 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Coreset Selection of Coreset Selection Literature: Introduction and Recent Advances
May 23, 2025Coreset selection targets the challenge of finding a small, representative subset of a large dataset that preserves essential patterns for effective machine learning. Although several surveys have examined data reduction strategies before, most focus narrowly on either classical geometry-based methods or active learning techniques. In contrast, this survey presents a more comprehensive view by unifying three major lines of coreset research, namely, training-free, training-oriented, and label-free approaches, into a single taxonomy. We present subfields often overlooked by existing work, including submodular formulations, bilevel optimization, and recent progress in pseudo-labeling for unlabeled datasets. Additionally, we examine how pruning strategies influence generalization and neural scaling laws, offering new insights that are absent from prior reviews. Finally, we compare these methods under varying computational, robustness, and performance demands and highlight open challenges, such as robustness, outlier filtering, and adapting coreset selection to foundation models, for future research.
Training Deep Neural Networks Without Batch Normalization
Aug 18, 2020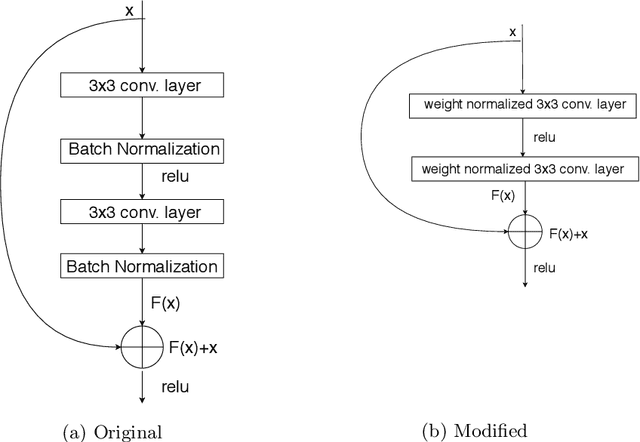



Training neural networks is an optimization problem, and finding a decent set of parameters through gradient descent can be a difficult task. A host of techniques has been developed to aid this process before and during the training phase. One of the most important and widely used class of method is normalization. It is generally favorable for neurons to receive inputs that are distributed with zero mean and unit variance, so we use statistics about dataset to normalize them before the first layer. However, this property cannot be guaranteed for the intermediate activations inside the network. A widely used method to enforce this property inside the network is batch normalization. It was developed to combat covariate shift inside networks. Empirically it is known to work, but there is a lack of theoretical understanding about its effectiveness and potential drawbacks it might have when used in practice. This work studies batch normalization in detail, while comparing it with other methods such as weight normalization, gradient clipping and dropout. The main purpose of this work is to determine if it is possible to train networks effectively when batch normalization is removed through adaption of the training process.
P $\approx$ NP, at least in Visual Question Answering
Mar 27, 2020
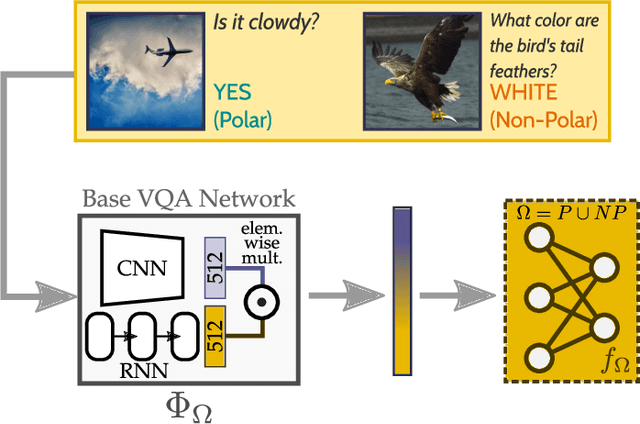
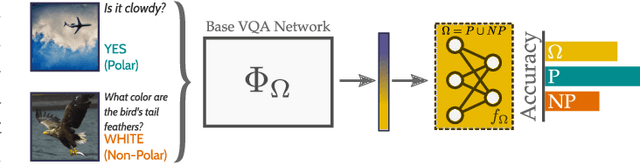
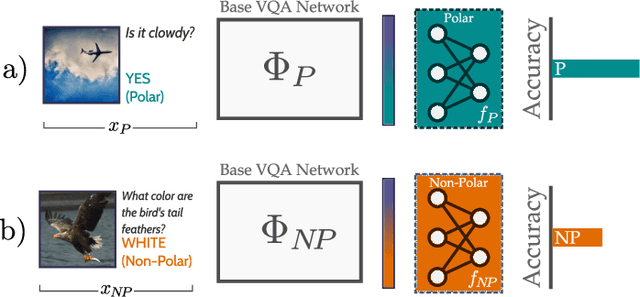
In recent years, progress in the Visual Question Answering (VQA) field has largely been driven by public challenges and large datasets. One of the most widely-used of these is the VQA 2.0 dataset, consisting of polar ("yes/no") and non-polar questions. Looking at the question distribution over all answers, we find that the answers "yes" and "no" account for 38 % of the questions, while the remaining 62% are spread over the more than 3000 remaining answers. While several sources of biases have already been investigated in the field, the effects of such an over-representation of polar vs. non-polar questions remain unclear. In this paper, we measure the potential confounding factors when polar and non-polar samples are used jointly to train a baseline VQA classifier, and compare it to an upper bound where the over-representation of polar questions is excluded from the training. Further, we perform cross-over experiments to analyze how well the feature spaces align. Contrary to expectations, we find no evidence of counterproductive effects in the joint training of unbalanced classes. In fact, by exploring the intermediate feature space of visual-text embeddings, we find that the feature space of polar questions already encodes sufficient structure to answer many non-polar questions. Our results indicate that the polar (P) and the non-polar (NP) feature spaces are strongly aligned, hence the expression P $\approx$ NP
What do Deep Networks Like to See?
Mar 22, 2018

