 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Meta-learned Algorithm Selection using Implicit Fidelity Information
Paper and Code
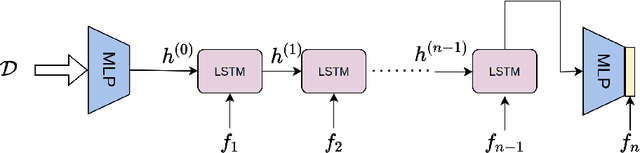
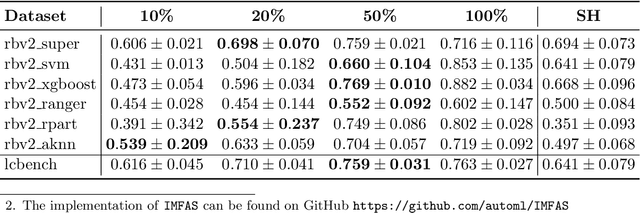
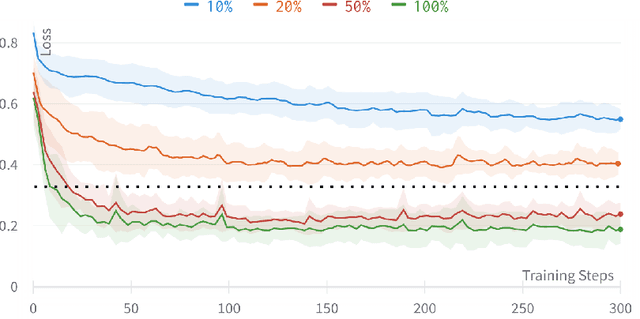

Automatically selecting the best performing algorithm for a given dataset or ranking multiple of them by their expected performance supports users in developing new machine learning applications. Most approaches for this problem rely on dataset meta-features and landmarking performances to capture the salient topology of the datasets and those topologies that the algorithms attend to. Landmarking usually exploits cheap algorithms not necessarily in the pool of candidate algorithms to get inexpensive approximations of the topology. While somewhat indicative, handcrafted dataset meta-features and landmarks are likely insufficient descriptors, strongly depending on the alignment of the geometries the landmarks and candidates search for. We propose IMFAS, a method to exploit multi-fidelity landmarking information directly from the candidate algorithms in the form of non-parametrically non-myopic meta-learned learning curves via LSTM networks in a few-shot setting during testing. Using this mechanism, IMFAS jointly learns the topology of of the datasets and the inductive biases of algorithms without expensively training them to convergence. IMFAS produces informative landmarks, easily enriched by arbitrary meta-features at a low computational cost, capable of producing the desired ranking using cheaper fidelities. We additionally show that it is able to beat Successive Halving with at most half the fidelity sequence during test time