 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIS-HAR: Transmissive Reconfigurable Intelligent Surfaces-assisted Cognitive Wireless Human Activity Recognition Using State Space Models
Oct 03, 2024



Human activity recognition (HAR) using radio frequency (RF) signals has garnered considerable attention for its applications in smart environments. However, traditional systems often struggle with limited independent channels between transmitters and receivers, multipath fading, and environmental noise, which particularly degrades performance in through-the-wall scenarios. In this paper, we present a transmissive reconfigurable intelligent surface (TRIS)-assisted through-the-wall human activity recognition (TRIS-HAR) system. The system employs TRIS technology to actively reshape wireless signal propagation, creating multiple independent paths to enhance signal clarity and improve recognition accuracy in complex indoor settings. Additionally, we propose the Human intelligence Mamba (HiMamba), an advanced state space model that captures temporal and frequency-based information for precise activity recognition. HiMamba achieves state-of-the-art performance on two public datasets, demonstrating superior accuracy. Extensive experiments indicate that the TRIS-HAR system improves recognition performance from 85.00% to 98.06% in laboratory conditions and maintains high performance across various environments. This approach offers a robust solution for enhancing RF-based HAR, with promising applications in smart home and elderly care systems.
PoseMamba: Monocular 3D Human Pose Estimation with Bidirectional Global-Local Spatio-Temporal State Space Model
Aug 07, 2024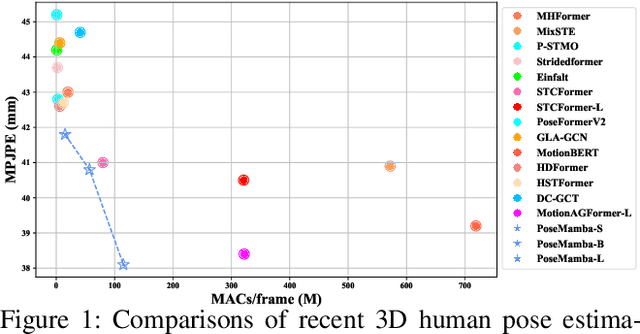

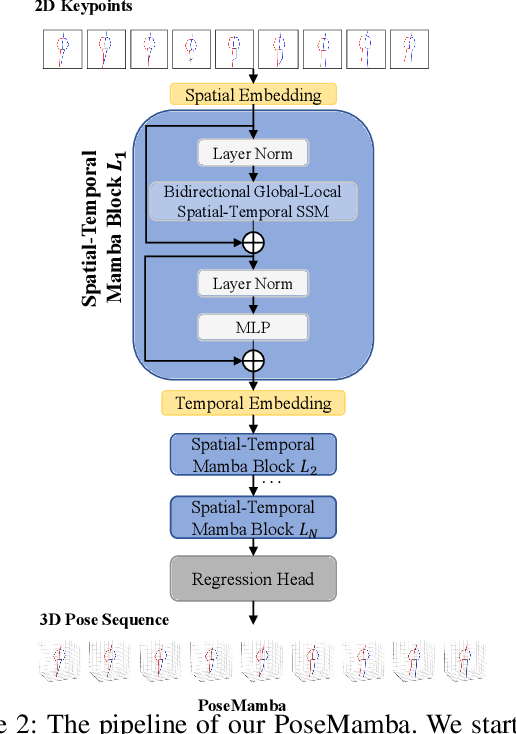

Transformers have significantly advanced the field of 3D human pose estimation (HPE). However, existing transformer-based methods primarily use self-attention mechanisms for spatio-temporal modeling, leading to a quadratic complexity, unidirectional modeling of spatio-temporal relationships, and insufficient learning of spatial-temporal correlations. Recently, the Mamba architecture, utilizing the state space model (SSM), has exhibited superior long-range modeling capabilities in a variety of vision tasks with linear complexity. In this paper, we propose PoseMamba, a novel purely SSM-based approach with linear complexity for 3D human pose estimation in monocular video. Specifically, we propose a bidirectional global-local spatio-temporal SSM block that comprehensively models human joint relations within individual frames as well as temporal correlations across frames. Within this bidirectional global-local spatio-temporal SSM block, we introduce a reordering strategy to enhance the local modeling capability of the SSM. This strategy provides a more logical geometric scanning order and integrates it with the global SSM, resulting in a combined global-local spatial scan. We have quantitatively and qualitatively evaluated our approach using two benchmark datasets: Human3.6M and MPI-INF-3DHP. Extensive experiments demonstrate that PoseMamba achieves state-of-the-art performance on both datasets while maintaining a smaller model size and reducing computational costs. The code and models will be released.
