 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecarps: A Framework for Comparing N Hyperparameter Optimizers on M Benchmarks
Jun 06, 2025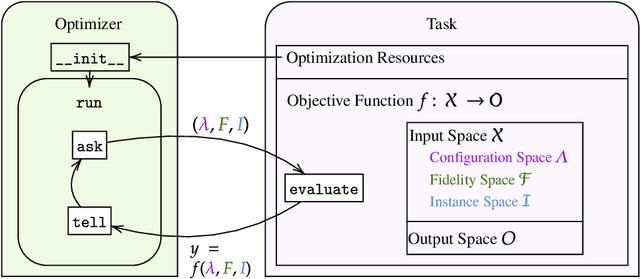

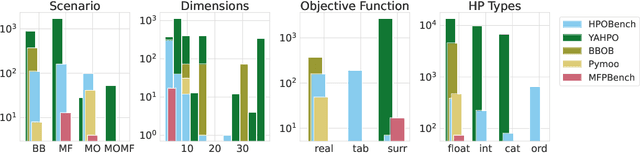
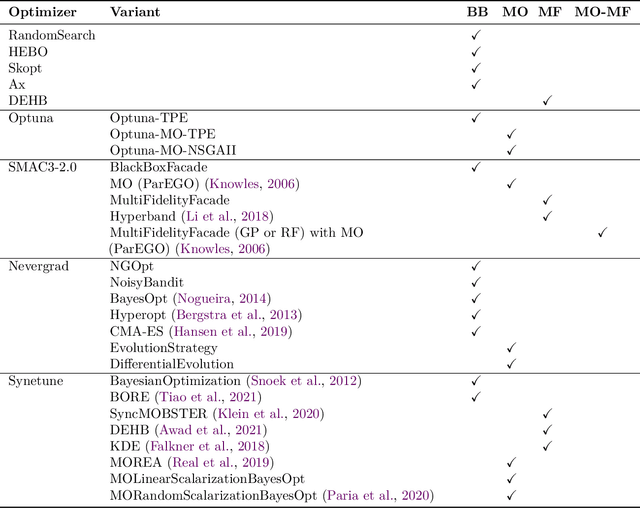
Hyperparameter Optimization (HPO) is crucial to develop well-performing machine learning models. In order to ease prototyping and benchmarking of HPO methods, we propose carps, a benchmark framework for Comprehensive Automated Research Performance Studies allowing to evaluate N optimizers on M benchmark tasks. In this first release of carps, we focus on the four most important types of HPO task types: blackbox, multi-fidelity, multi-objective and multi-fidelity-multi-objective. With 3 336 tasks from 5 community benchmark collections and 28 variants of 9 optimizer families, we offer the biggest go-to library to date to evaluate and compare HPO methods. The carps framework relies on a purpose-built, lightweight interface, gluing together optimizers and benchmark tasks. It also features an analysis pipeline, facilitating the evaluation of optimizers on benchmarks. However, navigating a huge number of tasks while developing and comparing methods can be computationally infeasible. To address this, we obtain a subset of representative tasks by minimizing the star discrepancy of the subset, in the space spanned by the full set. As a result, we propose an initial subset of 10 to 30 diverse tasks for each task type, and include functionality to re-compute subsets as more benchmarks become available, enabling efficient evaluations. We also establish a first set of baseline results on these tasks as a measure for future comparisons. With carps (https://www.github.com/automl/CARP-S), we make an important step in the standardization of HPO evaluation.
