 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Attention Search Linear: Towards Adaptive Token-Level Hybrid Attention Models
Feb 03, 2026The quadratic computational complexity of softmax transformers has become a bottleneck in long-context scenarios. In contrast, linear attention model families provide a promising direction towards a more efficient sequential model. These linear attention models compress past KV values into a single hidden state, thereby efficiently reducing complexity during both training and inference. However, their expressivity remains limited by the size of their hidden state. Previous work proposed interleaving softmax and linear attention layers to reduce computational complexity while preserving expressivity. Nevertheless, the efficiency of these models remains bottlenecked by their softmax attention layers. In this paper, we propose Neural Attention Search Linear (NAtS-L), a framework that applies both linear attention and softmax attention operations within the same layer on different tokens. NAtS-L automatically determines whether a token can be handled by a linear attention model, i.e., tokens that have only short-term impact and can be encoded into fixed-size hidden states, or require softmax attention, i.e., tokens that contain information related to long-term retrieval and need to be preserved for future queries. By searching for optimal Gated DeltaNet and softmax attention combinations across tokens, we show that NAtS-L provides a strong yet efficient token-level hybrid architecture.
carps: A Framework for Comparing N Hyperparameter Optimizers on M Benchmarks
Jun 06, 2025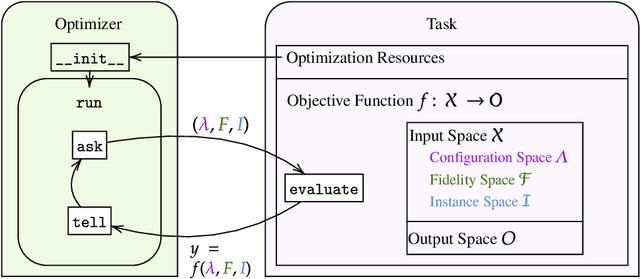

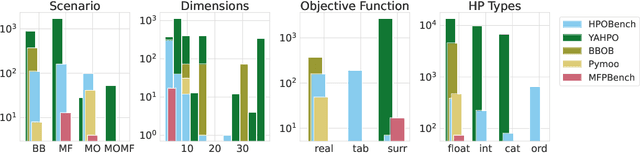
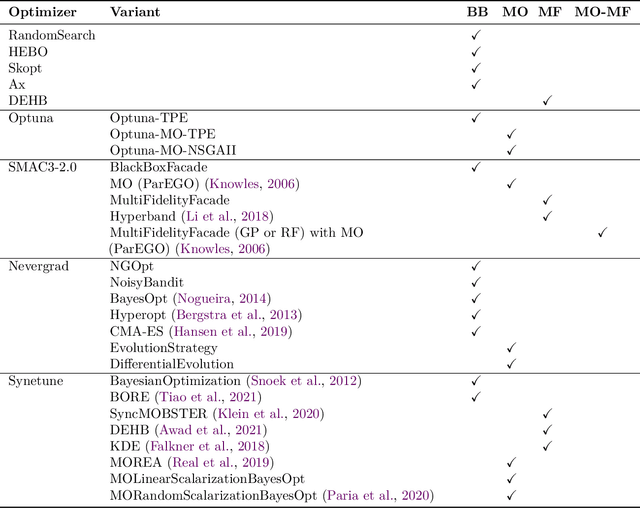
Hyperparameter Optimization (HPO) is crucial to develop well-performing machine learning models. In order to ease prototyping and benchmarking of HPO methods, we propose carps, a benchmark framework for Comprehensive Automated Research Performance Studies allowing to evaluate N optimizers on M benchmark tasks. In this first release of carps, we focus on the four most important types of HPO task types: blackbox, multi-fidelity, multi-objective and multi-fidelity-multi-objective. With 3 336 tasks from 5 community benchmark collections and 28 variants of 9 optimizer families, we offer the biggest go-to library to date to evaluate and compare HPO methods. The carps framework relies on a purpose-built, lightweight interface, gluing together optimizers and benchmark tasks. It also features an analysis pipeline, facilitating the evaluation of optimizers on benchmarks. However, navigating a huge number of tasks while developing and comparing methods can be computationally infeasible. To address this, we obtain a subset of representative tasks by minimizing the star discrepancy of the subset, in the space spanned by the full set. As a result, we propose an initial subset of 10 to 30 diverse tasks for each task type, and include functionality to re-compute subsets as more benchmarks become available, enabling efficient evaluations. We also establish a first set of baseline results on these tasks as a measure for future comparisons. With carps (https://www.github.com/automl/CARP-S), we make an important step in the standardization of HPO evaluation.
