 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated regularized learning in finite N-person games
Dec 29, 2024Motivated by the success of Nesterov's accelerated gradient algorithm for convex minimization problems, we examine whether it is possible to achieve similar performance gains in the context of online learning in games. To that end, we introduce a family of accelerated learning methods, which we call "follow the accelerated leader" (FTXL), and which incorporates the use of momentum within the general framework of regularized learning - and, in particular, the exponential/multiplicative weights algorithm and its variants. Drawing inspiration and techniques from the continuous-time analysis of Nesterov's algorithm, we show that FTXL converges locally to strict Nash equilibria at a superlinear rate, achieving in this way an exponential speed-up over vanilla regularized learning methods (which, by comparison, converge to strict equilibria at a geometric, linear rate). Importantly, FTXL maintains its superlinear convergence rate in a broad range of feedback structures, from deterministic, full information models to stochastic, realization-based ones, and even when run with bandit, payoff-based information, where players are only able to observe their individual realized payoffs.
Everything Everywhere All at Once: LLMs can In-Context Learn Multiple Tasks in Superposition
Oct 08, 2024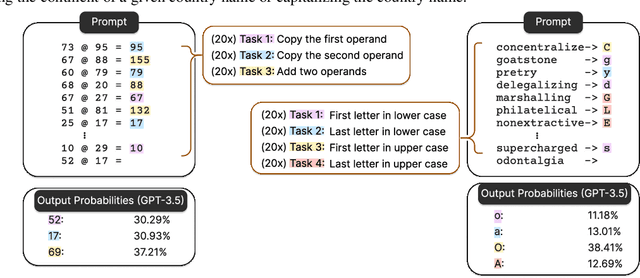

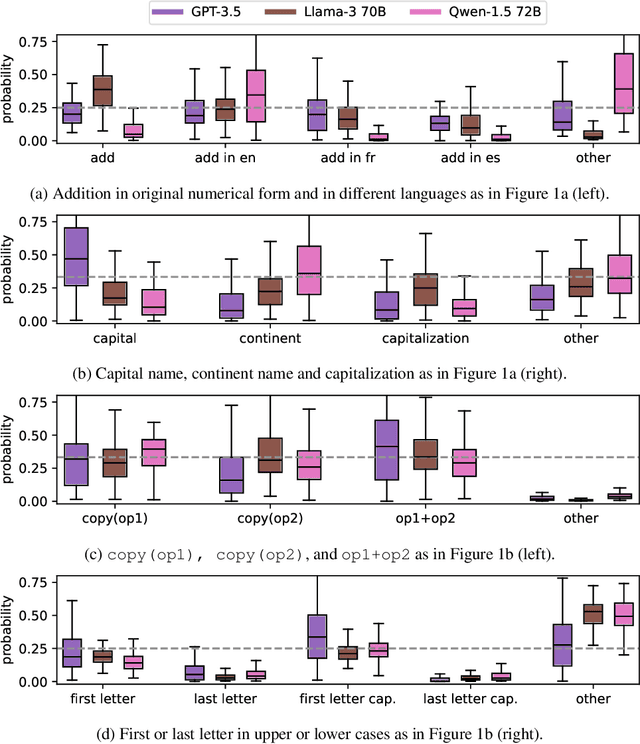
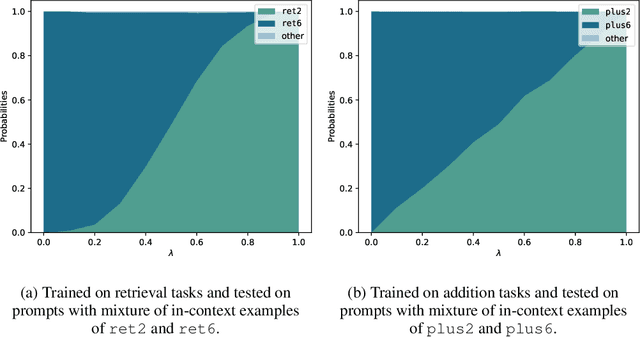
Large Language Models (LLMs) have demonstrated remarkable in-context learning (ICL) capabilities. In this study, we explore a surprising phenomenon related to ICL: LLMs can perform multiple, computationally distinct ICL tasks simultaneously, during a single inference call, a capability we term "task superposition". We provide empirical evidence of this phenomenon across various LLM families and scales and show that this phenomenon emerges even if we train the model to in-context learn one task at a time. We offer theoretical explanations that this capability is well within the expressive power of transformers. We also explore how LLMs internally compose task vectors during superposition. Furthermore, we show that larger models can solve more ICL tasks in parallel, and better calibrate their output distribution. Our findings offer insights into the latent capabilities of LLMs, further substantiate the perspective of "LLMs as superposition of simulators", and raise questions about the mechanisms enabling simultaneous task execution.
