 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding SEC Actions: Enforcement Trends through Analyzing Blockchain litigation using LLM-based Thematic Factor Mapping
Aug 21, 2024

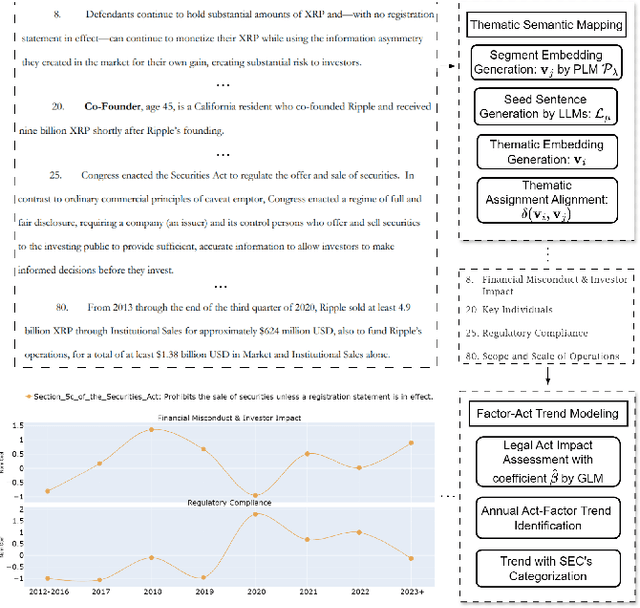

The proliferation of blockchain entities (persons or enterprises) exposes them to potential regulatory actions (e.g., being litigated) by regulatory authorities. Regulatory frameworks for crypto assets are actively being developed and refined, increasing the likelihood of such actions. The lack of systematic analysis of the factors driving litigation against blockchain entities leaves companies in need of clarity to navigate compliance risks. This absence of insight also deprives investors of the information for informed decision-making. This study focuses on U.S. litigation against blockchain entities, particularly by the U.S. Securities and Exchange Commission (SEC) given its influence on global crypto regulation. Utilizing frontier pretrained language models and large language models, we systematically map all SEC complaints against blockchain companies from 2012 to 2024 to thematic factors conceptualized by our study to delineate the factors driving SEC actions. We quantify the thematic factors and assess their influence on specific legal Acts cited within the complaints on an annual basis, allowing us to discern the regulatory emphasis, patterns and conduct trend analysis.
Investigating Similarities Across Decentralized Financial (DeFi) Services
Mar 23, 2024



We explore the adoption of graph representation learning (GRL) algorithms to investigate similarities across services offered by Decentralized Finance (DeFi) protocols. Following existing literature, we use Ethereum transaction data to identify the DeFi building blocks. These are sets of protocol-specific smart contracts that are utilized in combination within single transactions and encapsulate the logic to conduct specific financial services such as swapping or lending cryptoassets. We propose a method to categorize these blocks into clusters based on their smart contract attributes and the graph structure of their smart contract calls. We employ GRL to create embedding vectors from building blocks and agglomerative models for clustering them. To evaluate whether they are effectively grouped in clusters of similar functionalities, we associate them with eight financial functionality categories and use this information as the target label. We find that in the best-case scenario purity reaches .888. We use additional information to associate the building blocks with protocol-specific target labels, obtaining comparable purity (.864) but higher V-Measure (.571); we discuss plausible explanations for this difference. In summary, this method helps categorize existing financial products offered by DeFi protocols, and can effectively automatize the detection of similar DeFi services, especially within protocols.
Hallucination Detection and Hallucination Mitigation: An Investigation
Jan 16, 2024Large language models (LLMs), including ChatGPT, Bard, and Llama, have achieved remarkable successes over the last two years in a range of different applications. In spite of these successes, there exist concerns that limit the wide application of LLMs. A key problem is the problem of hallucination. Hallucination refers to the fact that in addition to correct responses, LLMs can also generate seemingly correct but factually incorrect responses. This report aims to present a comprehensive review of the current literature on both hallucination detection and hallucination mitigation. We hope that this report can serve as a good reference for both engineers and researchers who are interested in LLMs and applying them to real world tasks.
Towards Improved Illicit Node Detection with Positive-Unlabelled Learning
Mar 15, 2023



Detecting illicit nodes on blockchain networks is a valuable task for strengthening future regulation. Recent machine learning-based methods proposed to tackle the tasks are using some blockchain transaction datasets with a small portion of samples labeled positive and the rest unlabelled (PU). Albeit the assumption that a random sample of unlabeled nodes are normal nodes is used in some works, we discuss that the label mechanism assumption for the hidden positive labels and its effect on the evaluation metrics is worth considering. We further explore that PU classifiers dealing with potential hidden positive labels can have improved performance compared to regular machine learning models. We test the PU classifiers with a list of graph representation learning methods for obtaining different feature distributions for the same data to have more reliable results.