 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS$^3$Track: Self-supervised Tracking with Soft Assignment Flow
May 17, 2023



In this work, we study self-supervised multiple object tracking without using any video-level association labels. We propose to cast the problem of multiple object tracking as learning the frame-wise associations between detections in consecutive frames. To this end, we propose differentiable soft object assignment for object association, making it possible to learn features tailored to object association with differentiable end-to-end training. With this training approach in hand, we develop an appearance-based model for learning instance-aware object features used to construct a cost matrix based on the pairwise distances between the object features. We train our model using temporal and multi-view data, where we obtain association pseudo-labels using optical flow and disparity information. Unlike most self-supervised tracking methods that rely on pretext tasks for learning the feature correspondences, our method is directly optimized for cross-object association in complex scenarios. As such, the proposed method offers a reidentification-based MOT approach that is robust to training hyperparameters and does not suffer from local minima, which are a challenge in self-supervised methods. We evaluate our proposed model on the KITTI, Waymo, nuScenes, and Argoverse datasets, consistently improving over other unsupervised methods ($7.8\%$ improvement in association accuracy on nuScenes).
Spatial Transformer Networks for Curriculum Learning
Aug 22, 2021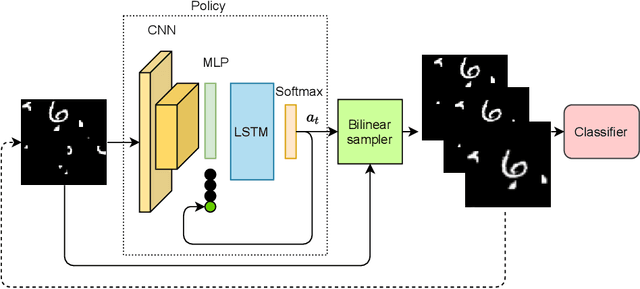



Curriculum learning is a bio-inspired training technique that is widely adopted to machine learning for improved optimization and better training of neural networks regarding the convergence rate or obtained accuracy. The main concept in curriculum learning is to start the training with simpler tasks and gradually increase the level of difficulty. Therefore, a natural question is how to determine or generate these simpler tasks. In this work, we take inspiration from Spatial Transformer Networks (STNs) in order to form an easy-to-hard curriculum. As STNs have been proven to be capable of removing the clutter from the input images and obtaining higher accuracy in image classification tasks, we hypothesize that images processed by STNs can be seen as easier tasks and utilized in the interest of curriculum learning. To this end, we study multiple strategies developed for shaping the training curriculum, using the data generated by STNs. We perform various experiments on cluttered MNIST and Fashion-MNIST datasets, where on the former, we obtain an improvement of $3.8$pp in classification accuracy compared to the baseline.
A Reinforcement Learning Approach for Sequential Spatial Transformer Networks
Jun 27, 2021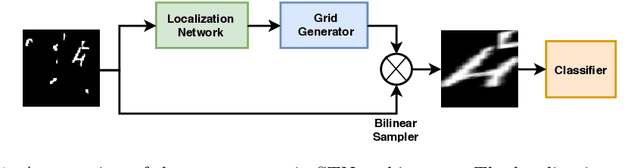

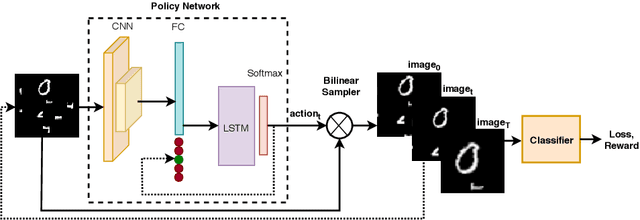

Spatial Transformer Networks (STN) can generate geometric transformations which modify input images to improve the classifier's performance. In this work, we combine the idea of STN with Reinforcement Learning (RL). To this end, we break the affine transformation down into a sequence of simple and discrete transformations. We formulate the task as a Markovian Decision Process (MDP) and use RL to solve this sequential decision-making problem. STN architectures learn the transformation parameters by minimizing the classification error and backpropagating the gradients through a sub-differentiable sampling module. In our method, we are not bound to the differentiability of the sampling modules. Moreover, we have freedom in designing the objective rather than only minimizing the error; e.g., we can directly set the target as maximizing the accuracy. We design multiple experiments to verify the effectiveness of our method using cluttered MNIST and Fashion-MNIST datasets and show that our method outperforms STN with a proper definition of MDP components.
Hybrid Sequence to Sequence Model for Video Object Segmentation
Oct 10, 2020


