 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressivity-Efficiency Tradeoffs for Hybrid Sequence Models
Mar 09, 2026Hybrid sequence models--combining Transformer and state-space model layers--seek to gain the expressive versatility of attention as well as the computational efficiency of state-space model layers. Despite burgeoning interest in hybrid models, we lack a basic understanding of the settings where--and underlying mechanisms through which--they offer benefits over their constituent models. In this paper, we study this question, focusing on a broad family of core synthetic tasks. For this family of tasks, we prove the existence of fundamental limitations for non-hybrid models. Specifically, any Transformer or state-space model that solves the underlying task requires either a large number of parameters or a large working memory. On the other hand, for two prototypical tasks within this family--namely selective copying and associative recall--we construct hybrid models of small size and working memory that provably solve these tasks, thus achieving the best of both worlds. Our experimental evaluation empirically validates our theoretical findings. Importantly, going beyond the settings in our theoretical analysis, we empirically show that learned--rather than constructed--hybrids outperform non-hybrid models with up to 6x as many parameters. We additionally demonstrate that hybrid models exhibit stronger length generalization and out-of-distribution robustness than non-hybrids.
Weight Updates as Activation Shifts: A Principled Framework for Steering
Feb 28, 2026Activation steering promises to be an extremely parameter-efficient form of adaptation, but its effectiveness depends on critical design choices -- such as intervention location and parameterization -- that currently rely on empirical heuristics rather than a principled foundation. We establish a first-order equivalence between activation-space interventions and weight-space updates, deriving the conditions under which activation steering can replicate fine-tuning behavior. This equivalence yields a principled framework for steering design and identifies the post-block output as a theoretically-backed and highly expressive intervention site. We further explain why certain intervention locations outperform others and show that weight updates and activation updates play distinct, complementary functional roles. This analysis motivates a new approach -- joint adaptation -- that trains in both spaces simultaneously. Our post-block steering achieves accuracy within 0.2%-0.9%$ of full-parameter tuning, on average across tasks and models, while training only 0.04% of model parameters. It consistently outperforms prior activation steering methods such as ReFT and PEFT approaches including LoRA, while using significantly fewer parameters. Finally, we show that joint adaptation often surpasses the performance ceilings of weight and activation updates in isolation, introducing a new paradigm for efficient model adaptation.
Seeing Beyond Redundancy: Task Complexity's Role in Vision Token Specialization in VLLMs
Feb 06, 2026Vision capabilities in vision large language models (VLLMs) have consistently lagged behind their linguistic capabilities. In particular, numerous benchmark studies have demonstrated that VLLMs struggle when fine-grained visual information or spatial reasoning is required. However, we do not yet understand exactly why VLLMs struggle so much with these tasks relative to others. Some works have focused on visual redundancy as an explanation, where high-level visual information is uniformly spread across numerous tokens and specific, fine-grained visual information is discarded. In this work, we investigate this premise in greater detail, seeking to better understand exactly how various types of visual information are processed by the model and what types of visual information are discarded. To do so, we introduce a simple synthetic benchmark dataset that is specifically constructed to probe various visual features, along with a set of metrics for measuring visual redundancy, allowing us to better understand the nuances of their relationship. Then, we explore fine-tuning VLLMs on a number of complex visual tasks to better understand how redundancy and compression change based upon the complexity of the data that a model is trained on. We find that there is a connection between task complexity and visual compression, implying that having a sufficient ratio of high complexity visual data is crucial for altering the way that VLLMs distribute their visual representation and consequently improving their performance on complex visual tasks. We hope that this work will provide valuable insights for training the next generation of VLLMs.