TRGR: Transmissive RIS-aided Gait Recognition Through Walls
Jul 31, 2024



Gait recognition with radio frequency (RF) signals enables many potential applications requiring accurate identification. However, current systems require individuals to be within a line-of-sight (LOS) environment and struggle with low signal-to-noise ratio (SNR) when signals traverse concrete and thick walls. To address these challenges, we present TRGR, a novel transmissive reconfigurable intelligent surface (RIS)-aided gait recognition system. TRGR can recognize human identities through walls using only the magnitude measurements of channel state information (CSI) from a pair of transceivers. Specifically, by leveraging transmissive RIS alongside a configuration alternating optimization algorithm, TRGR enhances wall penetration and signal quality, enabling accurate gait recognition. Furthermore, a residual convolution network (RCNN) is proposed as the backbone network to learn robust human information. Experimental results confirm the efficacy of transmissive RIS, highlighting the significant potential of transmissive RIS in enhancing RF-based gait recognition systems. Extensive experiment results show that TRGR achieves an average accuracy of 97.88\% in identifying persons when signals traverse concrete walls, demonstrating the effectiveness and robustness of TRGR.
Dreamer: Dual-RIS-aided Imager in Complementary Modes
Jul 20, 2024Reconfigurable intelligent surfaces (RISs) have emerged as a promising auxiliary technology for radio frequency imaging. However, existing works face challenges of faint and intricate back-scattered waves and the restricted field-of-view (FoV), both resulting from complex target structures and a limited number of antennas. The synergistic benefits of multi-RIS-aided imaging hold promise for addressing these challenges. Here, we propose a dual-RIS-aided imaging system, Dreamer, which operates collaboratively in complementary modes (reflection-mode and transmission-mode). Dreamer significantly expands the FoV and enhances perception by deploying dual-RIS across various spatial and measurement patterns. Specifically, we perform a fine-grained analysis of how radio-frequency (RF) signals encode scene information in the scattered object modeling. Based on this modeling, we design illumination strategies to balance spatial resolution and observation scale, and implement a prototype system in a typical indoor environment. Moreover, we design a novel artificial neural network with a CNN-external-attention mechanism to translate RF signals into high-resolution images of human contours. Our approach achieves an impressive SSIM score exceeding 0.83, validating its effectiveness in broadening perception modes and enhancing imaging capabilities. The code to reproduce our results is available at https://github.com/fuhaiwang/Dreamer.
Semantic Network Model for Sign Language Comprehension
Jan 27, 2023
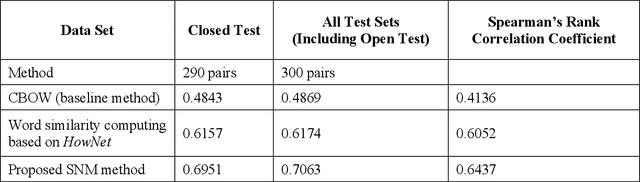
In this study, the authors propose a computational cognitive model for sign language (SL) perception and comprehension with detailed algorithmic descriptions based on cognitive functionalities in human language processing. The semantic network model (SNM) that represents semantic relations between concepts, it is used as a form of knowledge representation. The proposed model is applied in the comprehension of sign language for classifier predicates. The spreading activation search method is initiated by labeling a set of source nodes (e.g. concepts in the semantic network) with weights or "activation" and then iteratively propagating or "spreading" that activation out to other nodes linked to the source nodes. The results demonstrate that the proposed search method improves the performance of sign language comprehension in the SNM.
