 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Any Video with Scalable Synthetic Data
Oct 14, 2024



Video depth estimation has long been hindered by the scarcity of consistent and scalable ground truth data, leading to inconsistent and unreliable results. In this paper, we introduce Depth Any Video, a model that tackles the challenge through two key innovations. First, we develop a scalable synthetic data pipeline, capturing real-time video depth data from diverse synthetic environments, yielding 40,000 video clips of 5-second duration, each with precise depth annotations. Second, we leverage the powerful priors of generative video diffusion models to handle real-world videos effectively, integrating advanced techniques such as rotary position encoding and flow matching to further enhance flexibility and efficiency. Unlike previous models, which are limited to fixed-length video sequences, our approach introduces a novel mixed-duration training strategy that handles videos of varying lengths and performs robustly across different frame rates-even on single frames. At inference, we propose a depth interpolation method that enables our model to infer high-resolution video depth across sequences of up to 150 frames. Our model outperforms all previous generative depth models in terms of spatial accuracy and temporal consistency.
SPA: 3D Spatial-Awareness Enables Effective Embodied Representation
Oct 10, 2024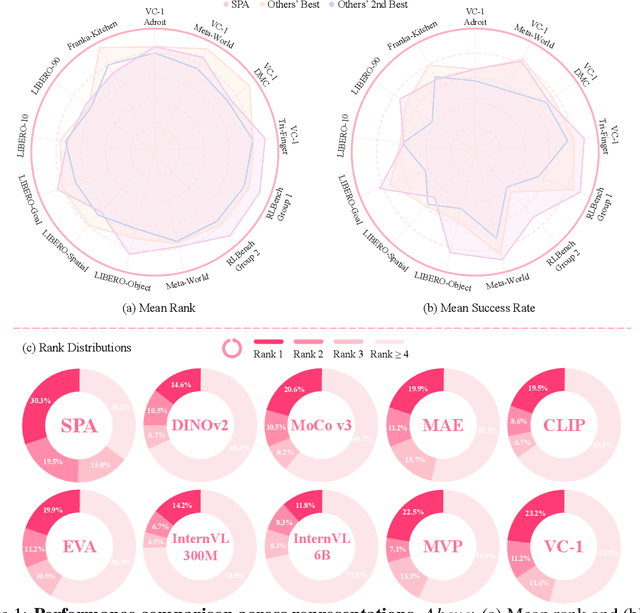
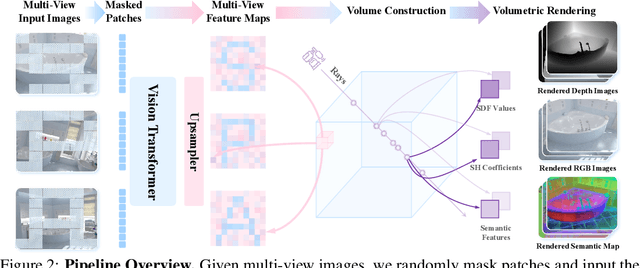

In this paper, we introduce SPA, a novel representation learning framework that emphasizes the importance of 3D spatial awareness in embodied AI. Our approach leverages differentiable neural rendering on multi-view images to endow a vanilla Vision Transformer (ViT) with intrinsic spatial understanding. We present the most comprehensive evaluation of embodied representation learning to date, covering 268 tasks across 8 simulators with diverse policies in both single-task and language-conditioned multi-task scenarios. The results are compelling: SPA consistently outperforms more than 10 state-of-the-art representation methods, including those specifically designed for embodied AI, vision-centric tasks, and multi-modal applications, while using less training data. Furthermore, we conduct a series of real-world experiments to confirm its effectiveness in practical scenarios. These results highlight the critical role of 3D spatial awareness for embodied representation learning. Our strongest model takes more than 6000 GPU hours to train and we are committed to open-sourcing all code and model weights to foster future research in embodied representation learning. Project Page: https://haoyizhu.github.io/spa/.