Neural Attention Search
Feb 20, 2025We present Neural Attention Search (NAtS), a framework that automatically evaluates the importance of each token within a sequence and determines if the corresponding token can be dropped after several steps. This approach can efficiently reduce the KV cache sizes required by transformer-based models during inference and thus reduce inference costs. In this paper, we design a search space that contains three token types: (i) Global Tokens will be preserved and queried by all the following tokens. (ii) Local Tokens survive until the next global token appears. (iii) Sliding Window Tokens have an impact on the inference of a fixed size of the next following tokens. Similar to the One-Shot Neural Architecture Search approach, this token-type information can be learned jointly with the architecture weights via a learnable attention mask. Experiments on both training a new transformer from scratch and fine-tuning existing large language models show that NAtS can efficiently reduce the KV cache size required for the models while maintaining the models' performance.
Optimizing Time Series Forecasting Architectures: A Hierarchical Neural Architecture Search Approach
Jun 07, 2024
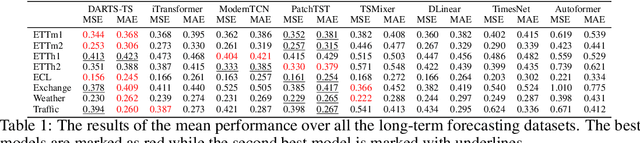
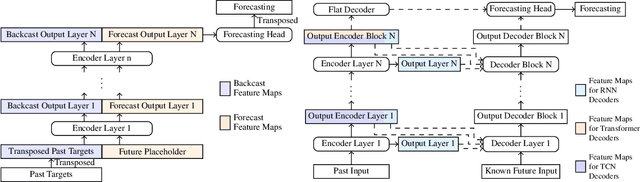

The rapid development of time series forecasting research has brought many deep learning-based modules in this field. However, despite the increasing amount of new forecasting architectures, it is still unclear if we have leveraged the full potential of these existing modules within a properly designed architecture. In this work, we propose a novel hierarchical neural architecture search approach for time series forecasting tasks. With the design of a hierarchical search space, we incorporate many architecture types designed for forecasting tasks and allow for the efficient combination of different forecasting architecture modules. Results on long-term-time-series-forecasting tasks show that our approach can search for lightweight high-performing forecasting architectures across different forecasting tasks.
