 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRC-NF: Robot-Conditioned Normalizing Flow for Real-Time Anomaly Detection in Robotic Manipulation
Mar 11, 2026Recent advances in Vision-Language-Action (VLA) models have enabled robots to execute increasingly complex tasks. However, VLA models trained through imitation learning struggle to operate reliably in dynamic environments and often fail under Out-of-Distribution (OOD) conditions. To address this issue, we propose Robot-Conditioned Normalizing Flow (RC-NF), a real-time monitoring model for robotic anomaly detection and intervention that ensures the robot's state and the object's motion trajectory align with the task. RC-NF decouples the processing of task-aware robot and object states within the normalizing flow. It requires only positive samples for unsupervised training and calculates accurate robotic anomaly scores during inference through the probability density function. We further present LIBERO-Anomaly-10, a benchmark comprising three categories of robotic anomalies for simulation evaluation. RC-NF achieves state-of-the-art performance across all anomaly types compared to previous methods in monitoring robotic tasks. Real-world experiments demonstrate that RC-NF operates as a plug-and-play module for VLA models (e.g., pi0), providing a real-time OOD signal that enables state-level rollback or task-level replanning when necessary, with a response latency under 100 ms. These results demonstrate that RC-NF noticeably enhances the robustness and adaptability of VLA-based robotic systems in dynamic environments.
RadarLLM: Empowering Large Language Models to Understand Human Motion from Millimeter-wave Point Cloud Sequence
Apr 14, 2025Millimeter-wave radar provides a privacy-preserving solution for human motion analysis, yet its sparse point clouds pose significant challenges for semantic understanding. We present Radar-LLM, the first framework that leverages large language models (LLMs) for human motion understanding using millimeter-wave radar as the sensing modality. Our approach introduces two key innovations: (1) a motion-guided radar tokenizer based on our Aggregate VQ-VAE architecture that incorporates deformable body templates and masked trajectory modeling to encode spatiotemporal point clouds into compact semantic tokens, and (2) a radar-aware language model that establishes cross-modal alignment between radar and text in a shared embedding space. To address data scarcity, we introduce a physics-aware synthesis pipeline that generates realistic radar-text pairs from motion-text datasets. Extensive experiments demonstrate that Radar-LLM achieves state-of-the-art performance across both synthetic and real-world benchmarks, enabling accurate translation of millimeter-wave signals to natural language descriptions. This breakthrough facilitates comprehensive motion understanding in privacy-sensitive applications like healthcare and smart homes. We will release the full implementation to support further research on https://inowlzy.github.io/RadarLLM/.
Suite-IN++: A FlexiWear BodyNet Integrating Global and Local Motion Features from Apple Suite for Robust Inertial Navigation
Apr 01, 2025



The proliferation of wearable technology has established multi-device ecosystems comprising smartphones, smartwatches, and headphones as critical enablers for ubiquitous pedestrian localization. However, traditional pedestrian dead reckoning (PDR) struggles with diverse motion modes, while data-driven methods, despite improving accuracy, often lack robustness due to their reliance on a single-device setup. Therefore, a promising solution is to fully leverage existing wearable devices to form a flexiwear bodynet for robust and accurate pedestrian localization. This paper presents Suite-IN++, a deep learning framework for flexiwear bodynet-based pedestrian localization. Suite-IN++ integrates motion data from wearable devices on different body parts, using contrastive learning to separate global and local motion features. It fuses global features based on the data reliability of each device to capture overall motion trends and employs an attention mechanism to uncover cross-device correlations in local features, extracting motion details helpful for accurate localization. To evaluate our method, we construct a real-life flexiwear bodynet dataset, incorporating Apple Suite (iPhone, Apple Watch, and AirPods) across diverse walking modes and device configurations. Experimental results demonstrate that Suite-IN++ achieves superior localization accuracy and robustness, significantly outperforming state-of-the-art models in real-life pedestrian tracking scenarios.
