 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYieldSAT: A Multimodal Benchmark Dataset for High-Resolution Crop Yield Prediction
Apr 01, 2026Crop yield prediction requires substantial data to train scalable models. However, creating yield prediction datasets is constrained by high acquisition costs, heterogeneous data quality, and data privacy regulations. Consequently, existing datasets are scarce, low in quality, or limited to regional levels or single crop types, hindering the development of scalable data-driven solutions. In this work, we release YieldSAT, a large, high-quality, and multimodal dataset for high-resolution crop yield prediction. YieldSAT spans various climate zones across multiple countries, including Argentina, Brazil, Uruguay, and Germany, and includes major crop types, including corn, rapeseed, soybeans, and wheat, across 2,173 expert-curated fields. In total, over 12.2 million yield samples are available, each with a spatial resolution of 10 m. Each field is paired with multispectral satellite imagery, resulting in 113,555 labeled satellite images, complemented by auxiliary environmental data. We demonstrate the potential of large-scale and high-resolution crop yield prediction as a pixel regression task by comparing various deep learning models and data fusion architectures. Furthermore, we highlight open challenges arising from severe distribution shifts in the ground truth data under real-world conditions. To mitigate this, we explore a domain-informed Deep Ensemble approach that exhibits significant performance gains. The dataset is available at https://yieldsat.github.io/.
Exploring Physics-Informed Neural Networks for Crop Yield Loss Forecasting
Dec 31, 2024In response to climate change, assessing crop productivity under extreme weather conditions is essential to enhance food security. Crop simulation models, which align with physical processes, offer explainability but often perform poorly. Conversely, machine learning (ML) models for crop modeling are powerful and scalable yet operate as black boxes and lack adherence to crop growths physical principles. To bridge this gap, we propose a novel method that combines the strengths of both approaches by estimating the water use and the crop sensitivity to water scarcity at the pixel level. This approach enables yield loss estimation grounded in physical principles by sequentially solving the equation for crop yield response to water scarcity, using an enhanced loss function. Leveraging Sentinel-2 satellite imagery, climate data, simulated water use data, and pixel-level yield data, our model demonstrates high accuracy, achieving an R2 of up to 0.77, matching or surpassing state-of-the-art models like RNNs and Transformers. Additionally, it provides interpretable and physical consistent outputs, supporting industry, policymakers, and farmers in adapting to extreme weather conditions.
* 6 pages, 2 figures, NeurIPS 2024 Workshop on Tackling Climate Change with Machine Learning
Impact Assessment of Missing Data in Model Predictions for Earth Observation Applications