How Well Can Transformers Emulate In-context Newton's Method?
Mar 05, 2024Transformer-based models have demonstrated remarkable in-context learning capabilities, prompting extensive research into its underlying mechanisms. Recent studies have suggested that Transformers can implement first-order optimization algorithms for in-context learning and even second order ones for the case of linear regression. In this work, we study whether Transformers can perform higher order optimization methods, beyond the case of linear regression. We establish that linear attention Transformers with ReLU layers can approximate second order optimization algorithms for the task of logistic regression and achieve $\epsilon$ error with only a logarithmic to the error more layers. As a by-product we demonstrate the ability of even linear attention-only Transformers in implementing a single step of Newton's iteration for matrix inversion with merely two layers. These results suggest the ability of the Transformer architecture to implement complex algorithms, beyond gradient descent.
Stochastic Methods in Variational Inequalities: Ergodicity, Bias and Refinements
Jun 28, 2023



For min-max optimization and variational inequalities problems (VIP) encountered in diverse machine learning tasks, Stochastic Extragradient (SEG) and Stochastic Gradient Descent Ascent (SGDA) have emerged as preeminent algorithms. Constant step-size variants of SEG/SGDA have gained popularity, with appealing benefits such as easy tuning and rapid forgiveness of initial conditions, but their convergence behaviors are more complicated even in rudimentary bilinear models. Our work endeavors to elucidate and quantify the probabilistic structures intrinsic to these algorithms. By recasting the constant step-size SEG/SGDA as time-homogeneous Markov Chains, we establish a first-of-its-kind Law of Large Numbers and a Central Limit Theorem, demonstrating that the average iterate is asymptotically normal with a unique invariant distribution for an extensive range of monotone and non-monotone VIPs. Specializing to convex-concave min-max optimization, we characterize the relationship between the step-size and the induced bias with respect to the Von-Neumann's value. Finally, we establish that Richardson-Romberg extrapolation can improve proximity of the average iterate to the global solution for VIPs. Our probabilistic analysis, underpinned by experiments corroborating our theoretical discoveries, harnesses techniques from optimization, Markov chains, and operator theory.
Dissecting Chain-of-Thought: A Study on Compositional In-Context Learning of MLPs
May 30, 2023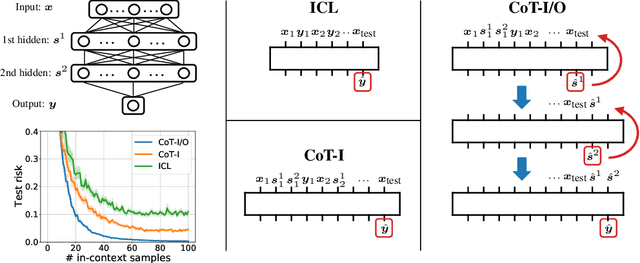
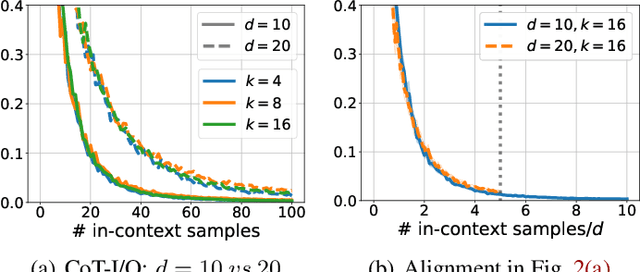
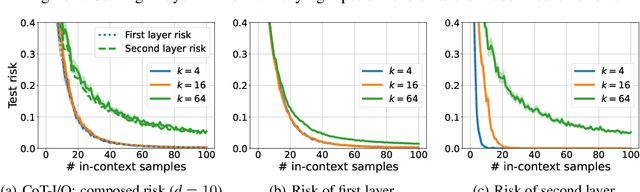
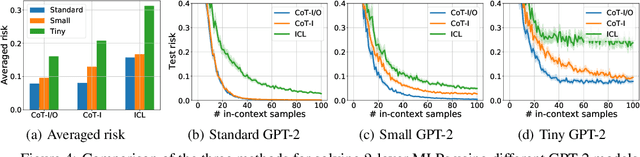