mmDEAR: mmWave Point Cloud Density Enhancement for Accurate Human Body Reconstruction
Mar 04, 2025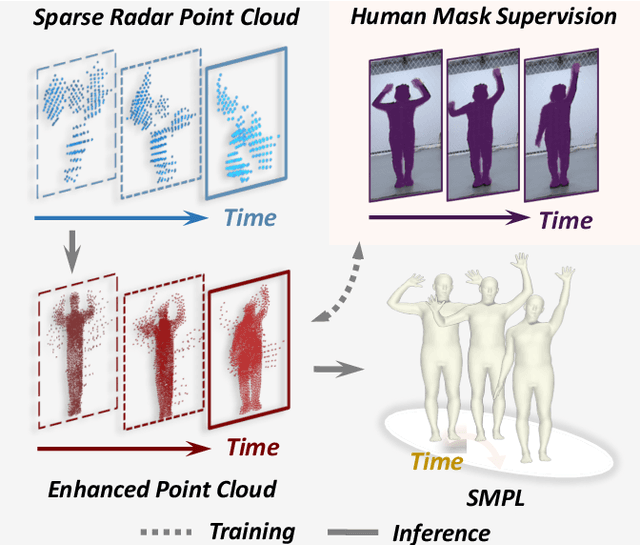

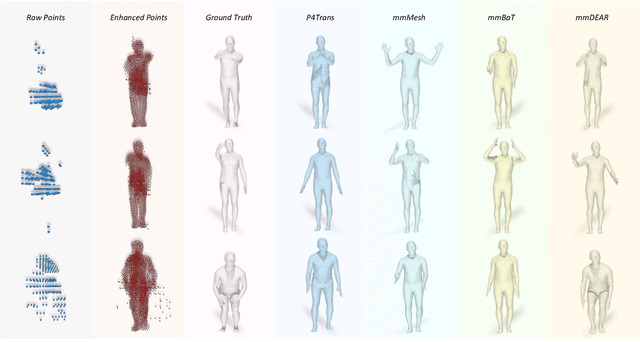
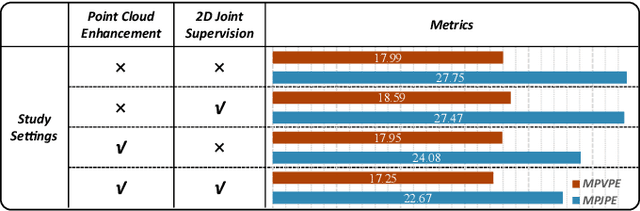
Millimeter-wave (mmWave) radar offers robust sensing capabilities in diverse environments, making it a highly promising solution for human body reconstruction due to its privacy-friendly and non-intrusive nature. However, the significant sparsity of mmWave point clouds limits the estimation accuracy. To overcome this challenge, we propose a two-stage deep learning framework that enhances mmWave point clouds and improves human body reconstruction accuracy. Our method includes a mmWave point cloud enhancement module that densifies the raw data by leveraging temporal features and a multi-stage completion network, followed by a 2D-3D fusion module that extracts both 2D and 3D motion features to refine SMPL parameters. The mmWave point cloud enhancement module learns the detailed shape and posture information from 2D human masks in single-view images. However, image-based supervision is involved only during the training phase, and the inference relies solely on sparse point clouds to maintain privacy. Experiments on multiple datasets demonstrate that our approach outperforms state-of-the-art methods, with the enhanced point clouds further improving performance when integrated into existing models.
AlphaAgent: LLM-Driven Alpha Mining with Regularized Exploration to Counteract Alpha Decay
Feb 24, 2025Alpha mining, a critical component in quantitative investment, focuses on discovering predictive signals for future asset returns in increasingly complex financial markets. However, the pervasive issue of alpha decay, where factors lose their predictive power over time, poses a significant challenge for alpha mining. Traditional methods like genetic programming face rapid alpha decay from overfitting and complexity, while approaches driven by Large Language Models (LLMs), despite their promise, often rely too heavily on existing knowledge, creating homogeneous factors that worsen crowding and accelerate decay. To address this challenge, we propose AlphaAgent, an autonomous framework that effectively integrates LLM agents with ad hoc regularizations for mining decay-resistant alpha factors. AlphaAgent employs three key mechanisms: (i) originality enforcement through a similarity measure based on abstract syntax trees (ASTs) against existing alphas, (ii) hypothesis-factor alignment via LLM-evaluated semantic consistency between market hypotheses and generated factors, and (iii) complexity control via AST-based structural constraints, preventing over-engineered constructions that are prone to overfitting. These mechanisms collectively guide the alpha generation process to balance originality, financial rationale, and adaptability to evolving market conditions, mitigating the risk of alpha decay. Extensive evaluations show that AlphaAgent outperforms traditional and LLM-based methods in mitigating alpha decay across bull and bear markets, consistently delivering significant alpha in Chinese CSI 500 and US S&P 500 markets over the past four years. Notably, AlphaAgent showcases remarkable resistance to alpha decay, elevating the potential for yielding powerful factors.