Mar 21, 2024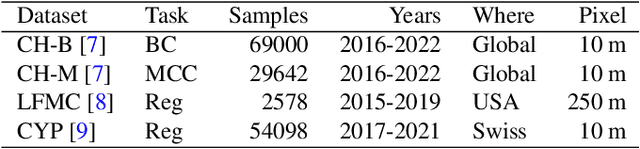
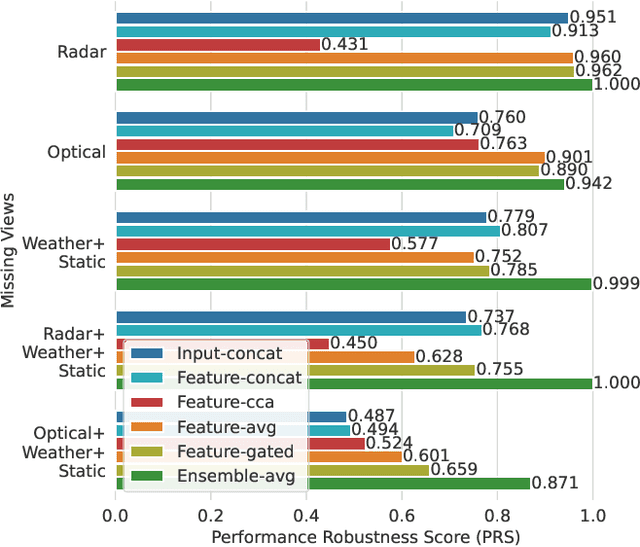

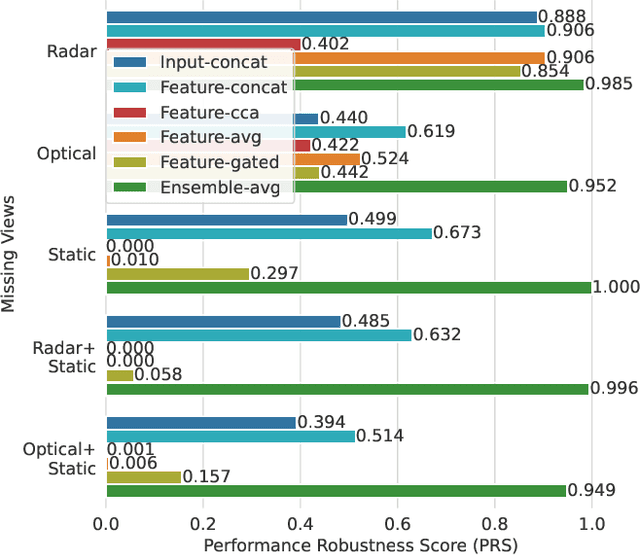
Earth observation (EO) applications involving complex and heterogeneous data sources are commonly approached with machine learning models. However, there is a common assumption that data sources will be persistently available. Different situations could affect the availability of EO sources, like noise, clouds, or satellite mission failures. In this work, we assess the impact of missing temporal and static EO sources in trained models across four datasets with classification and regression tasks. We compare the predictive quality of different methods and find that some are naturally more robust to missing data. The Ensemble strategy, in particular, achieves a prediction robustness up to 100%. We evidence that missing scenarios are significantly more challenging in regression than classification tasks. Finally, we find that the optical view is the most critical view when it is missing individually.
Adaptive Fusion of Multi-view Remote Sensing data for Optimal Sub-field Crop Yield Prediction
Jan 22, 2024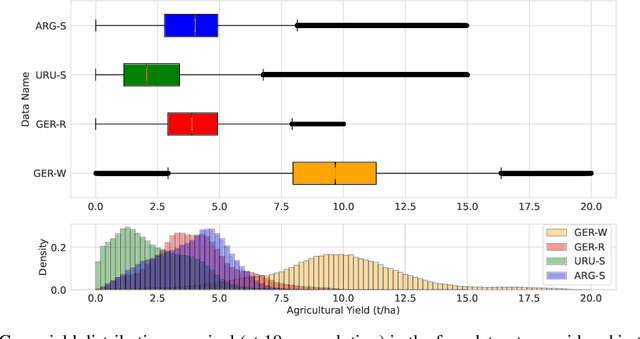


Accurate crop yield prediction is of utmost importance for informed decision-making in agriculture, aiding farmers, and industry stakeholders. However, this task is complex and depends on multiple factors, such as environmental conditions, soil properties, and management practices. Combining heterogeneous data views poses a fusion challenge, like identifying the view-specific contribution to the predictive task. We present a novel multi-view learning approach to predict crop yield for different crops (soybean, wheat, rapeseed) and regions (Argentina, Uruguay, and Germany). Our multi-view input data includes multi-spectral optical images from Sentinel-2 satellites and weather data as dynamic features during the crop growing season, complemented by static features like soil properties and topographic information. To effectively fuse the data, we introduce a Multi-view Gated Fusion (MVGF) model, comprising dedicated view-encoders and a Gated Unit (GU) module. The view-encoders handle the heterogeneity of data sources with varying temporal resolutions by learning a view-specific representation. These representations are adaptively fused via a weighted sum. The fusion weights are computed for each sample by the GU using a concatenation of the view-representations. The MVGF model is trained at sub-field level with 10 m resolution pixels. Our evaluations show that the MVGF outperforms conventional models on the same task, achieving the best results by incorporating all the data sources, unlike the usual fusion results in the literature. For Argentina, the MVGF model achieves an R2 value of 0.68 at sub-field yield prediction, while at field level evaluation (comparing field averages), it reaches around 0.80 across different countries. The GU module learned different weights based on the country and crop-type, aligning with the variable significance of each data source to the prediction task.
