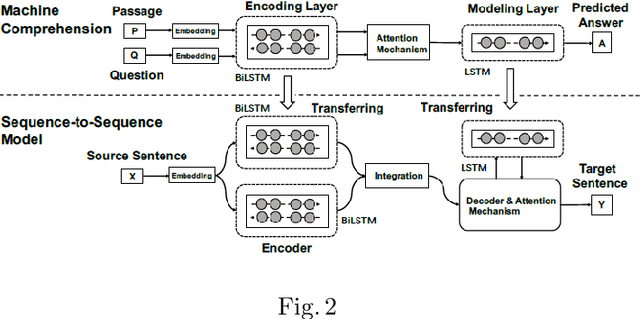
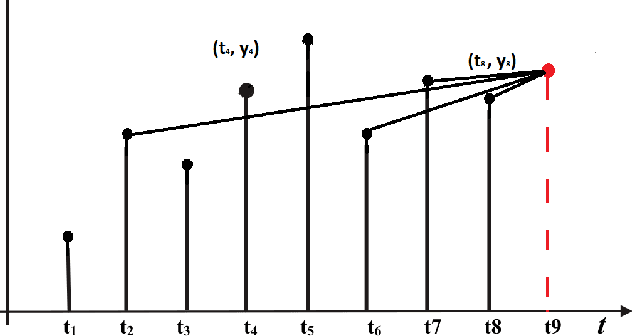
In recent years, with the advent of massive computational power and the availability of huge amounts of data, Deep neural networks have enabled the exploration of uncharted areas in several domains. But at times, they under-perform due to insufficient data, poor data quality, data that might not be covering the domain broadly, etc. Knowledge-based systems leverage expert knowledge for making decisions and suitably take actions. Such systems retain interpretability in the decision-making process. This paper focuses on exploring techniques to integrate expert knowledge to the Deep Neural Networks for sequence-to-sequence and time series models to improve their performance and interpretability.
KINN: Incorporating Expert Knowledge in Neural Networks
Feb 15, 2019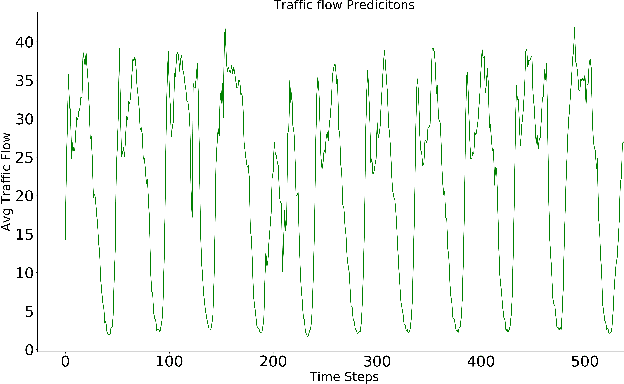
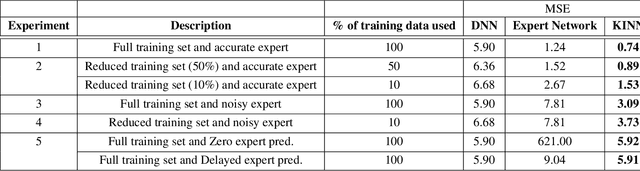
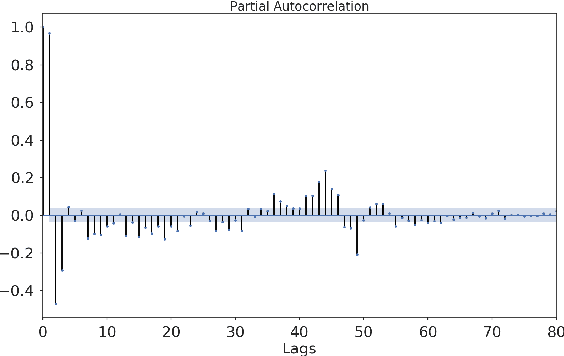
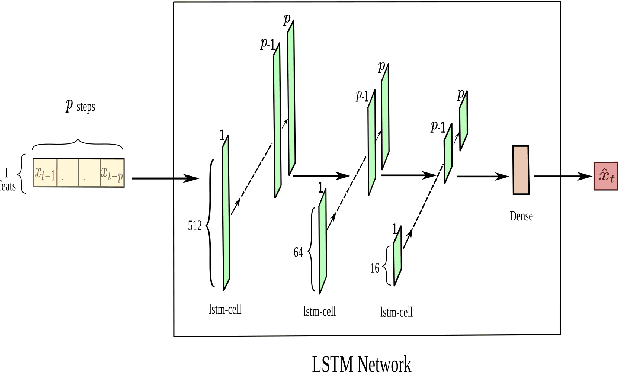
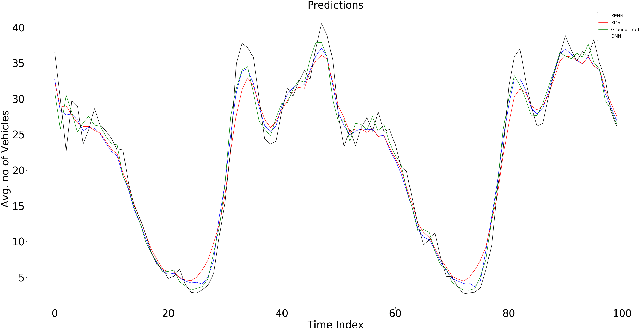
The promise of ANNs to automatically discover and extract useful features/patterns from data without dwelling on domain expertise although seems highly promising but comes at the cost of high reliance on large amount of accurately labeled data, which is often hard to acquire and formulate especially in time-series domains like anomaly detection, natural disaster management, predictive maintenance and healthcare. As these networks completely rely on data and ignore a very important modality i.e. expert, they are unable to harvest any benefit from the expert knowledge, which in many cases is very useful. In this paper, we try to bridge the gap between these data driven and expert knowledge based systems by introducing a novel framework for incorporating expert knowledge into the network (KINN). Integrating expert knowledge into the network has three key advantages: (a) Reduction in the amount of data needed to train the model, (b) provision of a lower bound on the performance of the resulting classifier by obtaining the best of both worlds, and (c) improved convergence of model parameters (model converges in smaller number of epochs). Although experts are extremely good in solving different tasks, there are some trends and patterns, which are usually hidden only in the data. Therefore, KINN employs a novel residual knowledge incorporation scheme, which can automatically determine the quality of the predictions made by the expert and rectify it accordingly by learning the trends/patterns from data. Specifically, the method tries to use information contained in one modality to complement information missed by the other. We evaluated KINN on a real world traffic flow prediction problem. KINN significantly superseded performance of both the expert and as well as the base network (LSTM in this case) when evaluated in isolation, highlighting its superiority for the task.