AutoML in the Age of Large Language Models: Current Challenges, Future Opportunities and Risks
Jun 13, 2023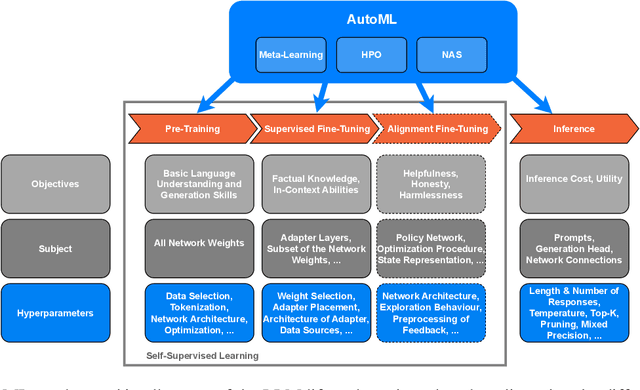
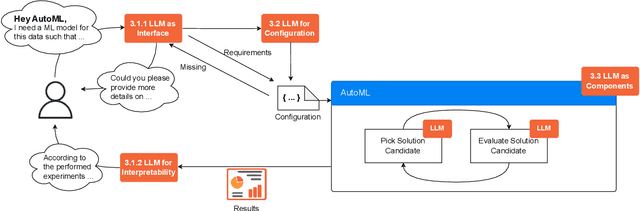
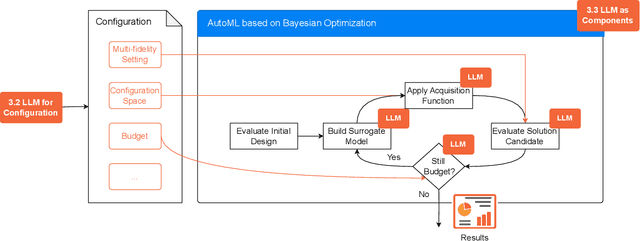
The fields of both Natural Language Processing (NLP) and Automated Machine Learning (AutoML) have achieved remarkable results over the past years. In NLP, especially Large Language Models (LLMs) have experienced a rapid series of breakthroughs very recently. We envision that the two fields can radically push the boundaries of each other through tight integration. To showcase this vision, we explore the potential of a symbiotic relationship between AutoML and LLMs, shedding light on how they can benefit each other. In particular, we investigate both the opportunities to enhance AutoML approaches with LLMs from different perspectives and the challenges of leveraging AutoML to further improve LLMs. To this end, we survey existing work, and we critically assess risks. We strongly believe that the integration of the two fields has the potential to disrupt both fields, NLP and AutoML. By highlighting conceivable synergies, but also risks, we aim to foster further exploration at the intersection of AutoML and LLMs.
Efficient Automated Deep Learning for Time Series Forecasting
May 13, 2022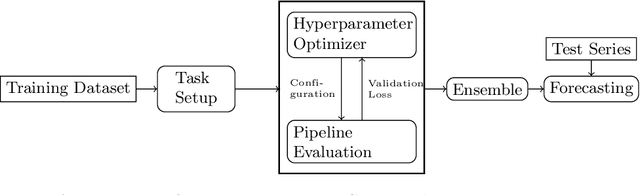
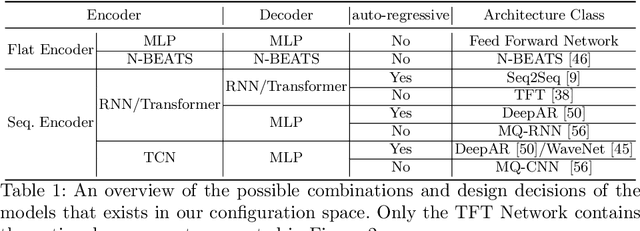
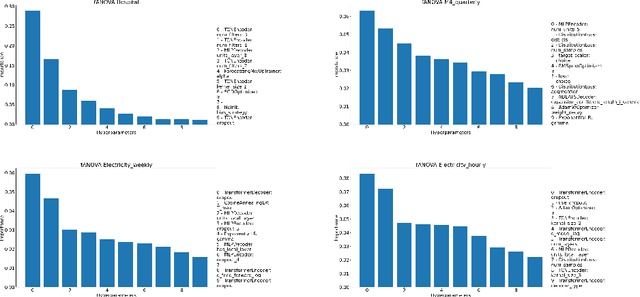
Recent years have witnessed tremendously improved efficiency of Automated Machine Learning (AutoML), especially Automated Deep Learning (AutoDL) systems, but recent work focuses on tabular, image, or NLP tasks. So far, little attention has been paid to general AutoDL frameworks for time series forecasting, despite the enormous success in applying different novel architectures to such tasks. In this paper, we propose an efficient approach for the joint optimization of neural architecture and hyperparameters of the entire data processing pipeline for time series forecasting. In contrast to common NAS search spaces, we designed a novel neural architecture search space covering various state-of-the-art architectures, allowing for an efficient macro-search over different DL approaches. To efficiently search in such a large configuration space, we use Bayesian optimization with multi-fidelity optimization. We empirically study several different budget types enabling efficient multi-fidelity optimization on different forecasting datasets. Furthermore, we compared our resulting system, dubbed Auto-PyTorch-TS, against several established baselines and show that it significantly outperforms all of them across several datasets.