R&B: Domain Regrouping and Data Mixture Balancing for Efficient Foundation Model Training
May 01, 2025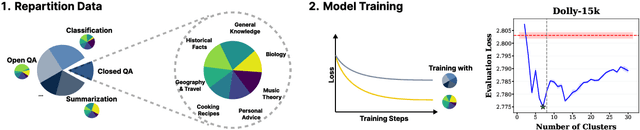
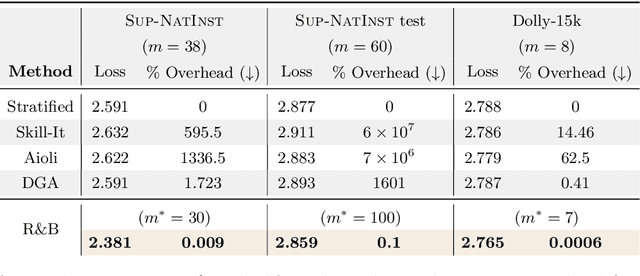
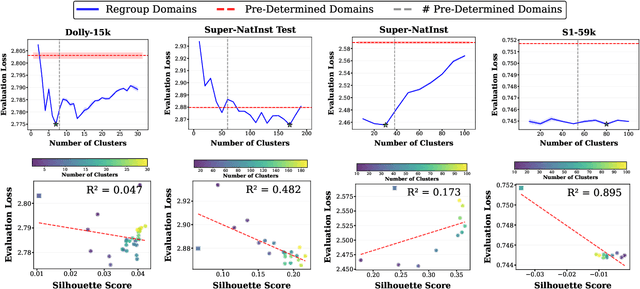
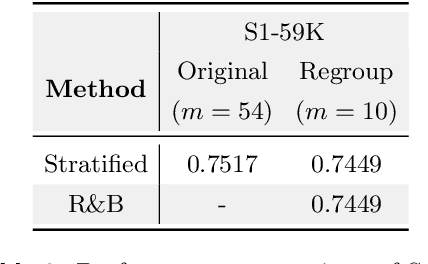
Data mixing strategies have successfully reduced the costs involved in training language models. While promising, such methods suffer from two flaws. First, they rely on predetermined data domains (e.g., data sources, task types), which may fail to capture critical semantic nuances, leaving performance on the table. Second, these methods scale with the number of domains in a computationally prohibitive way. We address these challenges via R&B, a framework that re-partitions training data based on semantic similarity (Regroup) to create finer-grained domains, and efficiently optimizes the data composition (Balance) by leveraging a Gram matrix induced by domain gradients obtained throughout training. Unlike prior works, it removes the need for additional compute to obtain evaluation information such as losses or gradients. We analyze this technique under standard regularity conditions and provide theoretical insights that justify R&B's effectiveness compared to non-adaptive mixing approaches. Empirically, we demonstrate the effectiveness of R&B on five diverse datasets ranging from natural language to reasoning and multimodal tasks. With as little as 0.01% additional compute overhead, R&B matches or exceeds the performance of state-of-the-art data mixing strategies.
Foundation Models for Remote Sensing: An Analysis of MLLMs for Object Localization
Apr 14, 2025


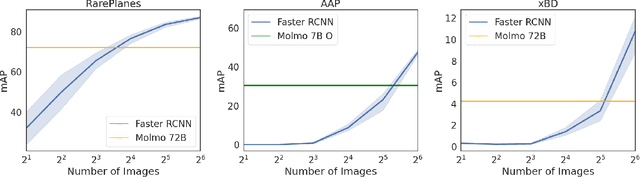
Multimodal large language models (MLLMs) have altered the landscape of computer vision, obtaining impressive results across a wide range of tasks, especially in zero-shot settings. Unfortunately, their strong performance does not always transfer to out-of-distribution domains, such as earth observation (EO) imagery. Prior work has demonstrated that MLLMs excel at some EO tasks, such as image captioning and scene understanding, while failing at tasks that require more fine-grained spatial reasoning, such as object localization. However, MLLMs are advancing rapidly and insights quickly become out-dated. In this work, we analyze more recent MLLMs that have been explicitly trained to include fine-grained spatial reasoning capabilities, benchmarking them on EO object localization tasks. We demonstrate that these models are performant in certain settings, making them well suited for zero-shot scenarios. Additionally, we provide a detailed discussion focused on prompt selection, ground sample distance (GSD) optimization, and analyzing failure cases. We hope that this work will prove valuable as others evaluate whether an MLLM is well suited for a given EO localization task and how to optimize it.
