 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYieldSAT: A Multimodal Benchmark Dataset for High-Resolution Crop Yield Prediction
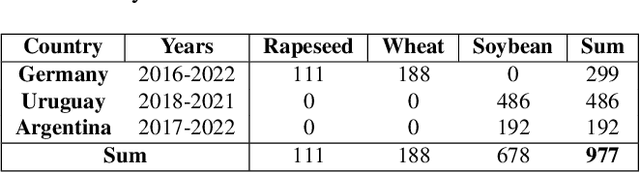
Apr 01, 2026Crop yield prediction requires substantial data to train scalable models. However, creating yield prediction datasets is constrained by high acquisition costs, heterogeneous data quality, and data privacy regulations. Consequently, existing datasets are scarce, low in quality, or limited to regional levels or single crop types, hindering the development of scalable data-driven solutions. In this work, we release YieldSAT, a large, high-quality, and multimodal dataset for high-resolution crop yield prediction. YieldSAT spans various climate zones across multiple countries, including Argentina, Brazil, Uruguay, and Germany, and includes major crop types, including corn, rapeseed, soybeans, and wheat, across 2,173 expert-curated fields. In total, over 12.2 million yield samples are available, each with a spatial resolution of 10 m. Each field is paired with multispectral satellite imagery, resulting in 113,555 labeled satellite images, complemented by auxiliary environmental data. We demonstrate the potential of large-scale and high-resolution crop yield prediction as a pixel regression task by comparing various deep learning models and data fusion architectures. Furthermore, we highlight open challenges arising from severe distribution shifts in the ground truth data under real-world conditions. To mitigate this, we explore a domain-informed Deep Ensemble approach that exhibits significant performance gains. The dataset is available at https://yieldsat.github.io/.
Adaptive Fusion of Multi-view Remote Sensing data for Optimal Sub-field Crop Yield Prediction
Jan 22, 2024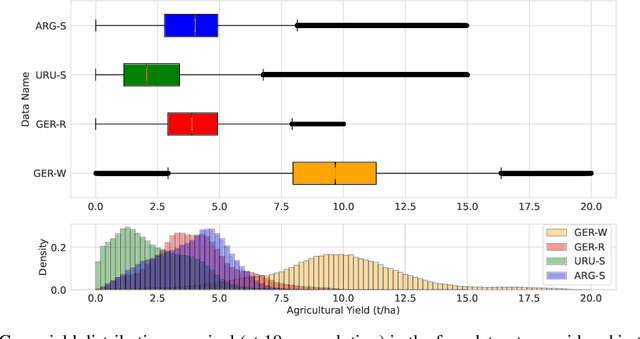