Diffusion Prior Interpolation for Flexibility Real-World Face Super-Resolution
Dec 21, 2024
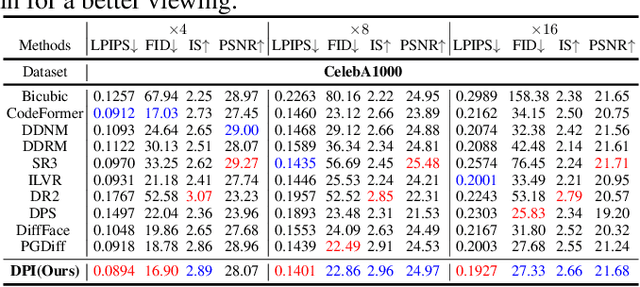
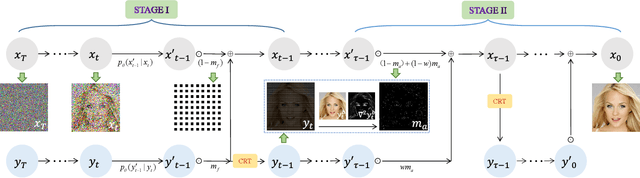
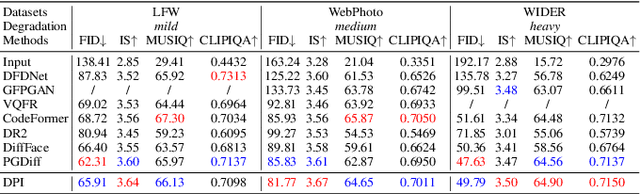
Diffusion models represent the state-of-the-art in generative modeling. Due to their high training costs, many works leverage pre-trained diffusion models' powerful representations for downstream tasks, such as face super-resolution (FSR), through fine-tuning or prior-based methods. However, relying solely on priors without supervised training makes it challenging to meet the pixel-level accuracy requirements of discrimination task. Although prior-based methods can achieve high fidelity and high-quality results, ensuring consistency remains a significant challenge. In this paper, we propose a masking strategy with strong and weak constraints and iterative refinement for real-world FSR, termed Diffusion Prior Interpolation (DPI). We introduce conditions and constraints on consistency by masking different sampling stages based on the structural characteristics of the face. Furthermore, we propose a condition Corrector (CRT) to establish a reciprocal posterior sampling process, enhancing FSR performance by mutual refinement of conditions and samples. DPI can balance consistency and diversity and can be seamlessly integrated into pre-trained models. In extensive experiments conducted on synthetic and real datasets, along with consistency validation in face recognition, DPI demonstrates superiority over SOTA FSR methods. The code is available at \url{https://github.com/JerryYann/DPI}.
Suite-IN: Aggregating Motion Features from Apple Suite for Robust Inertial Navigation
Nov 12, 2024



With the rapid development of wearable technology, devices like smartphones, smartwatches, and headphones equipped with IMUs have become essential for applications such as pedestrian positioning. However, traditional pedestrian dead reckoning (PDR) methods struggle with diverse motion patterns, while recent data-driven approaches, though improving accuracy, often lack robustness due to reliance on a single device.In our work, we attempt to enhance the positioning performance using the low-cost commodity IMUs embedded in the wearable devices. We propose a multi-device deep learning framework named Suite-IN, aggregating motion data from Apple Suite for inertial navigation. Motion data captured by sensors on different body parts contains both local and global motion information, making it essential to reduce the negative effects of localized movements and extract global motion representations from multiple devices.
SMART: Scene-motion-aware human action recognition framework for mental disorder group
Jun 07, 2024



Patients with mental disorders often exhibit risky abnormal actions, such as climbing walls or hitting windows, necessitating intelligent video behavior monitoring for smart healthcare with the rising Internet of Things (IoT) technology. However, the development of vision-based Human Action Recognition (HAR) for these actions is hindered by the lack of specialized algorithms and datasets. In this paper, we innovatively propose to build a vision-based HAR dataset including abnormal actions often occurring in the mental disorder group and then introduce a novel Scene-Motion-aware Action Recognition Technology framework, named SMART, consisting of two technical modules. First, we propose a scene perception module to extract human motion trajectory and human-scene interaction features, which introduces additional scene information for a supplementary semantic representation of the above actions. Second, the multi-stage fusion module fuses the skeleton motion, motion trajectory, and human-scene interaction features, enhancing the semantic association between the skeleton motion and the above supplementary representation, thus generating a comprehensive representation with both human motion and scene information. The effectiveness of our proposed method has been validated on our self-collected HAR dataset (MentalHAD), achieving 94.9% and 93.1% accuracy in un-seen subjects and scenes and outperforming state-of-the-art approaches by 6.5% and 13.2%, respectively. The demonstrated subject- and scene- generalizability makes it possible for SMART's migration to practical deployment in smart healthcare systems for mental disorder patients in medical settings. The code and dataset will be released publicly for further research: https://github.com/Inowlzy/SMART.git.