PonderV2: Pave the Way for 3D Foundation Model with A Universal Pre-training Paradigm
Oct 13, 2023
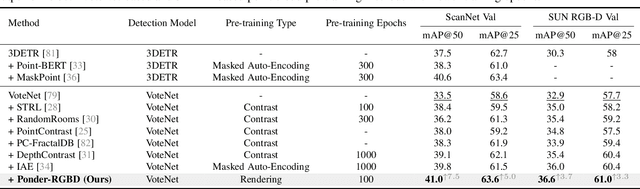
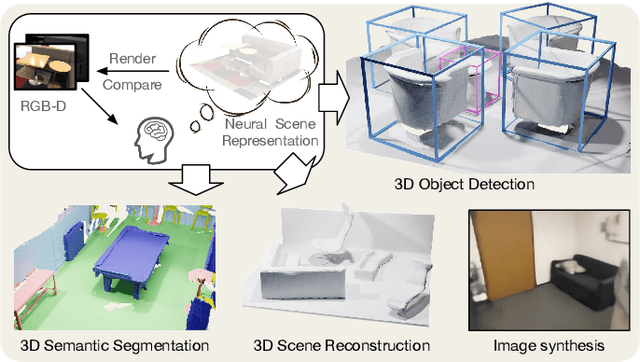

In contrast to numerous NLP and 2D computer vision foundational models, the learning of a robust and highly generalized 3D foundational model poses considerably greater challenges. This is primarily due to the inherent data variability and the diversity of downstream tasks. In this paper, we introduce a comprehensive 3D pre-training framework designed to facilitate the acquisition of efficient 3D representations, thereby establishing a pathway to 3D foundational models. Motivated by the fact that informative 3D features should be able to encode rich geometry and appearance cues that can be utilized to render realistic images, we propose a novel universal paradigm to learn point cloud representations by differentiable neural rendering, serving as a bridge between 3D and 2D worlds. We train a point cloud encoder within a devised volumetric neural renderer by comparing the rendered images with the real images. Notably, our approach demonstrates the seamless integration of the learned 3D encoder into diverse downstream tasks. These tasks encompass not only high-level challenges such as 3D detection and segmentation but also low-level objectives like 3D reconstruction and image synthesis, spanning both indoor and outdoor scenarios. Besides, we also illustrate the capability of pre-training a 2D backbone using the proposed universal methodology, surpassing conventional pre-training methods by a large margin. For the first time, PonderV2 achieves state-of-the-art performance on 11 indoor and outdoor benchmarks. The consistent improvements in various settings imply the effectiveness of the proposed method. Code and models will be made available at https://github.com/OpenGVLab/PonderV2.
UniPAD: A Universal Pre-training Paradigm for Autonomous Driving
Oct 12, 2023



In the context of autonomous driving, the significance of effective feature learning is widely acknowledged. While conventional 3D self-supervised pre-training methods have shown widespread success, most methods follow the ideas originally designed for 2D images. In this paper, we present UniPAD, a novel self-supervised learning paradigm applying 3D volumetric differentiable rendering. UniPAD implicitly encodes 3D space, facilitating the reconstruction of continuous 3D shape structures and the intricate appearance characteristics of their 2D projections. The flexibility of our method enables seamless integration into both 2D and 3D frameworks, enabling a more holistic comprehension of the scenes. We manifest the feasibility and effectiveness of UniPAD by conducting extensive experiments on various downstream 3D tasks. Our method significantly improves lidar-, camera-, and lidar-camera-based baseline by 9.1, 7.7, and 6.9 NDS, respectively. Notably, our pre-training pipeline achieves 73.2 NDS for 3D object detection and 79.4 mIoU for 3D semantic segmentation on the nuScenes validation set, achieving state-of-the-art results in comparison with previous methods. The code will be available at https://github.com/Nightmare-n/UniPAD.
M$^3$CS: Multi-Target Masked Point Modeling with Learnable Codebook and Siamese Decoders
Sep 23, 2023Masked point modeling has become a promising scheme of self-supervised pre-training for point clouds. Existing methods reconstruct either the original points or related features as the objective of pre-training. However, considering the diversity of downstream tasks, it is necessary for the model to have both low- and high-level representation modeling capabilities to capture geometric details and semantic contexts during pre-training. To this end, M$^3$CS is proposed to enable the model with the above abilities. Specifically, with masked point cloud as input, M$^3$CS introduces two decoders to predict masked representations and the original points simultaneously. While an extra decoder doubles parameters for the decoding process and may lead to overfitting, we propose siamese decoders to keep the amount of learnable parameters unchanged. Further, we propose an online codebook projecting continuous tokens into discrete ones before reconstructing masked points. In such way, we can enforce the decoder to take effect through the combinations of tokens rather than remembering each token. Comprehensive experiments show that M$^3$CS achieves superior performance at both classification and segmentation tasks, outperforming existing methods.