Predicting Crop Yield With Machine Learning: An Extensive Analysis Of Input Modalities And Models On a Field and sub-field Level
Aug 17, 2023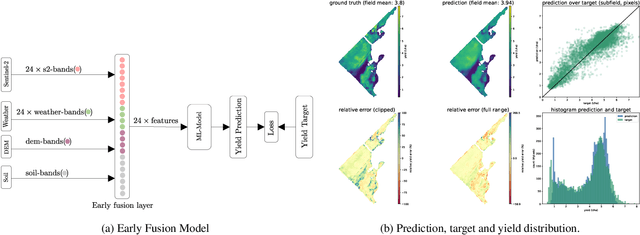
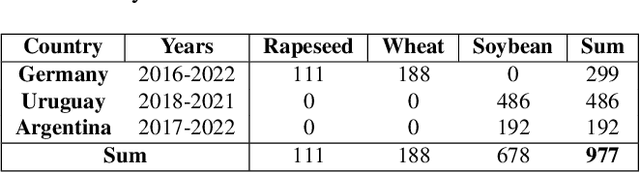
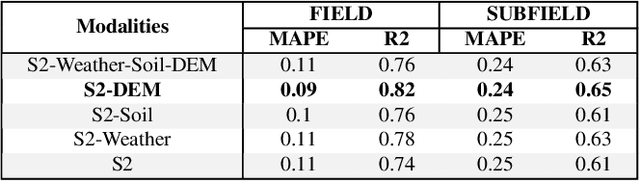
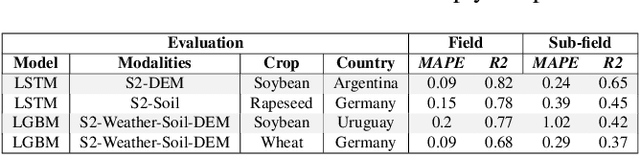
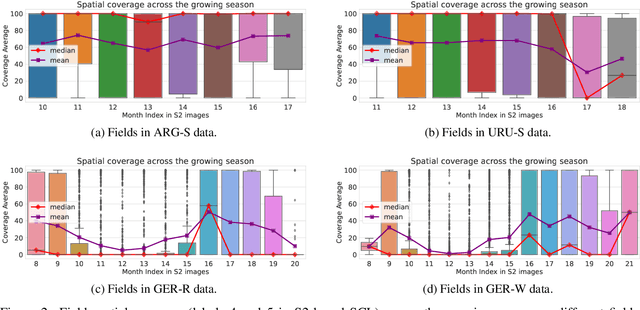
We introduce a simple yet effective early fusion method for crop yield prediction that handles multiple input modalities with different temporal and spatial resolutions. We use high-resolution crop yield maps as ground truth data to train crop and machine learning model agnostic methods at the sub-field level. We use Sentinel-2 satellite imagery as the primary modality for input data with other complementary modalities, including weather, soil, and DEM data. The proposed method uses input modalities available with global coverage, making the framework globally scalable. We explicitly highlight the importance of input modalities for crop yield prediction and emphasize that the best-performing combination of input modalities depends on region, crop, and chosen model.
Satellite Image Search in AgoraEO
Aug 23, 2022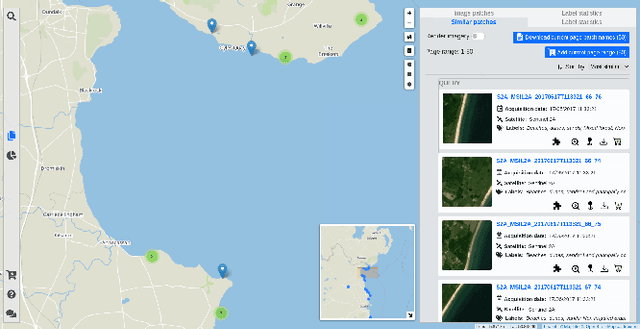

The growing operational capability of global Earth Observation (EO) creates new opportunities for data-driven approaches to understand and protect our planet. However, the current use of EO archives is very restricted due to the huge archive sizes and the limited exploration capabilities provided by EO platforms. To address this limitation, we have recently proposed MiLaN, a content-based image retrieval approach for fast similarity search in satellite image archives. MiLaN is a deep hashing network based on metric learning that encodes high-dimensional image features into compact binary hash codes. We use these codes as keys in a hash table to enable real-time nearest neighbor search and highly accurate retrieval. In this demonstration, we showcase the efficiency of MiLaN by integrating it with EarthQube, a browser and search engine within AgoraEO. EarthQube supports interactive visual exploration and Query-by-Example over satellite image repositories. Demo visitors will interact with EarthQube playing the role of different users that search images in a large-scale remote sensing archive by their semantic content and apply other filters.