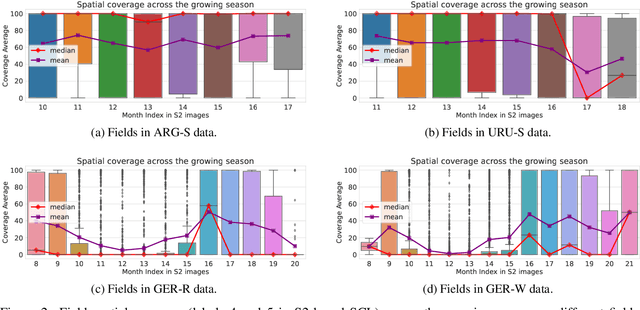

Accurate crop yield prediction is of utmost importance for informed decision-making in agriculture, aiding farmers, and industry stakeholders. However, this task is complex and depends on multiple factors, such as environmental conditions, soil properties, and management practices. Combining heterogeneous data views poses a fusion challenge, like identifying the view-specific contribution to the predictive task. We present a novel multi-view learning approach to predict crop yield for different crops (soybean, wheat, rapeseed) and regions (Argentina, Uruguay, and Germany). Our multi-view input data includes multi-spectral optical images from Sentinel-2 satellites and weather data as dynamic features during the crop growing season, complemented by static features like soil properties and topographic information. To effectively fuse the data, we introduce a Multi-view Gated Fusion (MVGF) model, comprising dedicated view-encoders and a Gated Unit (GU) module. The view-encoders handle the heterogeneity of data sources with varying temporal resolutions by learning a view-specific representation. These representations are adaptively fused via a weighted sum. The fusion weights are computed for each sample by the GU using a concatenation of the view-representations. The MVGF model is trained at sub-field level with 10 m resolution pixels. Our evaluations show that the MVGF outperforms conventional models on the same task, achieving the best results by incorporating all the data sources, unlike the usual fusion results in the literature. For Argentina, the MVGF model achieves an R2 value of 0.68 at sub-field yield prediction, while at field level evaluation (comparing field averages), it reaches around 0.80 across different countries. The GU module learned different weights based on the country and crop-type, aligning with the variable significance of each data source to the prediction task.
Predicting Crop Yield With Machine Learning: An Extensive Analysis Of Input Modalities And Models On a Field and sub-field Level
Aug 17, 2023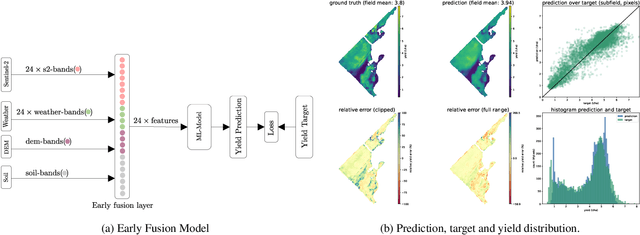
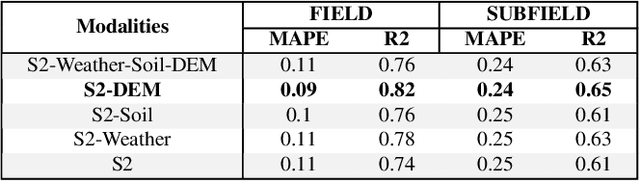
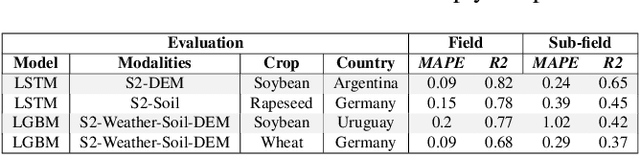
We introduce a simple yet effective early fusion method for crop yield prediction that handles multiple input modalities with different temporal and spatial resolutions. We use high-resolution crop yield maps as ground truth data to train crop and machine learning model agnostic methods at the sub-field level. We use Sentinel-2 satellite imagery as the primary modality for input data with other complementary modalities, including weather, soil, and DEM data. The proposed method uses input modalities available with global coverage, making the framework globally scalable. We explicitly highlight the importance of input modalities for crop yield prediction and emphasize that the best-performing combination of input modalities depends on region, crop, and chosen model.
RapidAI4EO: Mono- and Multi-temporal Deep Learning models for Updating the CORINE Land Cover Product
Oct 26, 2022



In the remote sensing community, Land Use Land Cover (LULC) classification with satellite imagery is a main focus of current research activities. Accurate and appropriate LULC classification, however, continues to be a challenging task. In this paper, we evaluate the performance of multi-temporal (monthly time series) compared to mono-temporal (single time step) satellite images for multi-label classification using supervised learning on the RapidAI4EO dataset. As a first step, we trained our CNN model on images at a single time step for multi-label classification, i.e. mono-temporal. We incorporated time-series images using a LSTM model to assess whether or not multi-temporal signals from satellites improves CLC classification. The results demonstrate an improvement of approximately 0.89% in classifying satellite imagery on 15 classes using a multi-temporal approach on monthly time series images compared to the mono-temporal approach. Using features from multi-temporal or mono-temporal images, this work is a step towards an efficient change detection and land monitoring approach.
RapidAI4EO: A Corpus for Higher Spatial and Temporal Reasoning
Oct 05, 2021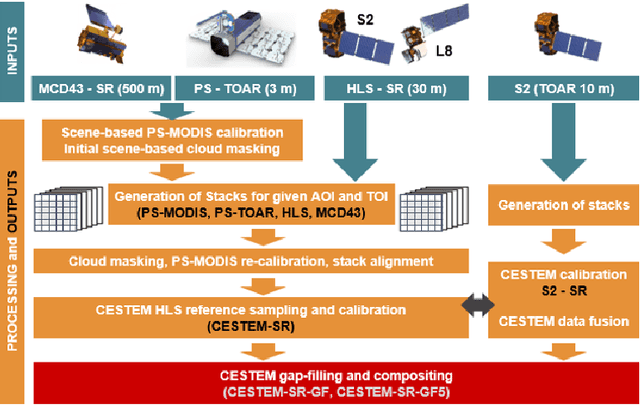