Weak-to-Strong Generalization Through the Data-Centric Lens
Dec 05, 2024



The weak-to-strong generalization phenomenon is the driver for important machine learning applications including highly data-efficient learning and, most recently, performing superalignment. While decades of research have resulted in numerous algorithms that produce strong empirical performance, understanding what aspects of data enable weak-to-strong generalization has been understudied. We propose a simple data-centric mechanism that characterizes weak-to-strong generalization: the overlap density. Intuitively, generalization tracks the number of points that contain overlaps, i.e., both easy patterns (learnable by a weak model) and challenging patterns (only learnable by a stronger model), as with such points, weak predictions can be used to learn challenging patterns by stronger models. We provide a practical overlap detection algorithm to find such points in datasets and leverage them to learn, among multiple sources of data, which to query when seeking to maximize overlap density and thereby enhance weak-to-strong generalization. We present a theoretical result showing that the generalization benefit is a function of the overlap density and a regret bound for our data selection algorithm. Empirically, we validate the mechanism and the overlap detection algorithm on a wide array of settings.
Everything Everywhere All at Once: LLMs can In-Context Learn Multiple Tasks in Superposition
Oct 08, 2024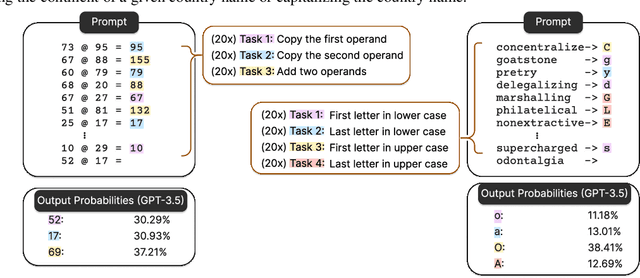

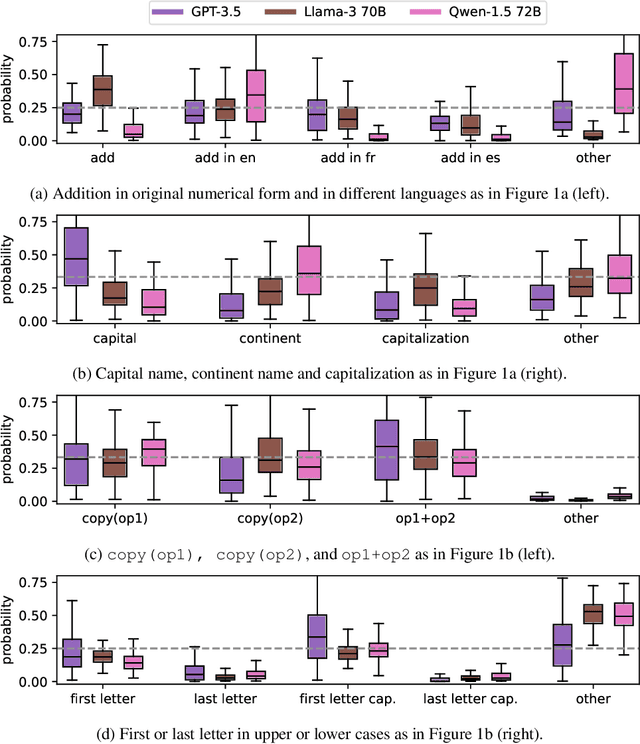
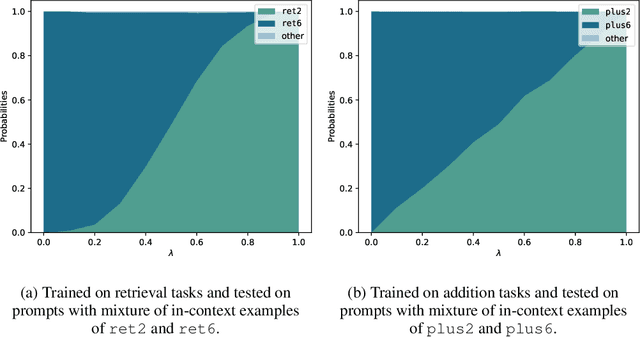
Large Language Models (LLMs) have demonstrated remarkable in-context learning (ICL) capabilities. In this study, we explore a surprising phenomenon related to ICL: LLMs can perform multiple, computationally distinct ICL tasks simultaneously, during a single inference call, a capability we term "task superposition". We provide empirical evidence of this phenomenon across various LLM families and scales and show that this phenomenon emerges even if we train the model to in-context learn one task at a time. We offer theoretical explanations that this capability is well within the expressive power of transformers. We also explore how LLMs internally compose task vectors during superposition. Furthermore, we show that larger models can solve more ICL tasks in parallel, and better calibrate their output distribution. Our findings offer insights into the latent capabilities of LLMs, further substantiate the perspective of "LLMs as superposition of simulators", and raise questions about the mechanisms enabling simultaneous task execution.