BigEarthNet: A Large-Scale Benchmark Archive For Remote Sensing Image Understanding
Mar 22, 2019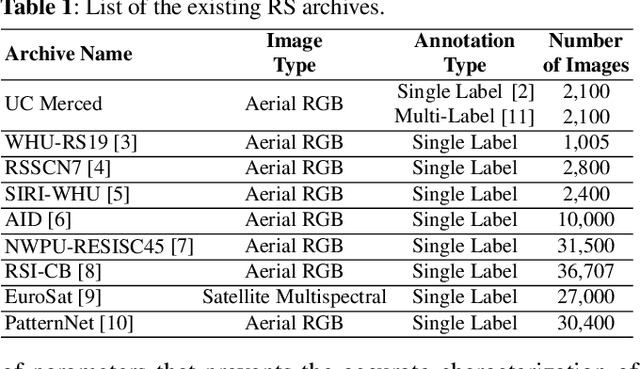

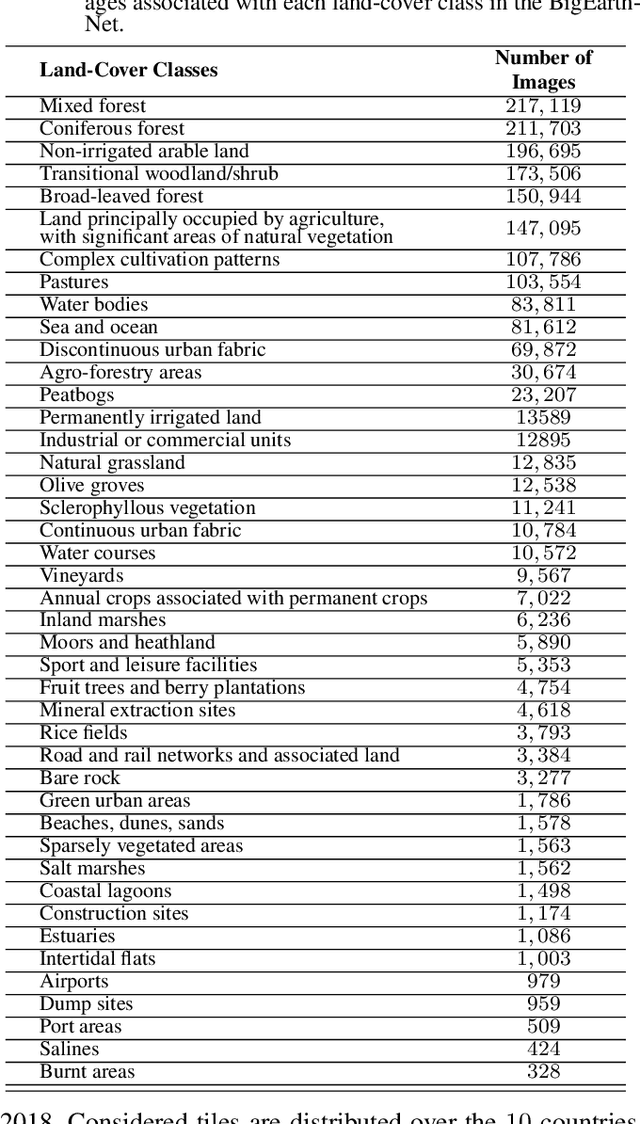

This paper presents the BigEarthNet that is a new large-scale multi-label Sentinel-2 benchmark archive. The BigEarthNet consists of 590,326 Sentinel-2 image patches, each of which is a section of i) 120x120 pixels for 10m bands; ii) 60x60 pixels for 20m bands; and iii) 20x20 pixels for 60m bands. Unlike most of the existing archives, each image patch is annotated by multiple land-cover classes (i.e., multi-labels) that are provided from the CORINE Land Cover database of the year 2018 (CLC 2018). The BigEarthNet is significantly larger than the existing archives in remote sensing (RS) and thus is much more convenient to be used as a training source in the context of deep learning. This paper first addresses the limitations of the existing archives and then describes properties of the BigEarthNet. Experimental results obtained in the framework of RS image scene classification problems show that a shallow Convolutional Neural Network (CNN) architecture trained on the BigEarthNet provides much higher accuracy compared to a state-of-the-art CNN model pre-trained on the ImageNet (which is a very popular large-scale benchmark archive in computer vision). The BigEarthNet opens up promising directions to advance operational RS applications and research in massive Sentinel-2 image archives.