 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR-Sieve Bootstrap for the Random Forest and a simulation-based comparison with rangerts time series prediction
Oct 01, 2024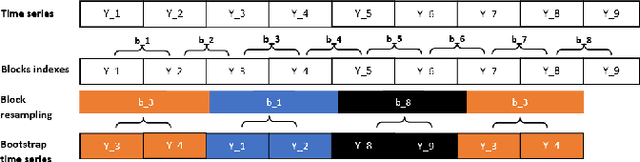
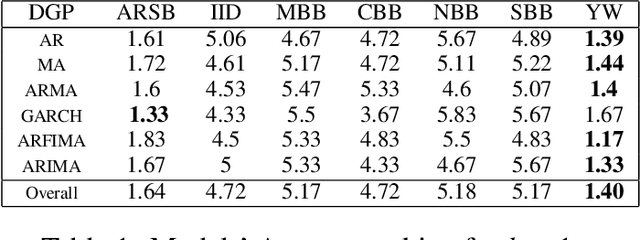
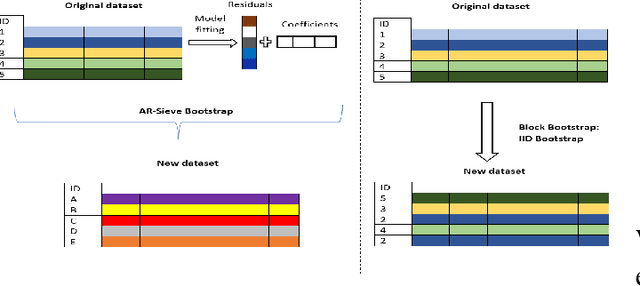
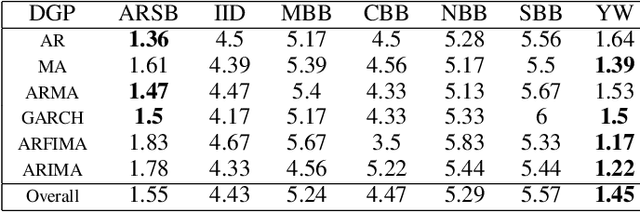
The Random Forest (RF) algorithm can be applied to a broad spectrum of problems, including time series prediction. However, neither the classical IID (Independent and Identically distributed) bootstrap nor block bootstrapping strategies (as implemented in rangerts) completely account for the nature of the Data Generating Process (DGP) while resampling the observations. We propose the combination of RF with a residual bootstrapping technique where we replace the IID bootstrap with the AR-Sieve Bootstrap (ARSB), which assumes the DGP to be an autoregressive process. To assess the new model's predictive performance, we conduct a simulation study using synthetic data generated from different types of DGPs. It turns out that ARSB provides more variation amongst the trees in the forest. Moreover, RF with ARSB shows greater accuracy compared to RF with other bootstrap strategies. However, these improvements are achieved at some efficiency costs.
Block-local learning with probabilistic latent representations
May 24, 2023



The ubiquitous backpropagation algorithm requires sequential updates across blocks of a network, introducing a locking problem. Moreover, backpropagation relies on the transpose of weight matrices to calculate updates, introducing a weight transport problem across blocks. Both these issues prevent efficient parallelisation and horizontal scaling of models across devices. We propose a new method that introduces a twin network that propagates information backwards from the targets to the input to provide auxiliary local losses. Forward and backward propagation can work in parallel and with different sets of weights, addressing the problems of weight transport and locking. Our approach derives from a statistical interpretation of end-to-end training which treats activations of network layers as parameters of probability distributions. The resulting learning framework uses these parameters locally to assess the matching between forward and backward information. Error backpropagation is then performed locally within each block, leading to `block-local' learning. Several previously proposed alternatives to error backpropagation emerge as special cases of our model. We present results on various tasks and architectures, including transformers, demonstrating state-of-the-art performance using block-local learning. These results provide a new principled framework to train very large networks in a distributed setting and can also be applied in neuromorphic systems.