 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoRe Fine-Tuning with 10x Fewer Parameters
Aug 30, 2024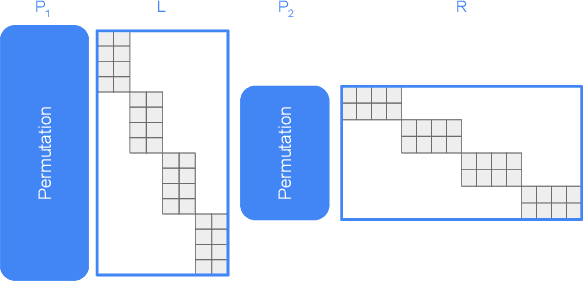
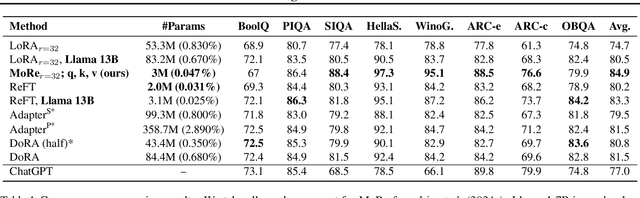
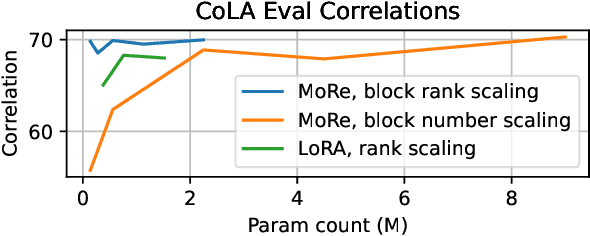
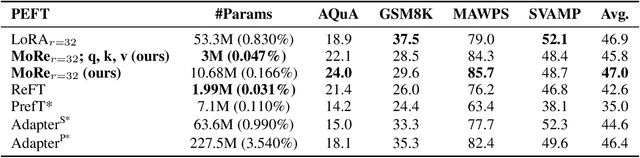
Parameter-efficient fine-tuning (PEFT) techniques have unlocked the potential to cheaply and easily specialize large pretrained models. However, the most prominent approaches, like low-rank adapters (LoRA), depend on heuristics or rules-of-thumb for their architectural choices -- potentially limiting their performance for new models and architectures. This limitation suggests that techniques from neural architecture search could be used to obtain optimal adapter architectures, but these are often expensive and difficult to implement. We address this challenge with Monarch Rectangular Fine-tuning (MoRe), a simple framework to search over adapter architectures that relies on the Monarch matrix class. Theoretically, we show that MoRe is more expressive than LoRA. Empirically, our approach is more parameter-efficient and performant than state-of-the-art PEFTs on a range of tasks and models, with as few as 5\% of LoRA's parameters.
OTTER: Improving Zero-Shot Classification via Optimal Transport
Apr 12, 2024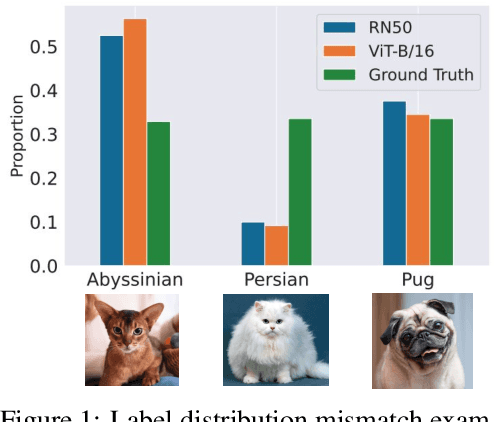
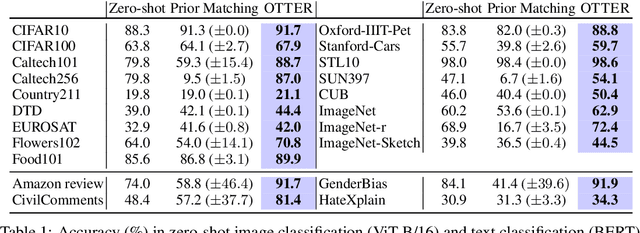
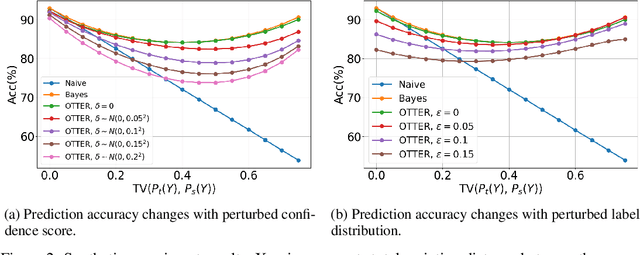
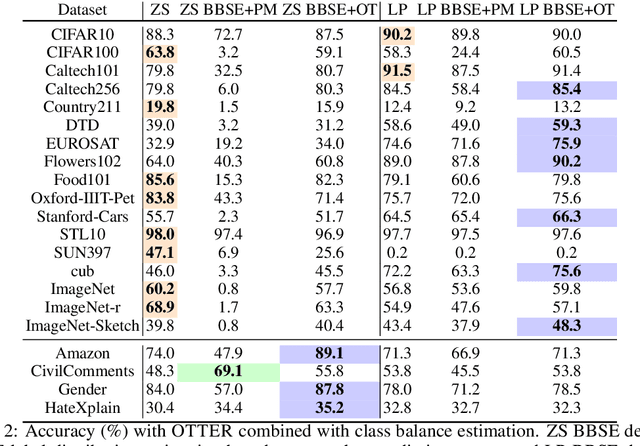
Popular zero-shot models suffer due to artifacts inherited from pretraining. A particularly detrimental artifact, caused by unbalanced web-scale pretraining data, is mismatched label distribution. Existing approaches that seek to repair the label distribution are not suitable in zero-shot settings, as they have incompatible requirements such as access to labeled downstream task data or knowledge of the true label balance in the pretraining distribution. We sidestep these challenges and introduce a simple and lightweight approach to adjust pretrained model predictions via optimal transport. Our technique requires only an estimate of the label distribution of a downstream task. Theoretically, we characterize the improvement produced by our procedure under certain mild conditions and provide bounds on the error caused by misspecification. Empirically, we validate our method in a wide array of zero-shot image and text classification tasks, improving accuracy by 4.8% and 15.9% on average, and beating baselines like Prior Matching -- often by significant margins -- in 17 out of 21 datasets.
Geometry-Aware Adaptation for Pretrained Models
Jul 23, 2023Machine learning models -- including prominent zero-shot models -- are often trained on datasets whose labels are only a small proportion of a larger label space. Such spaces are commonly equipped with a metric that relates the labels via distances between them. We propose a simple approach to exploit this information to adapt the trained model to reliably predict new classes -- or, in the case of zero-shot prediction, to improve its performance -- without any additional training. Our technique is a drop-in replacement of the standard prediction rule, swapping argmax with the Fr\'echet mean. We provide a comprehensive theoretical analysis for this approach, studying (i) learning-theoretic results trading off label space diameter, sample complexity, and model dimension, (ii) characterizations of the full range of scenarios in which it is possible to predict any unobserved class, and (iii) an optimal active learning-like next class selection procedure to obtain optimal training classes for when it is not possible to predict the entire range of unobserved classes. Empirically, using easily-available external metrics, our proposed approach, Loki, gains up to 29.7% relative improvement over SimCLR on ImageNet and scales to hundreds of thousands of classes. When no such metric is available, Loki can use self-derived metrics from class embeddings and obtains a 10.5% improvement on pretrained zero-shot models such as CLIP.