MMBaT: A Multi-task Framework for mmWave-based Human Body Reconstruction and Translation Prediction
Dec 16, 2023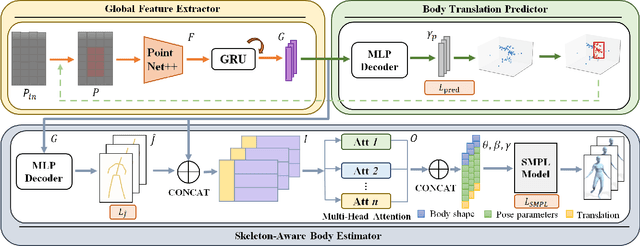
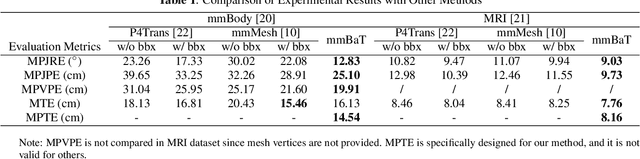
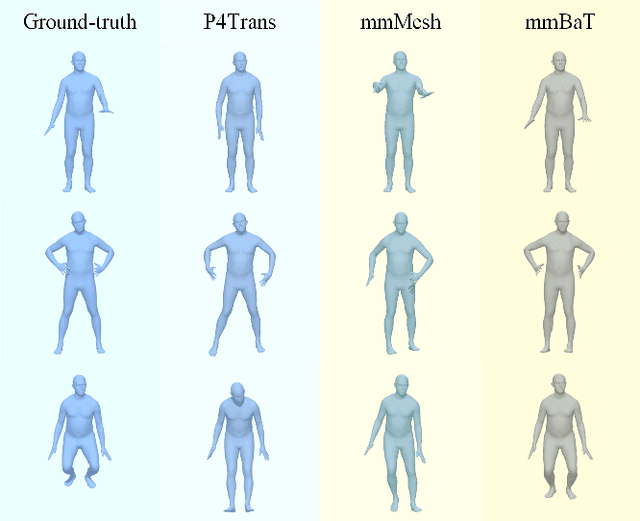
Human body reconstruction with Millimeter Wave (mmWave) radar point clouds has gained significant interest due to its ability to work in adverse environments and its capacity to mitigate privacy concerns associated with traditional camera-based solutions. Despite pioneering efforts in this field, two challenges persist. Firstly, raw point clouds contain massive noise points, usually caused by the ambient objects and multi-path effects of Radio Frequency (RF) signals. Recent approaches typically rely on prior knowledge or elaborate preprocessing methods, limiting their applicability. Secondly, even after noise removal, the sparse and inconsistent body-related points pose an obstacle to accurate human body reconstruction. To address these challenges, we introduce mmBaT, a novel multi-task deep learning framework that concurrently estimates the human body and predicts body translations in subsequent frames to extract body-related point clouds. Our method is evaluated on two public datasets that are collected with different radar devices and noise levels. A comprehensive comparison against other state-of-the-art methods demonstrates our method has a superior reconstruction performance and generalization ability from noisy raw data, even when compared to methods provided with body-related point clouds.
Dynamic Inertial Poser (DynaIP): Part-Based Motion Dynamics Learning for Enhanced Human Pose Estimation with Sparse Inertial Sensors
Dec 02, 2023This paper introduces a novel human pose estimation approach using sparse inertial sensors, addressing the shortcomings of previous methods reliant on synthetic data. It leverages a diverse array of real inertial motion capture data from different skeleton formats to improve motion diversity and model generalization. This method features two innovative components: a pseudo-velocity regression model for dynamic motion capture with inertial sensors, and a part-based model dividing the body and sensor data into three regions, each focusing on their unique characteristics. The approach demonstrates superior performance over state-of-the-art models across five public datasets, notably reducing pose error by 19\% on the DIP-IMU dataset, thus representing a significant improvement in inertial sensor-based human pose estimation. We will make the implementation of our model available for public use.