 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-shot World Models Using a Transformer Trained on a Synthetic Prior
Sep 21, 2024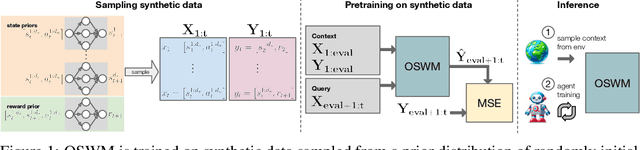

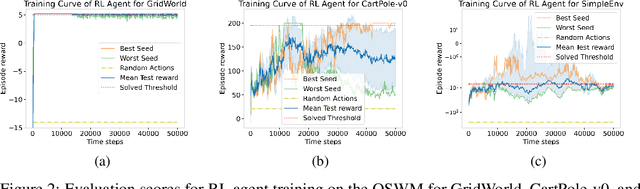

A World Model is a compressed spatial and temporal representation of a real world environment that allows one to train an agent or execute planning methods. However, world models are typically trained on observations from the real world environment, and they usually do not enable learning policies for other real environments. We propose One-Shot World Model (OSWM), a transformer world model that is learned in an in-context learning fashion from purely synthetic data sampled from a prior distribution. Our prior is composed of multiple randomly initialized neural networks, where each network models the dynamics of each state and reward dimension of a desired target environment. We adopt the supervised learning procedure of Prior-Fitted Networks by masking next-state and reward at random context positions and query OSWM to make probabilistic predictions based on the remaining transition context. During inference time, OSWM is able to quickly adapt to the dynamics of a simple grid world, as well as the CartPole gym and a custom control environment by providing 1k transition steps as context and is then able to successfully train environment-solving agent policies. However, transferring to more complex environments remains a challenge, currently. Despite these limitations, we see this work as an important stepping-stone in the pursuit of learning world models purely from synthetic data.
Bag of Baselines for Multi-objective Joint Neural Architecture Search and Hyperparameter Optimization
May 03, 2021
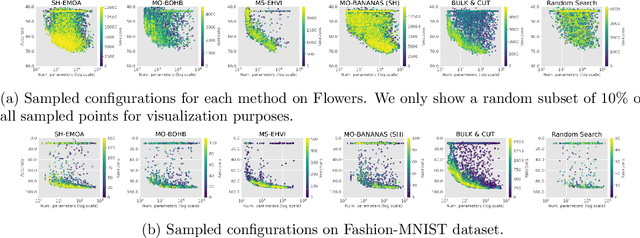
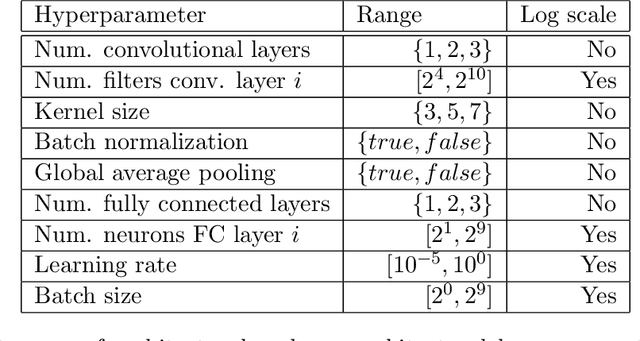
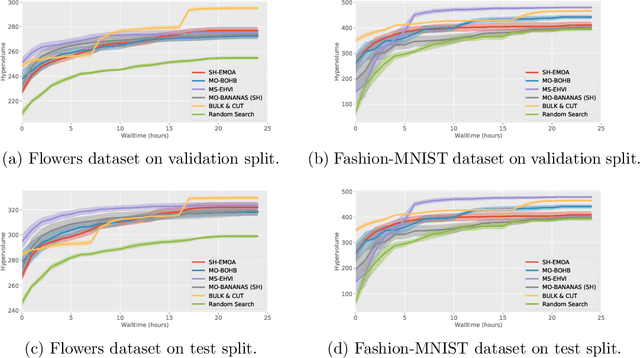
Neural architecture search (NAS) and hyperparameter optimization (HPO) make deep learning accessible to non-experts by automatically finding the architecture of the deep neural network to use and tuning the hyperparameters of the used training pipeline. While both NAS and HPO have been studied extensively in recent years, NAS methods typically assume fixed hyperparameters and vice versa - there exists little work on joint NAS + HPO. Furthermore, NAS has recently often been framed as a multi-objective optimization problem, in order to take, e.g., resource requirements into account. In this paper, we propose a set of methods that extend current approaches to jointly optimize neural architectures and hyperparameters with respect to multiple objectives. We hope that these methods will serve as simple baselines for future research on multi-objective joint NAS + HPO. To facilitate this, all our code is available at https://github.com/automl/multi-obj-baselines.