Searching in the Forest for Local Bayesian Optimization
Nov 10, 2021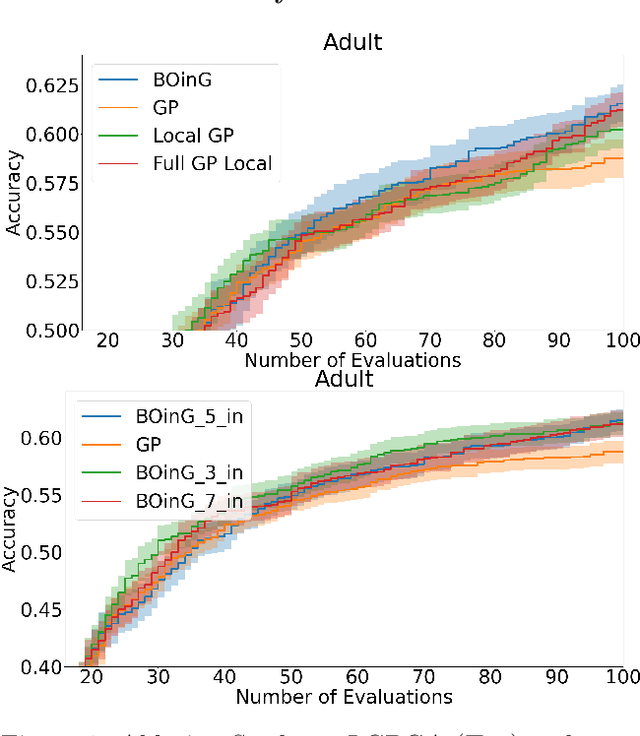
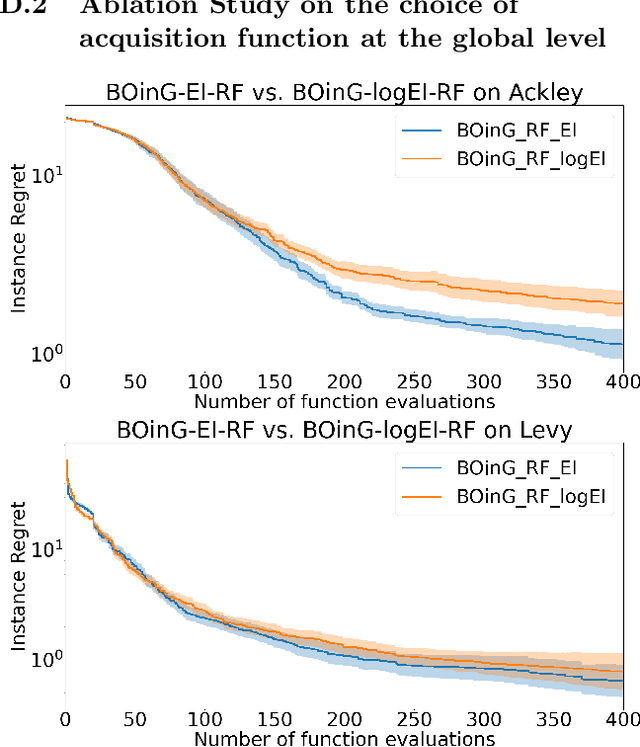
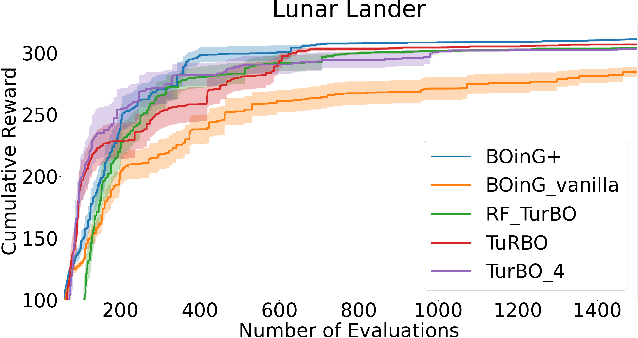
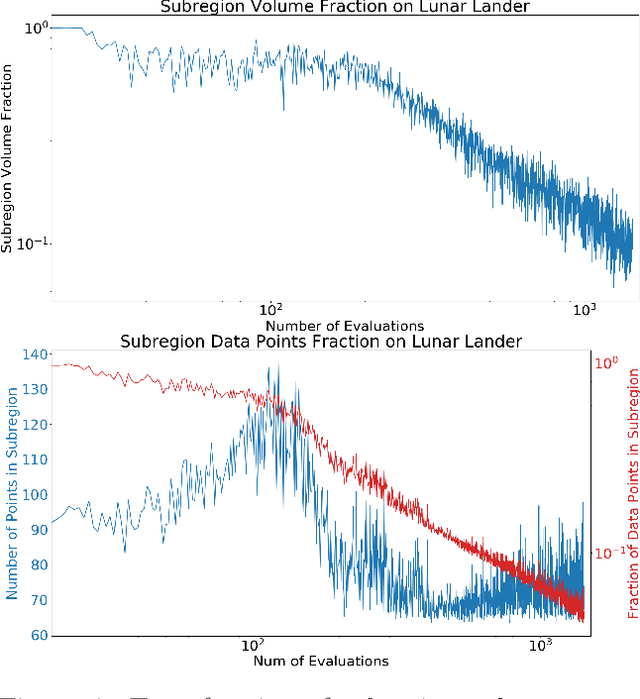
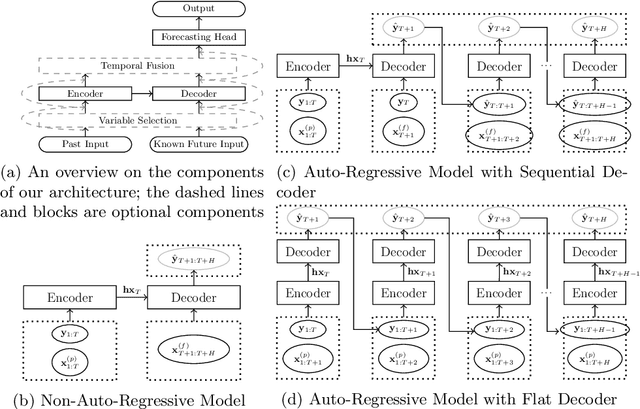
Because of its sample efficiency, Bayesian optimization (BO) has become a popular approach dealing with expensive black-box optimization problems, such as hyperparameter optimization (HPO). Recent empirical experiments showed that the loss landscapes of HPO problems tend to be more benign than previously assumed, i.e. in the best case uni-modal and convex, such that a BO framework could be more efficient if it can focus on those promising local regions. In this paper, we propose BOinG, a two-stage approach that is tailored toward mid-sized configuration spaces, as one encounters in many HPO problems. In the first stage, we build a scalable global surrogate model with a random forest to describe the overall landscape structure. Further, we choose a promising subregion via a bottom-up approach on the upper-level tree structure. In the second stage, a local model in this subregion is utilized to suggest the point to be evaluated next. Empirical experiments show that BOinG is able to exploit the structure of typical HPO problems and performs particularly well on mid-sized problems from synthetic functions and HPO.