PVT-SSD: Single-Stage 3D Object Detector with Point-Voxel Transformer
May 11, 2023



Recent Transformer-based 3D object detectors learn point cloud features either from point- or voxel-based representations. However, the former requires time-consuming sampling while the latter introduces quantization errors. In this paper, we present a novel Point-Voxel Transformer for single-stage 3D detection (PVT-SSD) that takes advantage of these two representations. Specifically, we first use voxel-based sparse convolutions for efficient feature encoding. Then, we propose a Point-Voxel Transformer (PVT) module that obtains long-range contexts in a cheap manner from voxels while attaining accurate positions from points. The key to associating the two different representations is our introduced input-dependent Query Initialization module, which could efficiently generate reference points and content queries. Then, PVT adaptively fuses long-range contextual and local geometric information around reference points into content queries. Further, to quickly find the neighboring points of reference points, we design the Virtual Range Image module, which generalizes the native range image to multi-sensor and multi-frame. The experiments on several autonomous driving benchmarks verify the effectiveness and efficiency of the proposed method. Code will be available at https://github.com/Nightmare-n/PVT-SSD.
GD-MAE: Generative Decoder for MAE Pre-training on LiDAR Point Clouds
Dec 07, 2022Despite the tremendous progress of Masked Autoencoders (MAE) in developing vision tasks such as image and video, exploring MAE in large-scale 3D point clouds remains challenging due to the inherent irregularity. In contrast to previous 3D MAE frameworks, which either design a complex decoder to infer masked information from maintained regions or adopt sophisticated masking strategies, we instead propose a much simpler paradigm. The core idea is to apply a \textbf{G}enerative \textbf{D}ecoder for MAE (GD-MAE) to automatically merges the surrounding context to restore the masked geometric knowledge in a hierarchical fusion manner. In doing so, our approach is free from introducing the heuristic design of decoders and enjoys the flexibility of exploring various masking strategies. The corresponding part costs less than \textbf{12\%} latency compared with conventional methods, while achieving better performance. We demonstrate the efficacy of the proposed method on several large-scale benchmarks: Waymo, KITTI, and ONCE. Consistent improvement on downstream detection tasks illustrates strong robustness and generalization capability. Not only our method reveals state-of-the-art results, but remarkably, we achieve comparable accuracy even with \textbf{20\%} of the labeled data on the Waymo dataset. The code will be released at \url{https://github.com/Nightmare-n/GD-MAE}.
3D-QueryIS: A Query-based Framework for 3D Instance Segmentation
Nov 17, 2022Previous top-performing methods for 3D instance segmentation often maintain inter-task dependencies and the tendency towards a lack of robustness. Besides, inevitable variations of different datasets make these methods become particularly sensitive to hyper-parameter values and manifest poor generalization capability. In this paper, we address the aforementioned challenges by proposing a novel query-based method, termed as 3D-QueryIS, which is detector-free, semantic segmentation-free, and cluster-free. Specifically, we propose to generate representative points in an implicit manner, and use them together with the initial queries to generate the informative instance queries. Then, the class and binary instance mask predictions can be produced by simply applying MLP layers on top of the instance queries and the extracted point cloud embeddings. Thus, our 3D-QueryIS is free from the accumulated errors caused by the inter-task dependencies. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness and efficiency of our proposed 3D-QueryIS method.
Graph R-CNN: Towards Accurate 3D Object Detection with Semantic-Decorated Local Graph
Aug 07, 2022Two-stage detectors have gained much popularity in 3D object detection. Most two-stage 3D detectors utilize grid points, voxel grids, or sampled keypoints for RoI feature extraction in the second stage. Such methods, however, are inefficient in handling unevenly distributed and sparse outdoor points. This paper solves this problem in three aspects. 1) Dynamic Point Aggregation. We propose the patch search to quickly search points in a local region for each 3D proposal. The dynamic farthest voxel sampling is then applied to evenly sample the points. Especially, the voxel size varies along the distance to accommodate the uneven distribution of points. 2) RoI-graph Pooling. We build local graphs on the sampled points to better model contextual information and mine point relations through iterative message passing. 3) Visual Features Augmentation. We introduce a simple yet effective fusion strategy to compensate for sparse LiDAR points with limited semantic cues. Based on these modules, we construct our Graph R-CNN as the second stage, which can be applied to existing one-stage detectors to consistently improve the detection performance. Extensive experiments show that Graph R-CNN outperforms the state-of-the-art 3D detection models by a large margin on both the KITTI and Waymo Open Dataset. And we rank first place on the KITTI BEV car detection leaderboard. Code will be available at \url{https://github.com/Nightmare-n/GraphRCNN}.