MoRe Fine-Tuning with 10x Fewer Parameters
Aug 30, 2024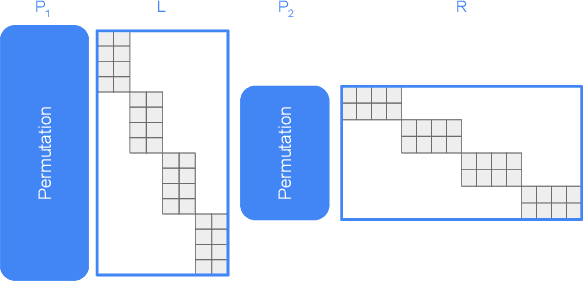
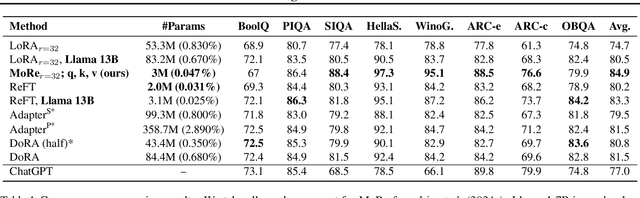
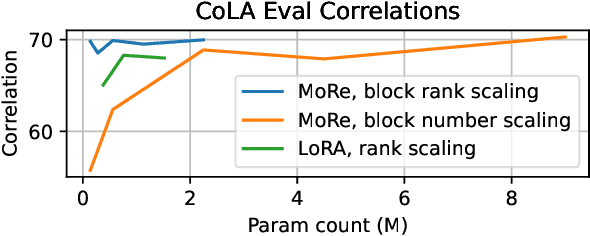
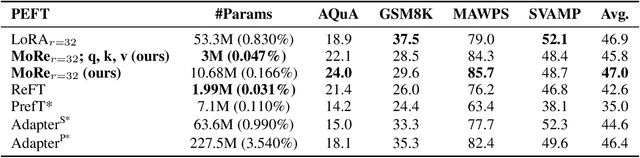
Parameter-efficient fine-tuning (PEFT) techniques have unlocked the potential to cheaply and easily specialize large pretrained models. However, the most prominent approaches, like low-rank adapters (LoRA), depend on heuristics or rules-of-thumb for their architectural choices -- potentially limiting their performance for new models and architectures. This limitation suggests that techniques from neural architecture search could be used to obtain optimal adapter architectures, but these are often expensive and difficult to implement. We address this challenge with Monarch Rectangular Fine-tuning (MoRe), a simple framework to search over adapter architectures that relies on the Monarch matrix class. Theoretically, we show that MoRe is more expressive than LoRA. Empirically, our approach is more parameter-efficient and performant than state-of-the-art PEFTs on a range of tasks and models, with as few as 5\% of LoRA's parameters.