SMAC3: A Versatile Bayesian Optimization Package for Hyperparameter Optimization
Sep 20, 2021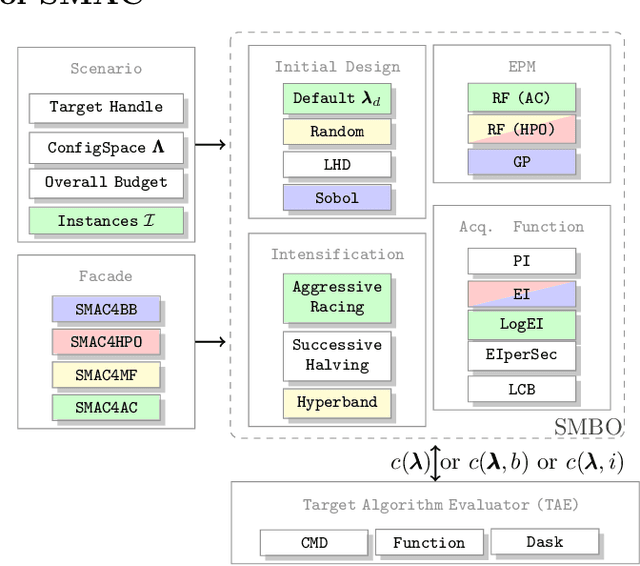
Algorithm parameters, in particular hyperparameters of machine learning algorithms, can substantially impact their performance. To support users in determining well-performing hyperparameter configurations for their algorithms, datasets and applications at hand, SMAC3 offers a robust and flexible framework for Bayesian Optimization, which can improve performance within a few evaluations. It offers several facades and pre-sets for typical use cases, such as optimizing hyperparameters, solving low dimensional continuous (artificial) global optimization problems and configuring algorithms to perform well across multiple problem instances. The SMAC3 package is available under a permissive BSD-license at https://github.com/automl/SMAC3.
Hyperparameter Optimization: Foundations, Algorithms, Best Practices and Open Challenges
Jul 14, 2021
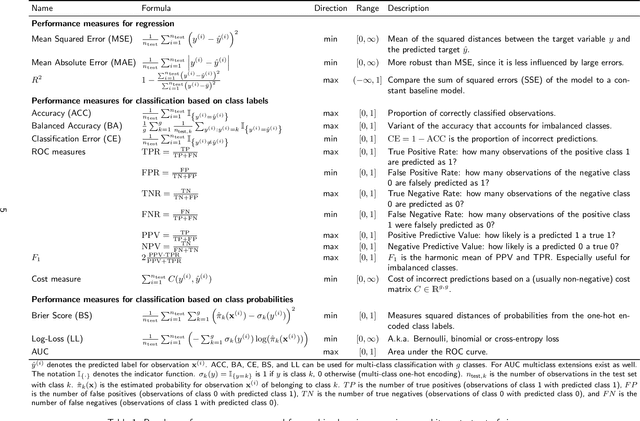
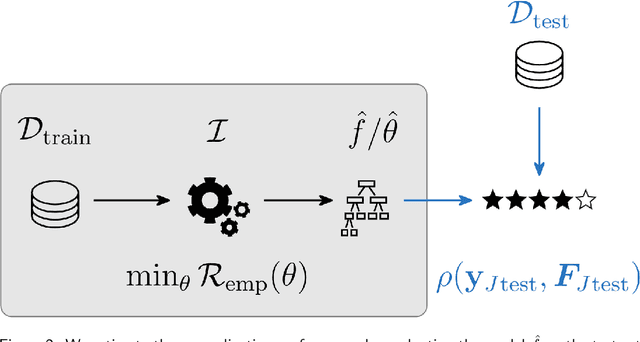
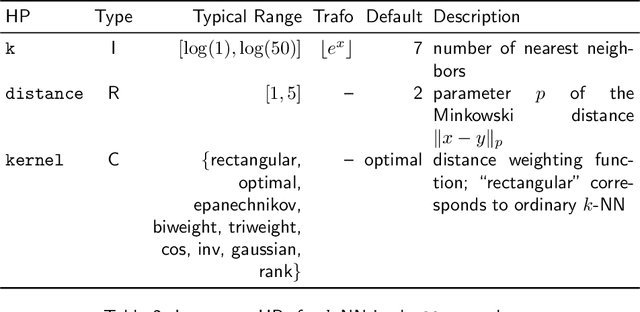
Most machine learning algorithms are configured by one or several hyperparameters that must be carefully chosen and often considerably impact performance. To avoid a time consuming and unreproducible manual trial-and-error process to find well-performing hyperparameter configurations, various automatic hyperparameter optimization (HPO) methods, e.g., based on resampling error estimation for supervised machine learning, can be employed. After introducing HPO from a general perspective, this paper reviews important HPO methods such as grid or random search, evolutionary algorithms, Bayesian optimization, Hyperband and racing. It gives practical recommendations regarding important choices to be made when conducting HPO, including the HPO algorithms themselves, performance evaluation, how to combine HPO with ML pipelines, runtime improvements, and parallelization.