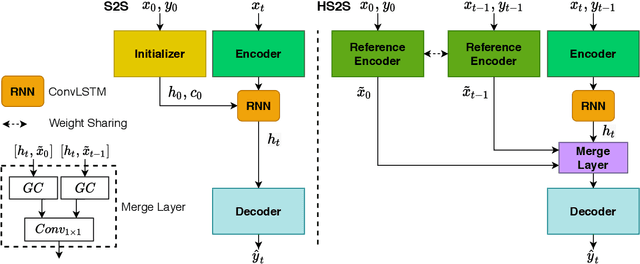
One-shot Video Object Segmentation (VOS) is the task of pixel-wise tracking an object of interest within a video sequence, where the segmentation mask of the first frame is given at inference time. In recent years, Recurrent Neural Networks (RNNs) have been widely used for VOS tasks, but they often suffer from limitations such as drift and error propagation. In this work, we study an RNN-based architecture and address some of these issues by proposing a hybrid sequence-to-sequence architecture named HS2S, utilizing a hybrid mask propagation strategy that allows incorporating the information obtained from correspondence matching. Our experiments show that augmenting the RNN with correspondence matching is a highly effective solution to reduce the drift problem. The additional information helps the model to predict more accurate masks and makes it robust against error propagation. We evaluate our HS2S model on the DAVIS2017 dataset as well as Youtube-VOS. On the latter, we achieve an improvement of 11.2pp in the overall segmentation accuracy over RNN-based state-of-the-art methods in VOS. We analyze our model's behavior in challenging cases such as occlusion and long sequences and show that our hybrid architecture significantly enhances the segmentation quality in these difficult scenarios.
Revisiting Sequence-to-Sequence Video Object Segmentation with Multi-Task Loss and Skip-Memory
Apr 25, 2020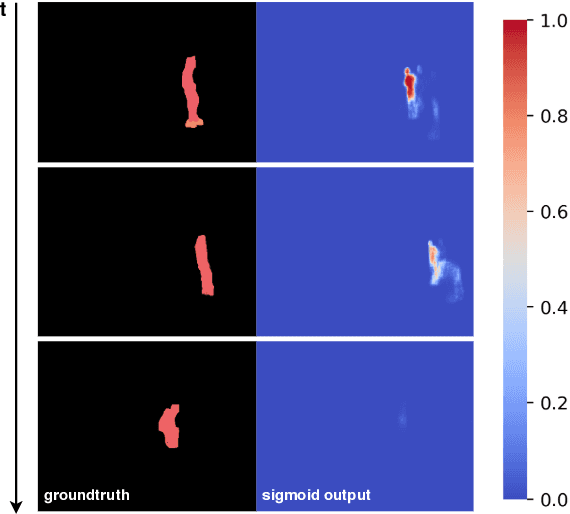
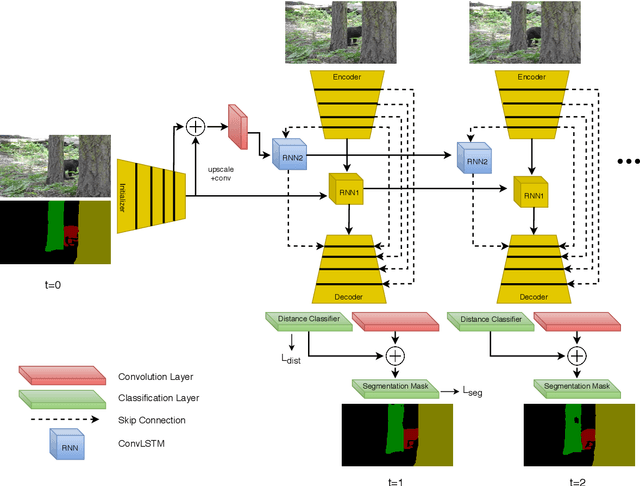
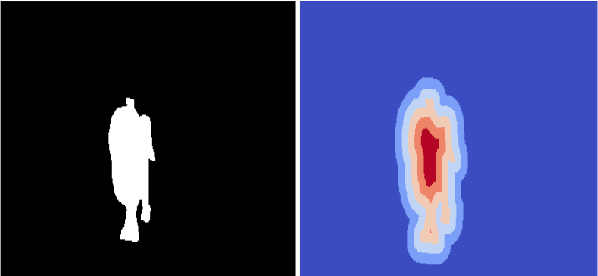

Video Object Segmentation (VOS) is an active research area of the visual domain. One of its fundamental sub-tasks is semi-supervised / one-shot learning: given only the segmentation mask for the first frame, the task is to provide pixel-accurate masks for the object over the rest of the sequence. Despite much progress in the last years, we noticed that many of the existing approaches lose objects in longer sequences, especially when the object is small or briefly occluded. In this work, we build upon a sequence-to-sequence approach that employs an encoder-decoder architecture together with a memory module for exploiting the sequential data. We further improve this approach by proposing a model that manipulates multi-scale spatio-temporal information using memory-equipped skip connections. Furthermore, we incorporate an auxiliary task based on distance classification which greatly enhances the quality of edges in segmentation masks. We compare our approach to the state of the art and show considerable improvement in the contour accuracy metric and the overall segmentation accuracy.