Chain-of-thought (CoT) is a method that enables language models to handle complex reasoning tasks by decomposing them into simpler steps. Despite its success, the underlying mechanics of CoT are not yet fully understood. In an attempt to shed light on this, our study investigates the impact of CoT on the ability of transformers to in-context learn a simple to study, yet general family of compositional functions: multi-layer perceptrons (MLPs). In this setting, we reveal that the success of CoT can be attributed to breaking down in-context learning of a compositional function into two distinct phases: focusing on data related to each step of the composition and in-context learning the single-step composition function. Through both experimental and theoretical evidence, we demonstrate how CoT significantly reduces the sample complexity of in-context learning (ICL) and facilitates the learning of complex functions that non-CoT methods struggle with. Furthermore, we illustrate how transformers can transition from vanilla in-context learning to mastering a compositional function with CoT by simply incorporating an additional layer that performs the necessary filtering for CoT via the attention mechanism. In addition to these test-time benefits, we highlight how CoT accelerates pretraining by learning shortcuts to represent complex functions and how filtering plays an important role in pretraining. These findings collectively provide insights into the mechanics of CoT, inviting further investigation of its role in complex reasoning tasks.
The Expressive Power of Tuning Only the Norm Layers
Feb 15, 2023Feature normalization transforms such as Batch and Layer-Normalization have become indispensable ingredients of state-of-the-art deep neural networks. Recent studies on fine-tuning large pretrained models indicate that just tuning the parameters of these affine transforms can achieve high accuracy for downstream tasks. These findings open the questions about the expressive power of tuning the normalization layers of frozen networks. In this work, we take the first step towards this question and show that for random ReLU networks, fine-tuning only its normalization layers can reconstruct any target network that is $O(\sqrt{\text{width}})$ times smaller. We show that this holds even for randomly sparsified networks, under sufficient overparameterization, in agreement with prior empirical work.
Looped Transformers as Programmable Computers
Jan 30, 2023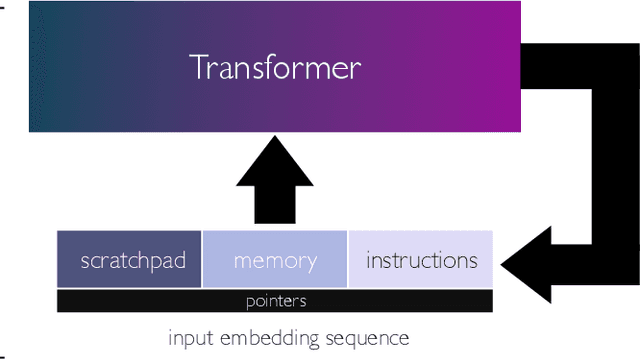
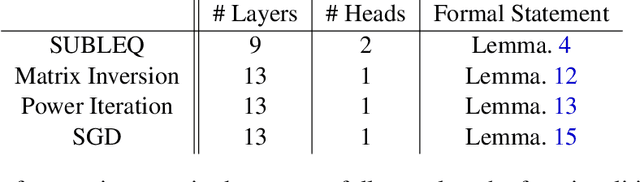
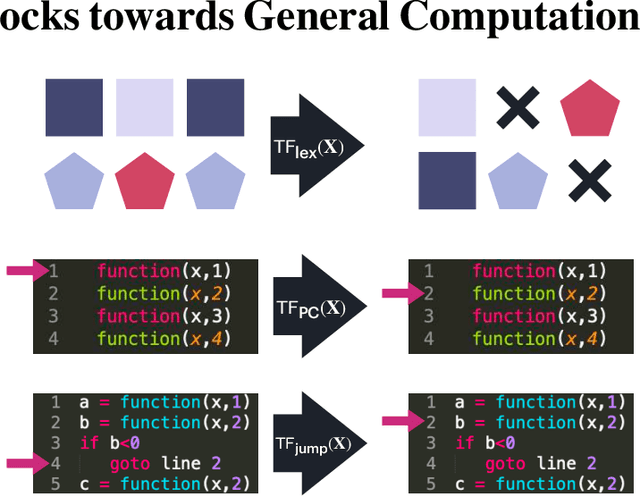
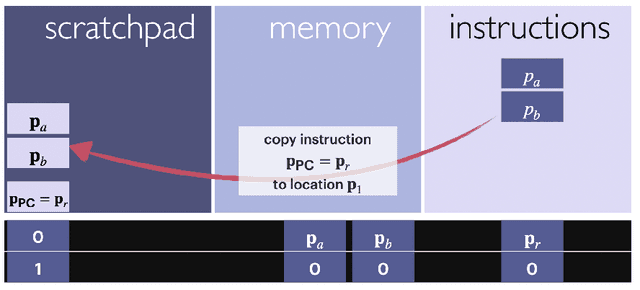
We present a framework for using transformer networks as universal computers by programming them with specific weights and placing them in a loop. Our input sequence acts as a punchcard, consisting of instructions and memory for data read/writes. We demonstrate that a constant number of encoder layers can emulate basic computing blocks, including embedding edit operations, non-linear functions, function calls, program counters, and conditional branches. Using these building blocks, we emulate a small