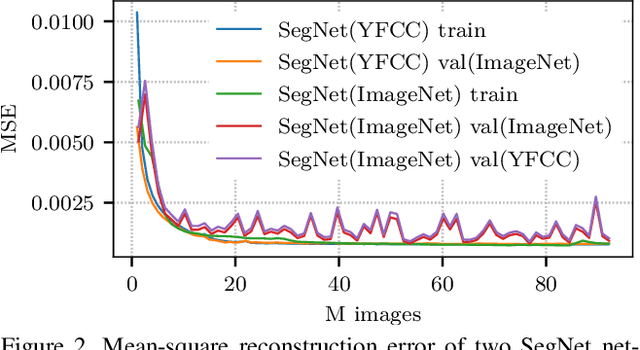

We propose a novel way to measure and understand convolutional neural networks by quantifying the amount of input signal they let in. To do this, an autoencoder (AE) was fine-tuned on gradients from a pre-trained classifier with fixed parameters. We compared the reconstructed samples from AEs that were fine-tuned on a set of image classifiers (AlexNet, VGG16, ResNet-50, and Inception~v3) and found substantial differences. The AE learns which aspects of the input space to preserve and which ones to ignore, based on the information encoded in the backpropagated gradients. Measuring the changes in accuracy when the signal of one classifier is used by a second one, a relation of total order emerges. This order depends directly on each classifier's input signal but it does not correlate with classification accuracy or network size. Further evidence of this phenomenon is provided by measuring the normalized mutual information between original images and auto-encoded reconstructions from different fine-tuned AEs. These findings break new ground in the area of neural network understanding, opening a new way to reason, debug, and interpret their results. We present four concrete examples in the literature where observations can now be explained in terms of the input signal that a model uses.
Adversarial Defense based on Structure-to-Signal Autoencoders
Mar 21, 2018