Under the sponsorship of the European Union Horizon 2020 program, RapidAI4EO will establish the foundations for the next generation of Copernicus Land Monitoring Service (CLMS) products. The project aims to provide intensified monitoring of Land Use (LU), Land Cover (LC), and LU change at a much higher level of detail and temporal cadence than it is possible today. Focus is on disentangling phenology from structural change and in providing critical training data to drive advancement in the Copernicus community and ecosystem well beyond the lifetime of this project. To this end we are creating the densest spatiotemporal training sets ever by fusing open satellite data with Planet imagery at as many as 500,000 patch locations over Europe and delivering high resolution daily time series at all locations. We plan to open source these datasets for the benefit of the entire remote sensing community.
Revisiting Sequence-to-Sequence Video Object Segmentation with Multi-Task Loss and Skip-Memory
Apr 25, 2020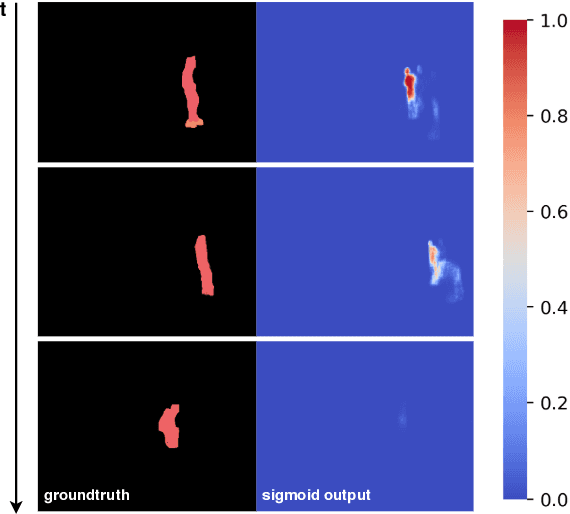
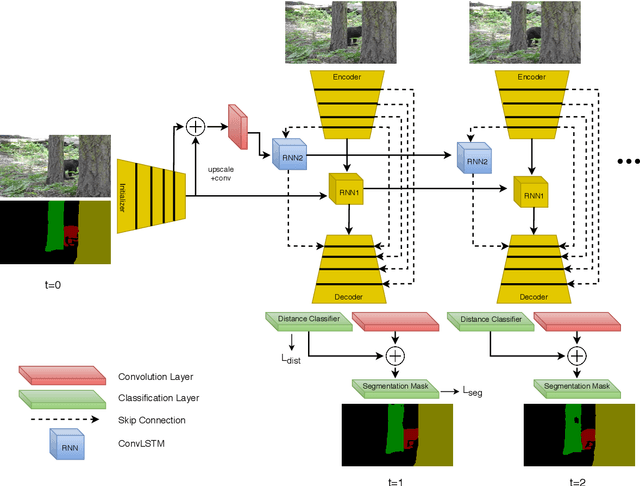
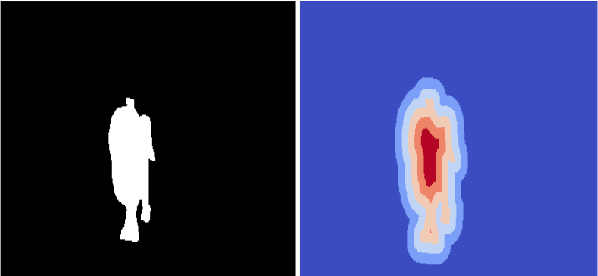