instruction-set computer. This allows us to map iterative algorithms to programs that can be executed by a looped, 13-layer transformer. We show how this transformer, instructed by its input, can emulate a basic calculator, a basic linear algebra library, and in-context learning algorithms that employ backpropagation. Our work highlights the versatility of the attention mechanism, and demonstrates that even shallow transformers can execute full-fledged, general-purpose programs.
On the convergence of policy gradient methods to Nash equilibria in general stochastic games
Oct 17, 2022Learning in stochastic games is a notoriously difficult problem because, in addition to each other's strategic decisions, the players must also contend with the fact that the game itself evolves over time, possibly in a very complicated manner. Because of this, the convergence properties of popular learning algorithms - like policy gradient and its variants - are poorly understood, except in specific classes of games (such as potential or two-player, zero-sum games). In view of this, we examine the long-run behavior of policy gradient methods with respect to Nash equilibrium policies that are second-order stationary (SOS) in a sense similar to the type of sufficiency conditions used in optimization. Our first result is that SOS policies are locally attracting with high probability, and we show that policy gradient trajectories with gradient estimates provided by the REINFORCE algorithm achieve an $\mathcal{O}(1/\sqrt{n})$ distance-squared convergence rate if the method's step-size is chosen appropriately. Subsequently, specializing to the class of deterministic Nash policies, we show that this rate can be improved dramatically and, in fact, policy gradient methods converge within a finite number of iterations in that case.
Survival of the strictest: Stable and unstable equilibria under regularized learning with partial information
Feb 04, 2021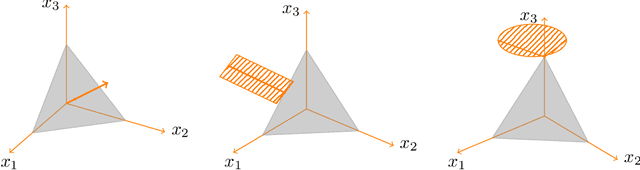
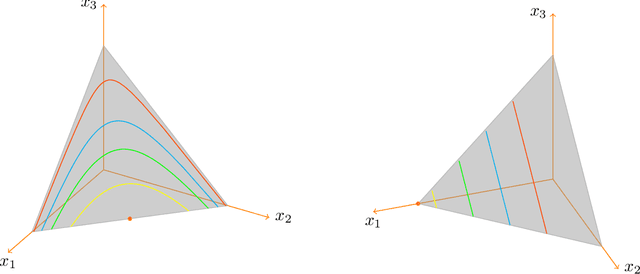
In this paper, we examine the Nash equilibrium convergence properties of no-regret learning in general N-player games. For concreteness, we focus on the archetypal follow the regularized leader (FTRL) family of algorithms, and we consider the full spectrum of uncertainty that the players may encounter - from noisy, oracle-based feedback, to bandit, payoff-based information. In this general context, we establish a comprehensive equivalence between the stability of a Nash equilibrium and its support: a Nash equilibrium is stable and attracting with arbitrarily high probability if and only if it is strict (i.e., each equilibrium strategy has a unique best response). This equivalence extends existing continuous-time versions of the folk theorem of evolutionary game theory to a bona fide algorithmic learning setting, and it provides a clear refinement criterion for the prediction of the day-to-day behavior of no-regret learning in games