AutoML in the Age of Large Language Models: Current Challenges, Future Opportunities and Risks
Jun 13, 2023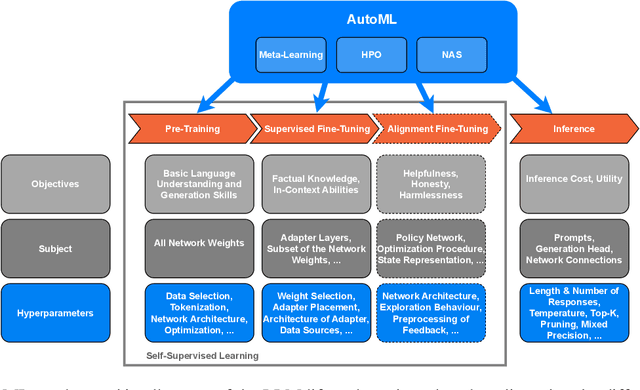
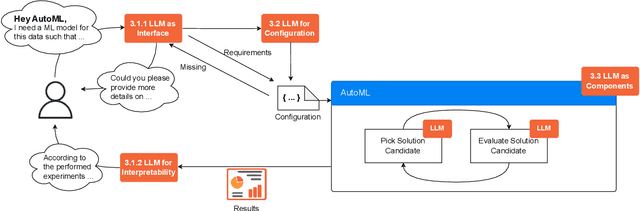
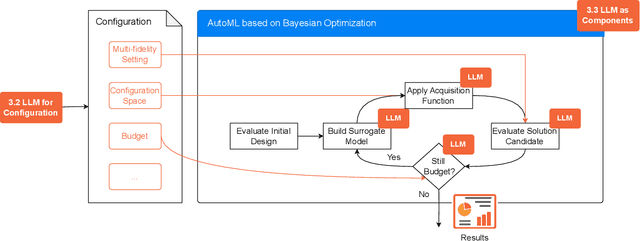
The fields of both Natural Language Processing (NLP) and Automated Machine Learning (AutoML) have achieved remarkable results over the past years. In NLP, especially Large Language Models (LLMs) have experienced a rapid series of breakthroughs very recently. We envision that the two fields can radically push the boundaries of each other through tight integration. To showcase this vision, we explore the potential of a symbiotic relationship between AutoML and LLMs, shedding light on how they can benefit each other. In particular, we investigate both the opportunities to enhance AutoML approaches with LLMs from different perspectives and the challenges of leveraging AutoML to further improve LLMs. To this end, we survey existing work, and we critically assess risks. We strongly believe that the integration of the two fields has the potential to disrupt both fields, NLP and AutoML. By highlighting conceivable synergies, but also risks, we aim to foster further exploration at the intersection of AutoML and LLMs.
Towards Meta-learned Algorithm Selection using Implicit Fidelity Information
Jun 07, 2022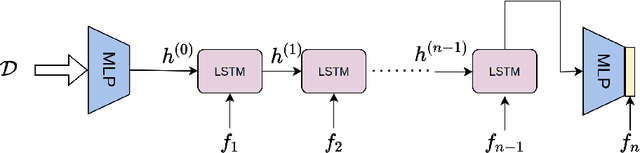
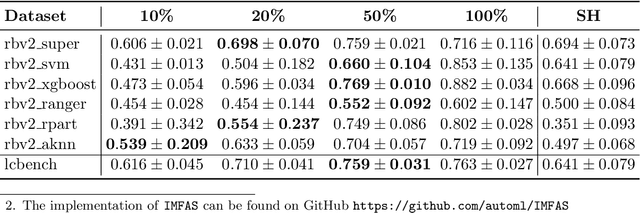

Automatically selecting the best performing algorithm for a given dataset or ranking multiple of them by their expected performance supports users in developing new machine learning applications. Most approaches for this problem rely on dataset meta-features and landmarking performances to capture the salient topology of the datasets and those topologies that the algorithms attend to. Landmarking usually exploits cheap algorithms not necessarily in the pool of candidate algorithms to get inexpensive approximations of the topology. While somewhat indicative, handcrafted dataset meta-features and landmarks are likely insufficient descriptors, strongly depending on the alignment of the geometries the landmarks and candidates search for. We propose IMFAS, a method to exploit multi-fidelity landmarking information directly from the candidate algorithms in the form of non-parametrically non-myopic meta-learned learning curves via LSTM networks in a few-shot setting during testing. Using this mechanism, IMFAS jointly learns the topology of of the datasets and the inductive biases of algorithms without expensively training them to convergence. IMFAS produces informative landmarks, easily enriched by arbitrary meta-features at a low computational cost, capable of producing the desired ranking using cheaper fidelities. We additionally show that it is able to beat Successive Halving with at most half the fidelity sequence during test time