 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline AutoML: An adaptive AutoML framework for online learning
Jan 24, 2022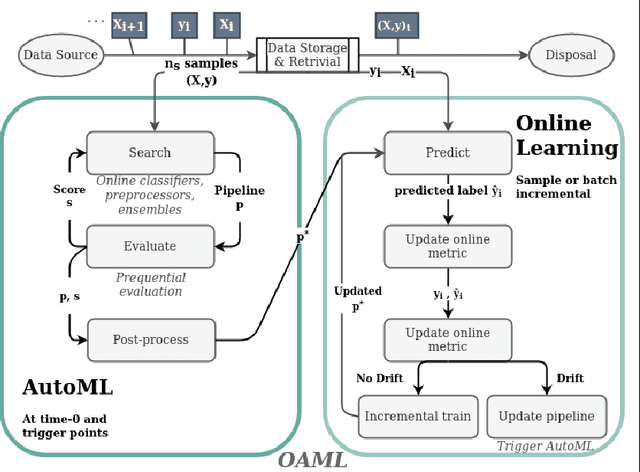
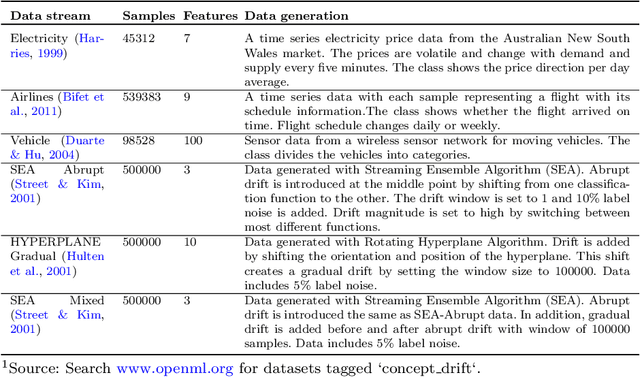
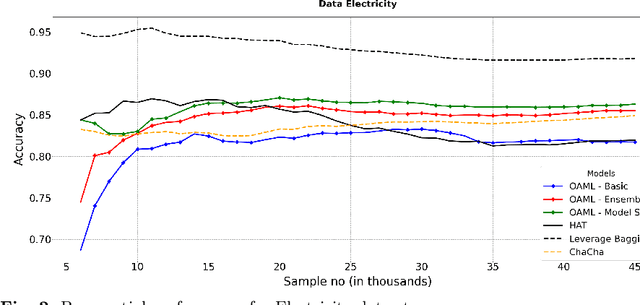
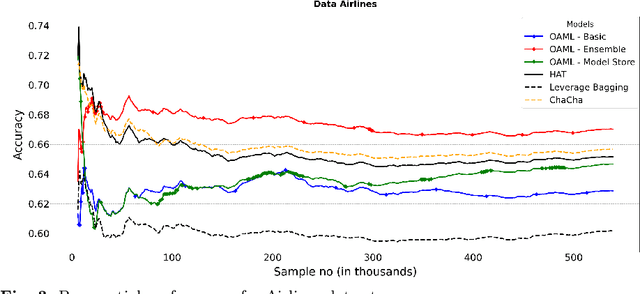
Automated Machine Learning (AutoML) has been used successfully in settings where the learning task is assumed to be static. In many real-world scenarios, however, the data distribution will evolve over time, and it is yet to be shown whether AutoML techniques can effectively design online pipelines in dynamic environments. This study aims to automate pipeline design for online learning while continuously adapting to data drift. For this purpose, we design an adaptive Online Automated Machine Learning (OAML) system, searching the complete pipeline configuration space of online learners, including preprocessing algorithms and ensembling techniques. This system combines the inherent adaptation capabilities of online learners with the fast automated pipeline (re)optimization capabilities of AutoML. Focusing on optimization techniques that can adapt to evolving objectives, we evaluate asynchronous genetic programming and asynchronous successive halving to optimize these pipelines continually. We experiment on real and artificial data streams with varying types of concept drift to test the performance and adaptation capabilities of the proposed system. The results confirm the utility of OAML over popular online learning algorithms and underscore the benefits of continuous pipeline redesign in the presence of data drift.
Adaptation Strategies for Automated Machine Learning on Evolving Data
Jun 09, 2020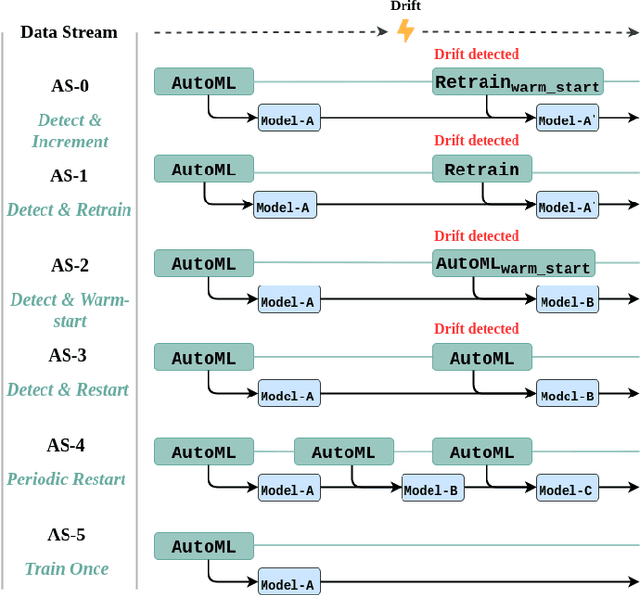
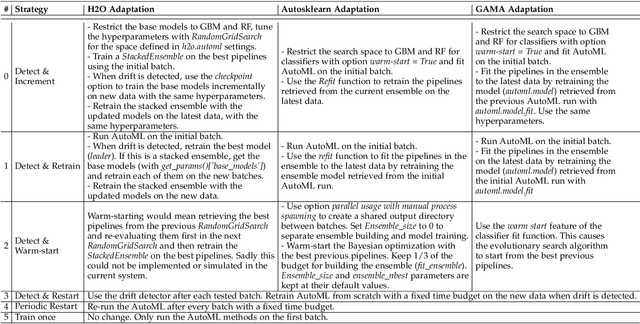

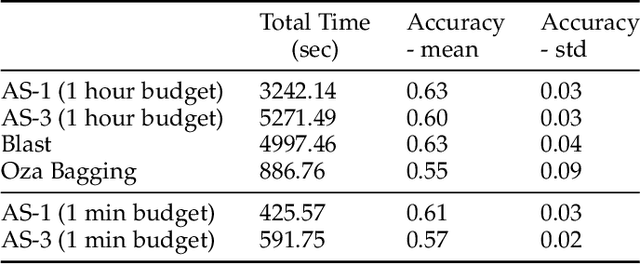
Automated Machine Learning (AutoML) systems have been shown to efficiently build good models for new datasets.However, it is often not clear how well they can adapt when the data evolves over time. The main goal of this study is to understand the effect of data stream challenges such as concept drift on the performance of AutoML methods, and which adaptation strategies can be employed to make them more robust. To that end, we propose 6 concept drift adaptation strategies and evaluate their effectiveness on different AutoML approaches. We do this for a variety of AutoML approaches for building machine learning pipelines, including those that leverage Bayesian optimization, genetic programming, and random search with automated stacking. These are evaluated empirically on real-world and synthetic data streams with different types of concept drift. Based on this analysis, we propose ways to develop more sophisticated and robust AutoML techniques.