 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Quality Estimation: Creating Surrogate Models for Human Quality Ratings
May 17, 2022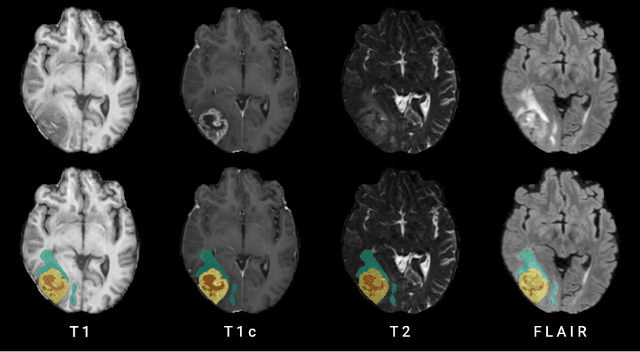
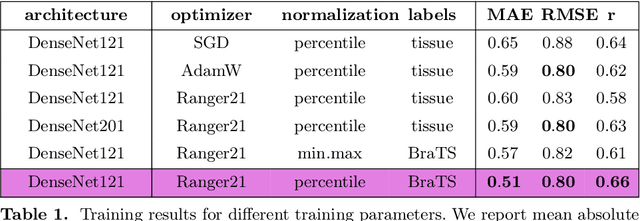
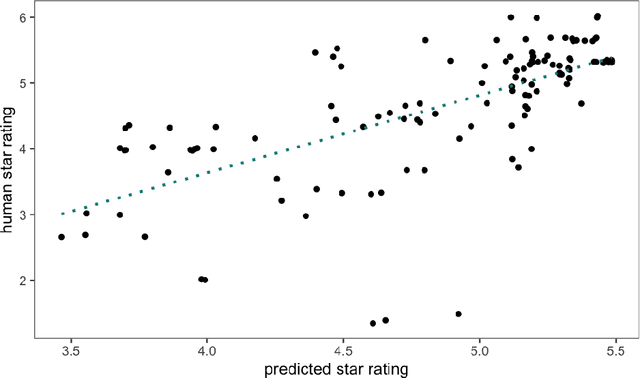
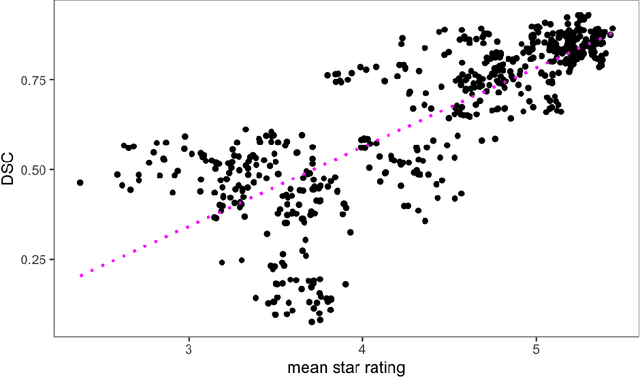
Human ratings are abstract representations of segmentation quality. To approximate human quality ratings on scarce expert data, we train surrogate quality estimation models. We evaluate on a complex multi-class segmentation problem, specifically glioma segmentation following the BraTS annotation protocol. The training data features quality ratings from 15 expert neuroradiologists on a scale ranging from 1 to 6 stars for various computer-generated and manual 3D annotations. Even though the networks operate on 2D images and with scarce training data, we can approximate segmentation quality within a margin of error comparable to human intra-rater reliability. Segmentation quality prediction has broad applications. While an understanding of segmentation quality is imperative for successful clinical translation of automatic segmentation quality algorithms, it can play an essential role in training new segmentation models. Due to the split-second inference times, it can be directly applied within a loss function or as a fully-automatic dataset curation mechanism in a federated learning setting.
Train, Learn, Expand, Repeat
Apr 19, 2020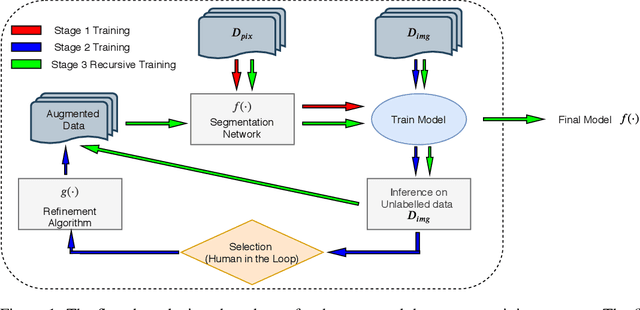
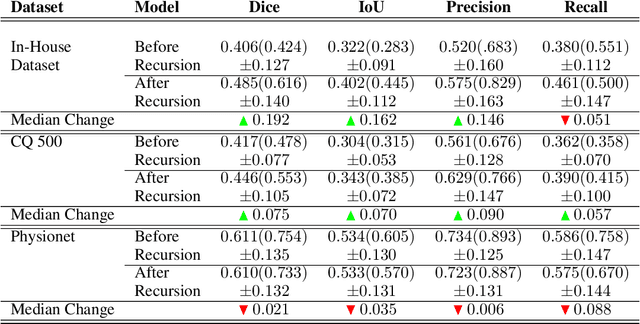
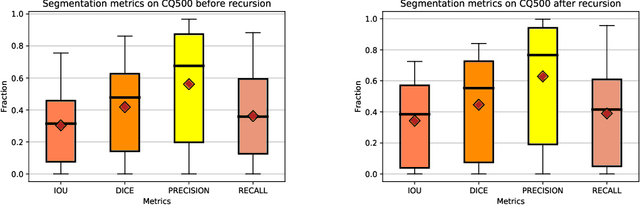
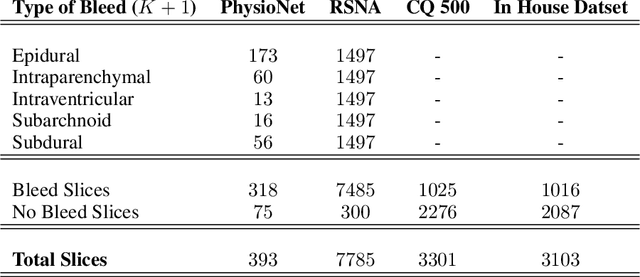
High-quality labeled data is essential to successfully train supervised machine learning models. Although a large amount of unlabeled data is present in the medical domain, labeling poses a major challenge: medical professionals who can expertly label the data are a scarce and expensive resource. Making matters worse, voxel-wise delineation of data (e.g. for segmentation tasks) is tedious and suffers from high inter-rater variance, thus dramatically limiting available training data. We propose a recursive training strategy to perform the task of semantic segmentation given only very few training samples with pixel-level annotations. We expand on this small training set having cheaper image-level annotations using a recursive training strategy. We apply this technique on the segmentation of intracranial hemorrhage (ICH) in CT (computed tomography) scans of the brain, where typically few annotated data is available.