 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generic Method for Automatic Ground Truth Generation of Camera-captured Documents
Paper and Code
May 04, 2016


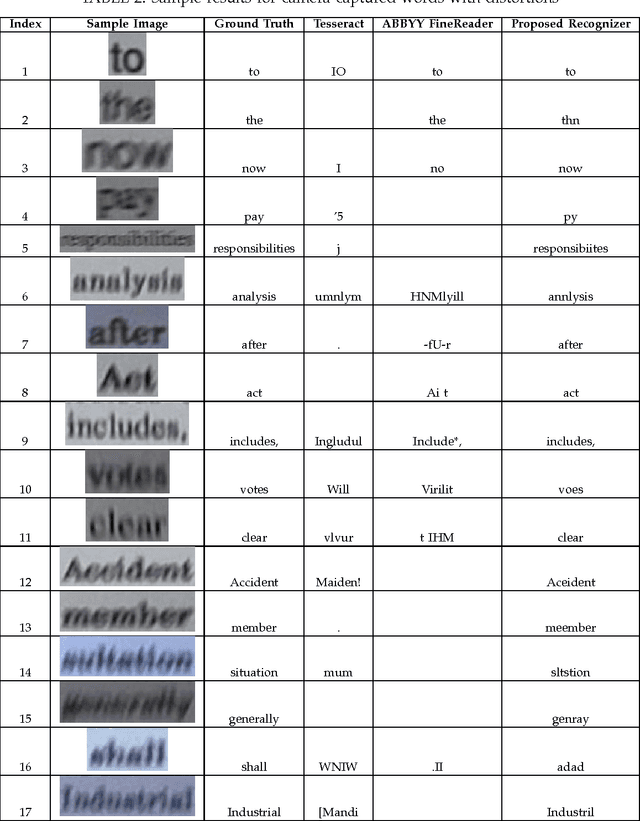
The contribution of this paper is fourfold. The first contribution is a novel, generic method for automatic ground truth generation of camera-captured document images (books, magazines, articles, invoices, etc.). It enables us to build large-scale (i.e., millions of images) labeled camera-captured/scanned documents datasets, without any human intervention. The method is generic, language independent and can be used for generation of labeled documents datasets (both scanned and cameracaptured) in any cursive and non-cursive language, e.g., English, Russian, Arabic, Urdu, etc. To assess the effectiveness of the presented method, two different datasets in English and Russian are generated using the presented method. Evaluation of samples from the two datasets shows that 99:98% of the images were correctly labeled. The second contribution is a large dataset (called C3Wi) of camera-captured characters and words images, comprising 1 million word images (10 million character images), captured in a real camera-based acquisition. This dataset can be used for training as well as testing of character recognition systems on camera-captured documents. The third contribution is a novel method for the recognition of cameracaptured document images. The proposed method is based on Long Short-Term Memory and outperforms the state-of-the-art methods for camera based OCRs. As a fourth contribution, various benchmark tests are performed to uncover the behavior of commercial (ABBYY), open source (Tesseract), and the presented camera-based OCR using the presented C3Wi dataset. Evaluation results reveal that the existing OCRs, which already get very high accuracies on scanned documents, have limited performance on camera-captured document images; where ABBYY has an accuracy of 75%, Tesseract an accuracy of 50.22%, while the presented character recognition system has an accuracy of 95.10%.