 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabby: Tabular Data Synthesis with Language Models
Mar 04, 2025



While advances in large language models (LLMs) have greatly improved the quality of synthetic text data in recent years, synthesizing tabular data has received relatively less attention. We address this disparity with Tabby, a simple but powerful post-training modification to the standard Transformer language model architecture, enabling its use for tabular dataset synthesis. Tabby enables the representation of differences across columns using Gated Mixture-of-Experts, with column-specific sets of parameters. Empirically, Tabby results in data quality near or equal to that of real data. By pairing our novel LLM table training technique, Plain, with Tabby, we observe up to a 44% improvement in quality over previous methods. We also show that Tabby extends beyond tables to more general structured data, reaching parity with real data on a nested JSON dataset as well.
MoRe Fine-Tuning with 10x Fewer Parameters
Aug 30, 2024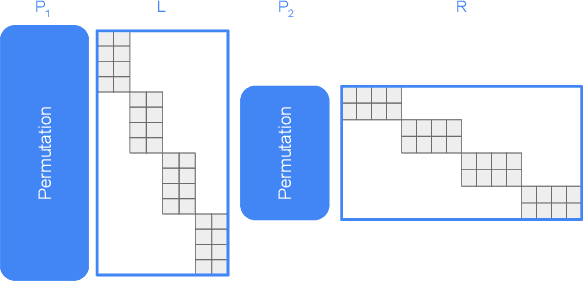
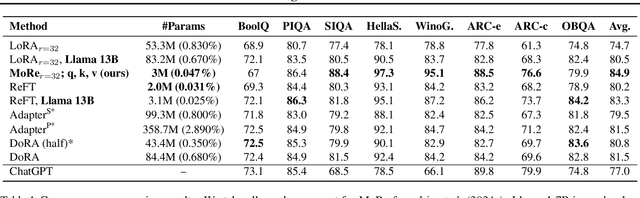
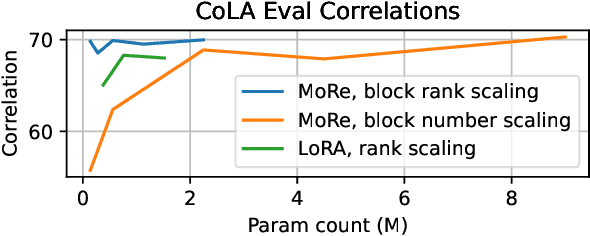
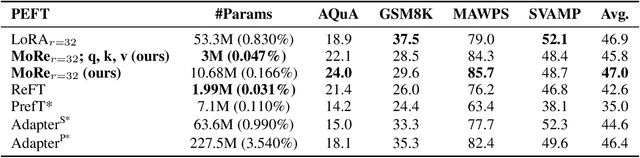
Parameter-efficient fine-tuning (PEFT) techniques have unlocked the potential to cheaply and easily specialize large pretrained models. However, the most prominent approaches, like low-rank adapters (LoRA), depend on heuristics or rules-of-thumb for their architectural choices -- potentially limiting their performance for new models and architectures. This limitation suggests that techniques from neural architecture search could be used to obtain optimal adapter architectures, but these are often expensive and difficult to implement. We address this challenge with Monarch Rectangular Fine-tuning (MoRe), a simple framework to search over adapter architectures that relies on the Monarch matrix class. Theoretically, we show that MoRe is more expressive than LoRA. Empirically, our approach is more parameter-efficient and performant than state-of-the-art PEFTs on a range of tasks and models, with as few as 5\% of LoRA's parameters.
Pretrained Hybrids with MAD Skills
Jun 02, 2024



While Transformers underpin modern large language models (LMs), there is a growing list of alternative architectures with new capabilities, promises, and tradeoffs. This makes choosing the right LM architecture challenging. Recently-proposed $\textit{hybrid architectures}$ seek a best-of-all-worlds approach that reaps the benefits of all architectures. Hybrid design is difficult for two reasons: it requires manual expert-driven search, and new hybrids must be trained from scratch. We propose $\textbf{Manticore}$, a framework that addresses these challenges. Manticore $\textit{automates the design of hybrid architectures}$ while reusing pretrained models to create $\textit{pretrained}$ hybrids. Our approach augments ideas from differentiable Neural Architecture Search (NAS) by incorporating simple projectors that translate features between pretrained blocks from different architectures. We then fine-tune hybrids that combine pretrained models from different architecture families -- such as the GPT series and Mamba -- end-to-end. With Manticore, we enable LM selection without training multiple models, the construction of pretrained hybrids from existing pretrained models, and the ability to $\textit{program}$ pretrained hybrids to have certain capabilities. Manticore hybrids outperform existing manually-designed hybrids, achieve strong performance on Long Range Arena (LRA) tasks, and can improve on pretrained transformers and state space models.