* 19 pages, 6 figures and 1 table
Inter-Carrier Interference Mitigation for Differentially Coherent Detection in Underwater Acoustic OFDM Systems
Mar 07, 2021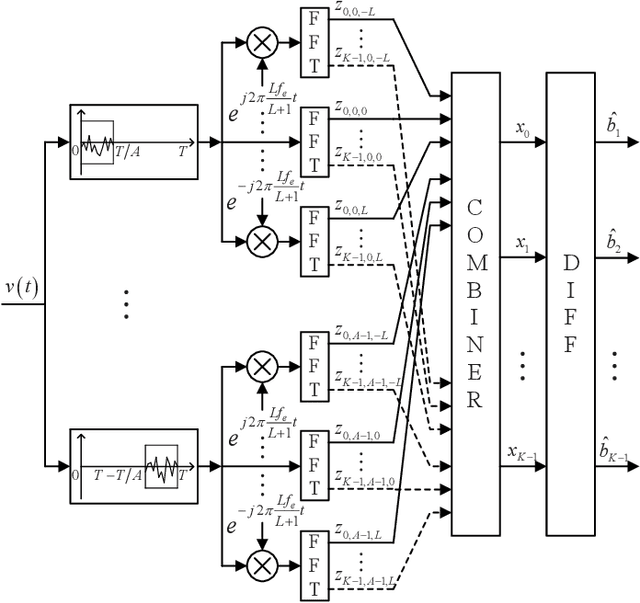

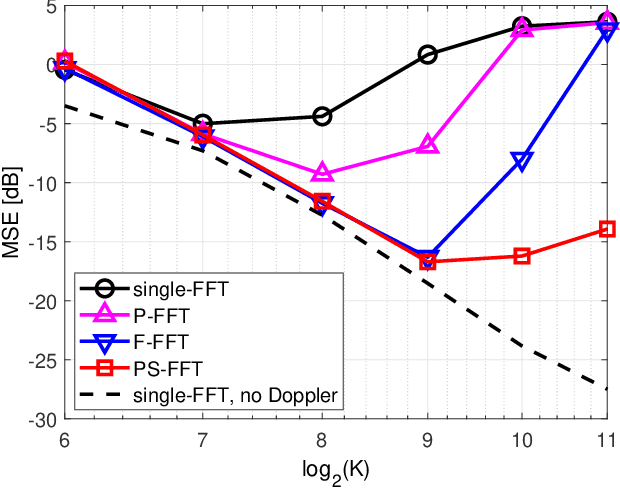
Suppressing the inter-carrier interference (ICI) is crucial for differentially coherent detection in underwater acoustic (UWA) orthogonal frequency division multiplexing (OFDM) systems due to the fact that the UWA channel is inherently violently Doppler-shifted. In this paper, we propose a new ICI suppression method, referred to as the partially-shifted fast Fourier transform (PS-FFT), which eliminates the ICI from both the time and frequency domains. Specifically, the PS-FFT first divides the received signal in the entire block duration into several short non-overlapping ones to reduce the channel variation in the time domain. It then applies the Fourier transform at several predefined frequencies to the received signal in each of these intervals to compensate Doppler shifts in the frequency domain. Finally, it weightedly combines the multiple demodulator outputs at each carrier as one output for symbol detection, with the combiner weights being solved by the stochastic gradient algorithm. Simulation results show that the PS-FFT dramatically outperforms the existing classical methods, the partial fast Fourier transform (P-FFT) and the fractional fast Fourier transform (F-FFT), for both medium and high Doppler factors and large carrier numbers in terms of the mean squared error (MSE). Numerically, the MSE of the PS-FFT is reduced by $\bf{61.83\%-84.89\%}$ compared to that of the F-FFT when the input signal-to-noise ratio (SNR) at the receiver ranges from 10 dB to 30 dB at a Doppler factor of $\bf{3\times 10^{-4}}$ and a carrier number of 1024 where the P-FFT even cannot work.