Adversarial attack methods have demonstrated the fragility of deep neural networks. Their imperceptible perturbations are frequently able fool classifiers into potentially dangerous misclassifications. We propose a novel way to interpret adversarial perturbations in terms of the effective input signal that classifiers actually use. Based on this, we apply specially trained autoencoders, referred to as S2SNets, as defense mechanism. They follow a two-stage training scheme: first unsupervised, followed by a fine-tuning of the decoder, using gradients from an existing classifier. S2SNets induce a shift in the distribution of gradients propagated through them, stripping them from class-dependent signal. We analyze their robustness against several white-box and gray-box scenarios on the large ImageNet dataset. Our approach reaches comparable resilience in white-box attack scenarios as other state-of-the-art defenses in gray-box scenarios. We further analyze the relationships of AlexNet, VGG 16, ResNet 50 and Inception v3 in adversarial space, and found that VGG 16 is the easiest to fool, while perturbations from ResNet 50 are the most transferable.
Multi-Task Learning for Segmentation of Building Footprints with Deep Neural Networks
Sep 18, 2017

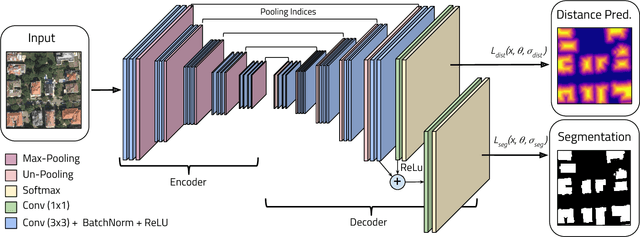

The increased availability of high resolution satellite imagery allows to sense very detailed structures on the surface of our planet. Access to such information opens up new directions in the analysis of remote sensing imagery. However, at the same time this raises a set of new challenges for existing pixel-based prediction methods, such as semantic segmentation approaches. While deep neural networks have achieved significant advances in the semantic segmentation of high resolution images in the past, most of the existing approaches tend to produce predictions with poor boundaries. In this paper, we address the problem of preserving semantic segmentation boundaries in high resolution satellite imagery by introducing a new cascaded multi-task loss. We evaluate our approach on Inria Aerial Image Labeling Dataset which contains large-scale and high resolution images. Our results show that we are able to outperform state-of-the-art methods by 8.3\% without any additional post-processing step.
An Evolutionary Algorithm to Learn SPARQL Queries for Source-Target-Pairs: Finding Patterns for Human Associations in DBpedia
Sep 13, 2016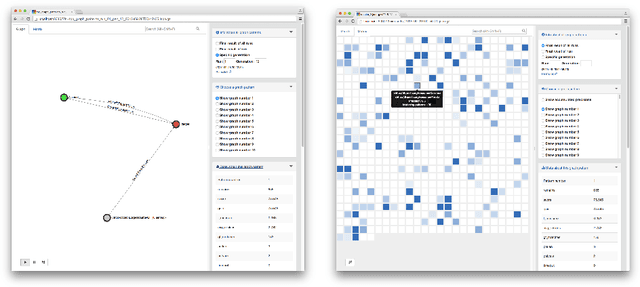

Efficient usage of the knowledge provided by the Linked Data community is often hindered by the need for domain experts to formulate the right SPARQL queries to answer questions. For new questions they have to decide which datasets are suitable and in which terminology and modelling style to phrase the SPARQL query. In this work we present an evolutionary algorithm to help with this challenging task. Given a training list of source-target node-pair examples our algorithm can learn patterns (SPARQL queries) from a SPARQL endpoint. The learned patterns can be visualised to form the basis for further investigation, or they can be used to predict target nodes for new source nodes. Amongst others, we apply our algorithm to a dataset of several hundred human associations (such as "circle - square") to find patterns for them in DBpedia. We show the scalability of the algorithm by running it against a SPARQL endpoint loaded with > 7.9 billion triples. Further, we use the resulting SPARQL queries to mimic human associations with a Mean Average Precision (MAP) of 39.9 % and a Recall@10 of 63.9 %.