Inverse Kinematics and Sensitivity Minimization of an n-Stack Stewart Platform
Nov 13, 2018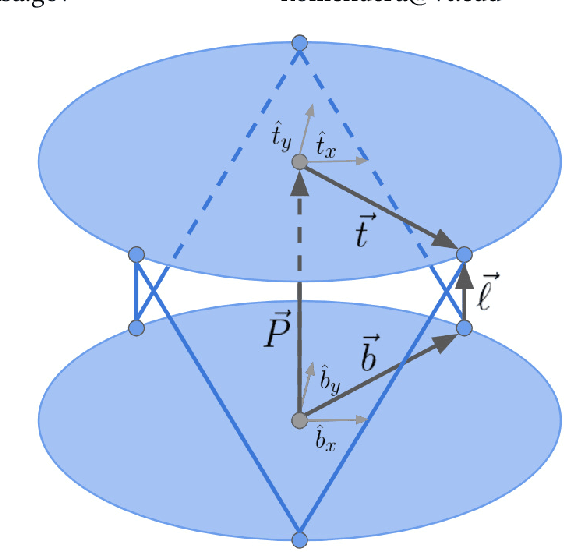
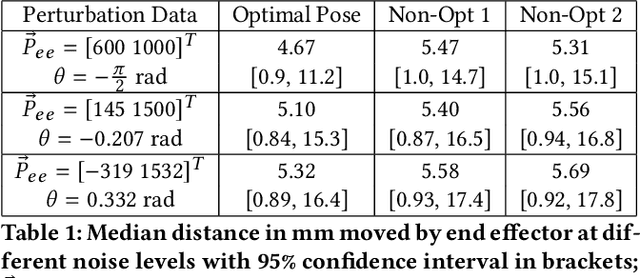
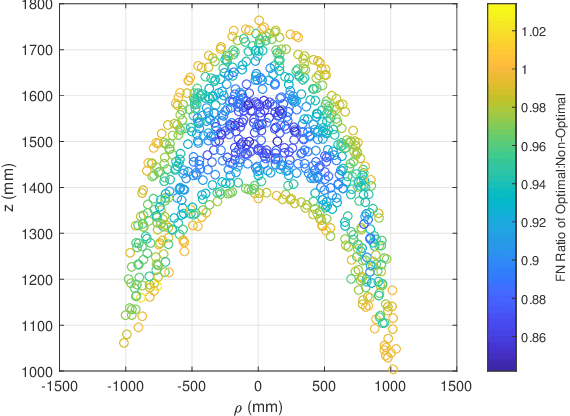
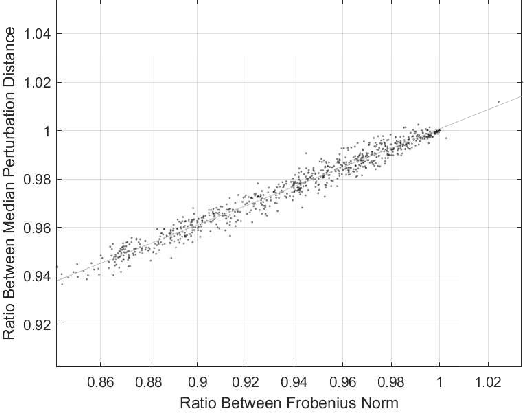
An autonomous system is presented to solve the problem of in space assembly, which can be used to further the NASA goal of deep space exploration. Of particular interest is the assembly of large truss structures, which requires precise and dexterous movement in a changing environment. A prototype of an autonomous manipulator called "Assemblers" was fabricated from an aggregation of Stewart Platform robots for the purpose of researching autonomous in space assembly capabilities. The forward kinematics for an Assembler is described by the set of translations and rotation angles for each component Stewart Platform, from which the position and orientation of the end effector are simple to calculate. However, selecting inverse kinematic poses, defined by the translations and rotation angles, for the Assembler requires coordination between each Stewart Platform and is an underconstrained non-linear optimization problem. For assembly tasks, it is ideal that the pose selected has the least sensitivity to disturbances possible. A method of sensitivity reduction is proposed by minimizing the Frobenius Norm (FN) of the Jacobian for the forward kinematics. The effectiveness of the FN method will be demonstrated through a Monte Carlo simulation method to model random motion internal to the structure.