Sparse Fuse Dense: Towards High Quality 3D Detection with Depth Completion
Mar 18, 2022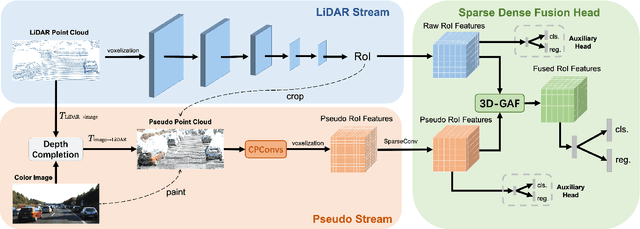
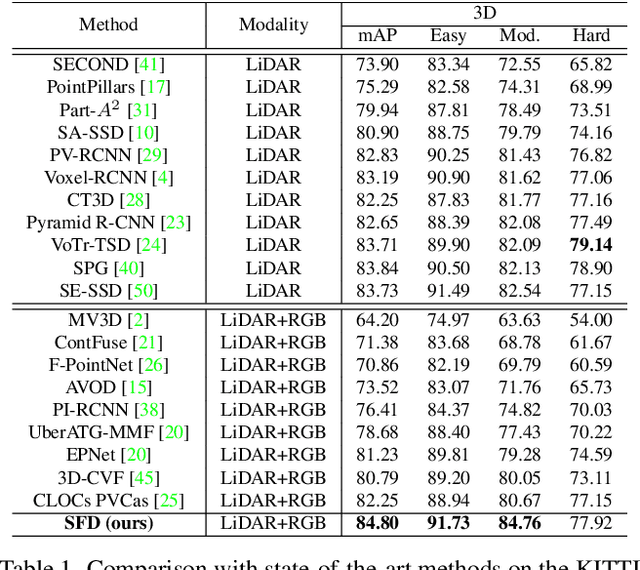
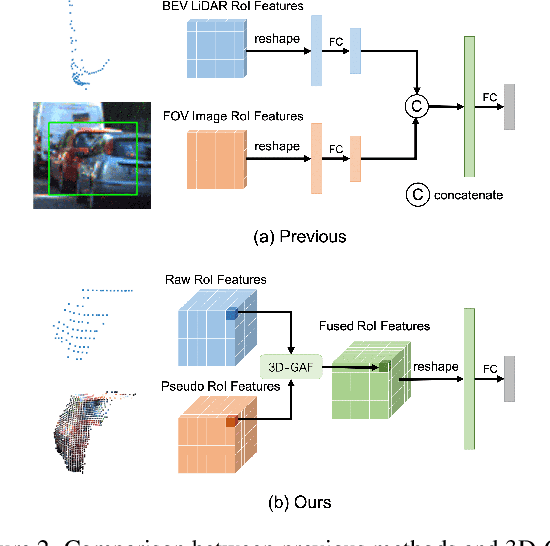
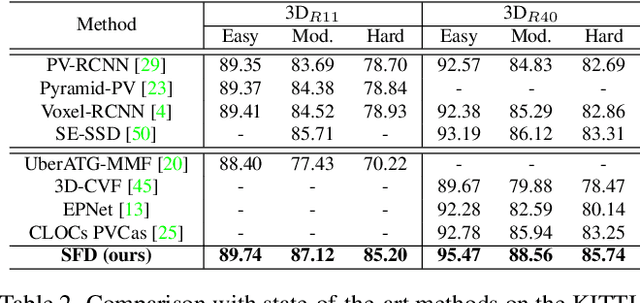
Current LiDAR-only 3D detection methods inevitably suffer from the sparsity of point clouds. Many multi-modal methods are proposed to alleviate this issue, while different representations of images and point clouds make it difficult to fuse them, resulting in suboptimal performance. In this paper, we present a novel multi-modal framework SFD (Sparse Fuse Dense), which utilizes pseudo point clouds generated from depth completion to tackle the issues mentioned above. Different from prior works, we propose a new RoI fusion strategy 3D-GAF (3D Grid-wise Attentive Fusion) to make fuller use of information from different types of point clouds. Specifically, 3D-GAF fuses 3D RoI features from the couple of point clouds in a grid-wise attentive way, which is more fine-grained and more precise. In addition, we propose a SynAugment (Synchronized Augmentation) to enable our multi-modal framework to utilize all data augmentation approaches tailored to LiDAR-only methods. Lastly, we customize an effective and efficient feature extractor CPConv (Color Point Convolution) for pseudo point clouds. It can explore 2D image features and 3D geometric features of pseudo point clouds simultaneously. Our method holds the highest entry on the KITTI car 3D object detection leaderboard, demonstrating the effectiveness of our SFD. Code will be made publicly available.