Bag of Baselines for Multi-objective Joint Neural Architecture Search and Hyperparameter Optimization
May 03, 2021
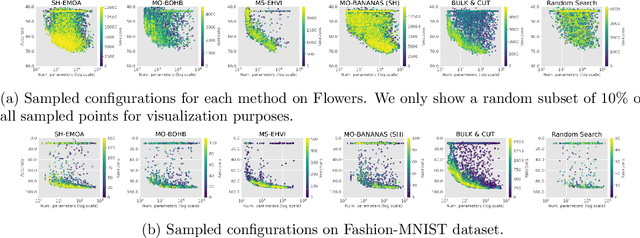
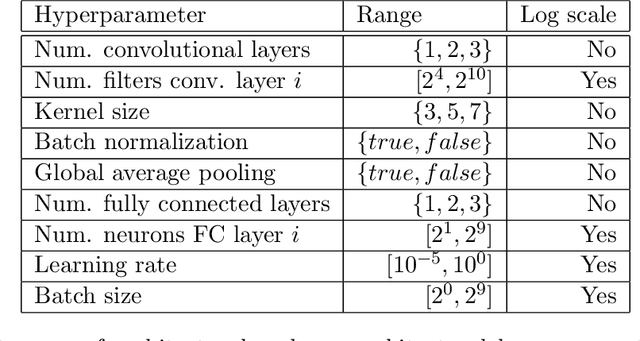
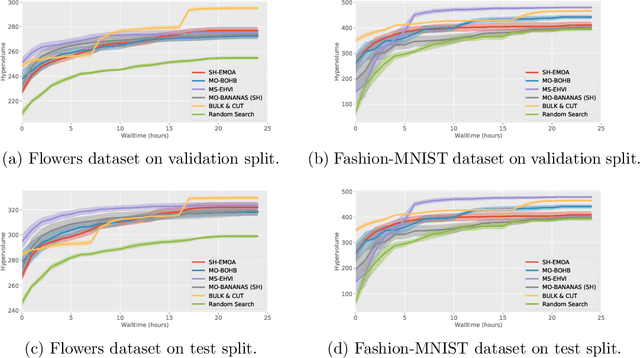
Neural architecture search (NAS) and hyperparameter optimization (HPO) make deep learning accessible to non-experts by automatically finding the architecture of the deep neural network to use and tuning the hyperparameters of the used training pipeline. While both NAS and HPO have been studied extensively in recent years, NAS methods typically assume fixed hyperparameters and vice versa - there exists little work on joint NAS + HPO. Furthermore, NAS has recently often been framed as a multi-objective optimization problem, in order to take, e.g., resource requirements into account. In this paper, we propose a set of methods that extend current approaches to jointly optimize neural architectures and hyperparameters with respect to multiple objectives. We hope that these methods will serve as simple baselines for future research on multi-objective joint NAS + HPO. To facilitate this, all our code is available at https://github.com/automl/multi-obj-baselines.