A Lane-Change Path Planner and its application with a monocular camera
Mar 10, 2019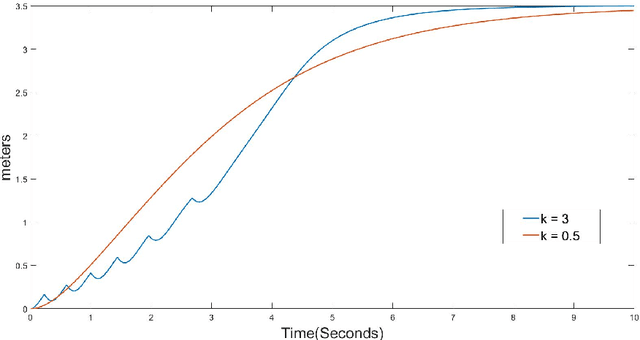
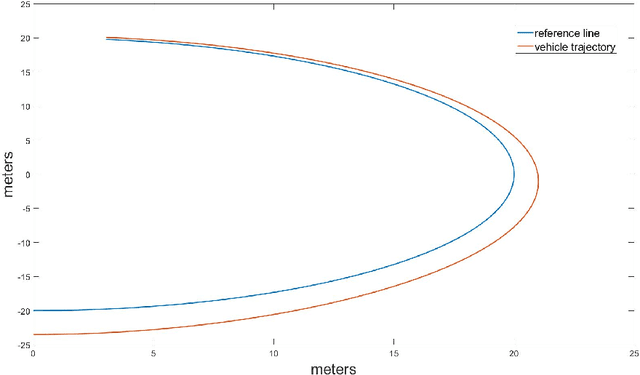
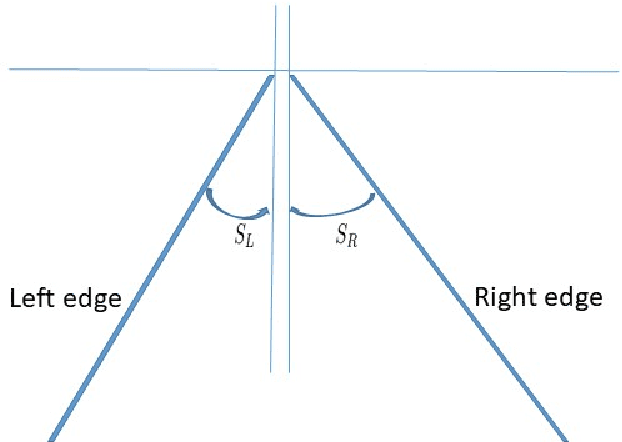
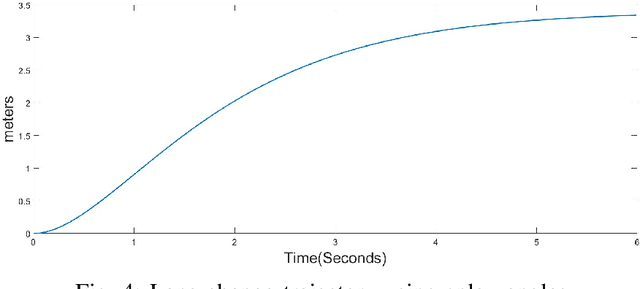
Human drivers utilize the visual cues from the road to performance some fundamental driving tasks, e.g. lane keeping and lane change, for the complex driving maneuvers. Lane keeping and lane change can be generalized as one task, because both of them are to drive a vehicle onto a target lane. In this paper, we first design a lane-change path planner based on HD (High-Definition) map for autonomous driving systems using control theory. Later, applying the similar idea, a lane change controller using a monocular camera is designed.