Video Object Segmentation (VOS) is an active research area of the visual domain. One of its fundamental sub-tasks is semi-supervised / one-shot learning: given only the segmentation mask for the first frame, the task is to provide pixel-accurate masks for the object over the rest of the sequence. Despite much progress in the last years, we noticed that many of the existing approaches lose objects in longer sequences, especially when the object is small or briefly occluded. In this work, we build upon a sequence-to-sequence approach that employs an encoder-decoder architecture together with a memory module for exploiting the sequential data. We further improve this approach by proposing a model that manipulates multi-scale spatio-temporal information using memory-equipped skip connections. Furthermore, we incorporate an auxiliary task based on distance classification which greatly enhances the quality of edges in segmentation masks. We compare our approach to the state of the art and show considerable improvement in the contour accuracy metric and the overall segmentation accuracy.
Multi$^{\mathbf{3}}$Net: Segmenting Flooded Buildings via Fusion of Multiresolution, Multisensor, and Multitemporal Satellite Imagery
Dec 05, 2018
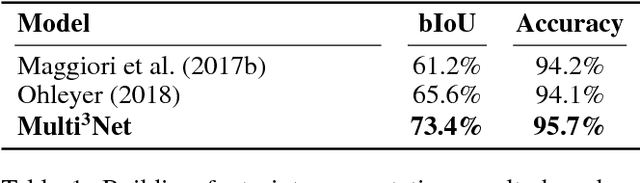
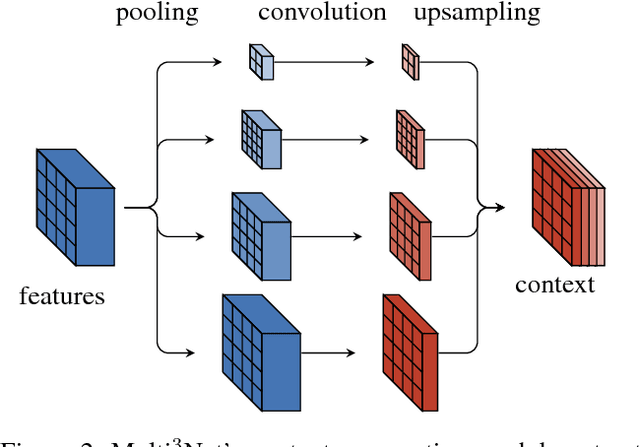
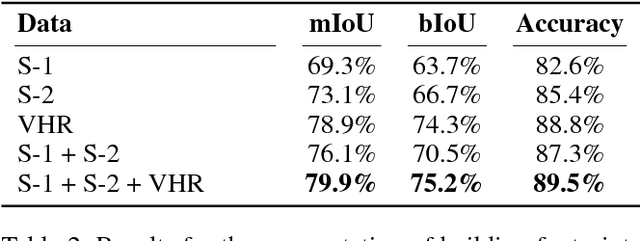
We propose a novel approach for rapid segmentation of flooded buildings by fusing multiresolution, multisensor, and multitemporal satellite imagery in a convolutional neural network. Our model significantly expedites the generation of satellite imagery-based flood maps, crucial for first responders and local authorities in the early stages of flood events. By incorporating multitemporal satellite imagery, our model allows for rapid and accurate post-disaster damage assessment and can be used by governments to better coordinate medium- and long-term financial assistance programs for affected areas. The network consists of multiple streams of encoder-decoder architectures that extract spatiotemporal information from medium-resolution images and spatial information from high-resolution images before fusing the resulting representations into a single medium-resolution segmentation map of flooded buildings. We compare our model to state-of-the-art methods for building footprint segmentation as well as to alternative fusion approaches for the segmentation of flooded buildings and find that our model performs best on both tasks. We also demonstrate that our model produces highly accurate segmentation maps of flooded buildings using only publicly available medium-resolution data instead of significantly more detailed but sparsely available very high-resolution data. We release the first open-source dataset of fully preprocessed and labeled multiresolution, multispectral, and multitemporal satellite images of disaster sites along with our source code.
Overcoming Missing and Incomplete Modalities with Generative Adversarial Networks for Building Footprint Segmentation
Aug 09, 2018



The integration of information acquired with different modalities, spatial resolution and spectral bands has shown to improve predictive accuracies. Data fusion is therefore one of the key challenges in remote sensing. Most prior work focusing on multi-modal fusion, assumes that modalities are always available during inference. This assumption limits the applications of multi-modal models since in practice the data collection process is likely to generate data with missing, incomplete or corrupted modalities. In this paper, we show that Generative Adversarial Networks can be effectively used to overcome the problems that arise when modalities are missing or incomplete. Focusing on semantic segmentation of building footprints with missing modalities, our approach achieves an improvement of about 2% on the Intersection over Union (IoU) against the same network that relies only on the available modality.
Multi-Task Learning for Segmentation of Building Footprints with Deep Neural Networks
Sep 18, 2017

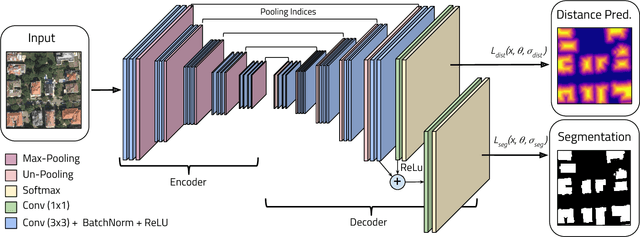

The increased availability of high resolution satellite imagery allows to sense very detailed structures on the surface of our planet. Access to such information opens up new directions in the analysis of remote sensing imagery. However, at the same time this raises a set of new challenges for existing pixel-based prediction methods, such as semantic segmentation approaches. While deep neural networks have achieved significant advances in the semantic segmentation of high resolution images in the past, most of the existing approaches tend to produce predictions with poor boundaries. In this paper, we address the problem of preserving semantic segmentation boundaries in high resolution satellite imagery by introducing a new cascaded multi-task loss. We evaluate our approach on Inria Aerial Image Labeling Dataset which contains large-scale and high resolution images. Our results show that we are able to outperform state-of-the-art methods by 8.3\% without any additional post-processing step.