 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Efficient Transfer Learning via Supernet Transfer in Warm-started Neural Architecture Search
Paper and Code
Jul 26, 2024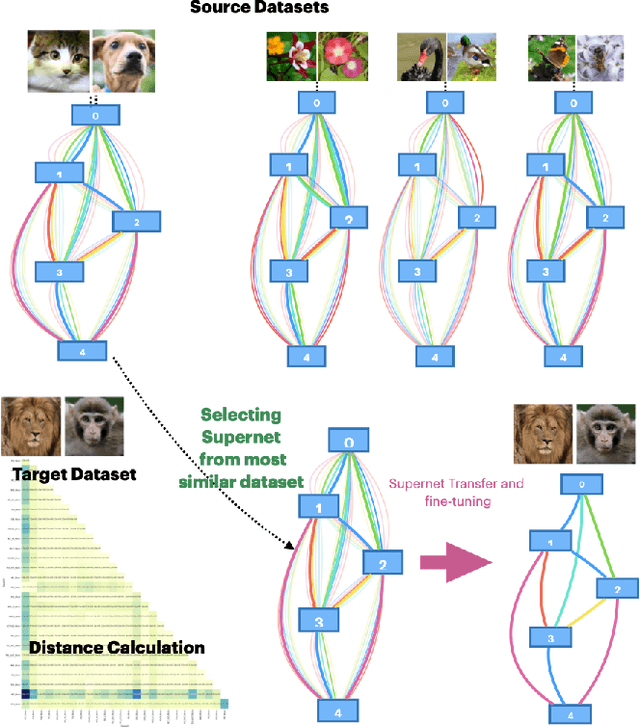
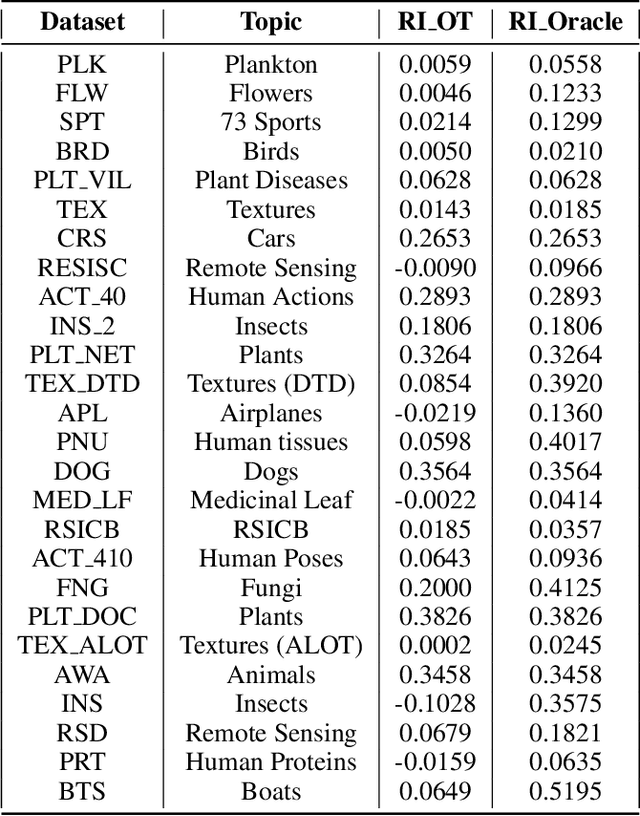
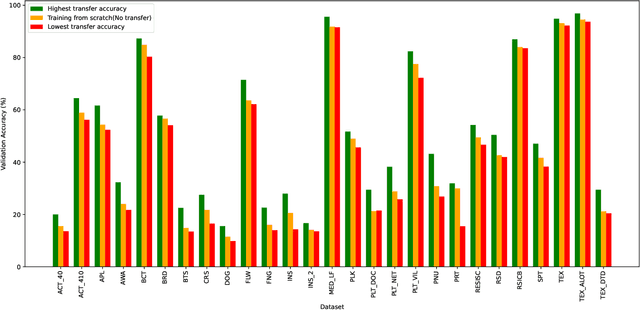
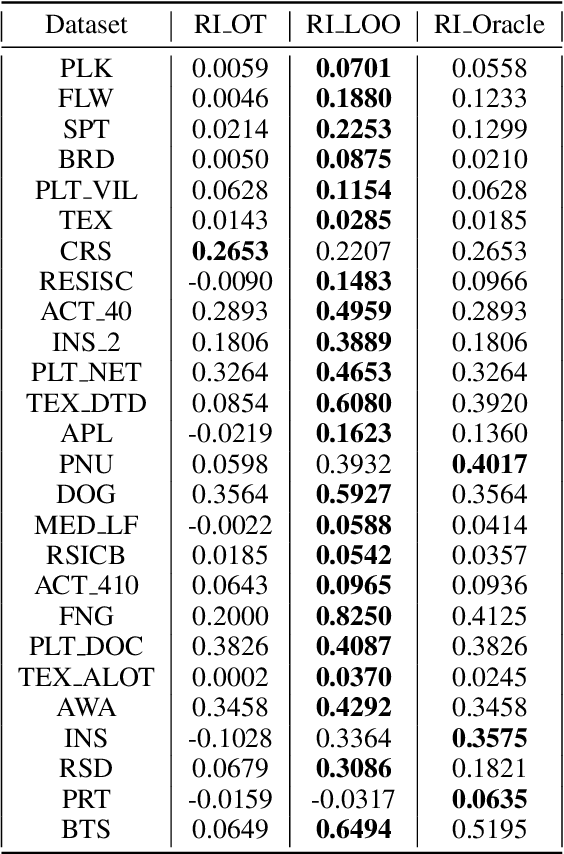
Hand-designing Neural Networks is a tedious process that requires significant expertise. Neural Architecture Search (NAS) frameworks offer a very useful and popular solution that helps to democratize AI. However, these NAS frameworks are often computationally expensive to run, which limits their applicability and accessibility. In this paper, we propose a novel transfer learning approach, capable of effectively transferring pretrained supernets based on Optimal Transport or multi-dataset pretaining. This method can be generally applied to NAS methods based on Differentiable Architecture Search (DARTS). Through extensive experiments across dozens of image classification tasks, we demonstrate that transferring pretrained supernets in this way can not only drastically speed up the supernet training which then finds optimal models (3 to 5 times faster on average), but even yield that outperform those found when running DARTS methods from scratch. We also observe positive transfer to almost all target datasets, making it very robust. Besides drastically improving the applicability of NAS methods, this also opens up new applications for continual learning and related fields.