 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^3$CS: Multi-Target Masked Point Modeling with Learnable Codebook and Siamese Decoders
Sep 23, 2023Masked point modeling has become a promising scheme of self-supervised pre-training for point clouds. Existing methods reconstruct either the original points or related features as the objective of pre-training. However, considering the diversity of downstream tasks, it is necessary for the model to have both low- and high-level representation modeling capabilities to capture geometric details and semantic contexts during pre-training. To this end, M$^3$CS is proposed to enable the model with the above abilities. Specifically, with masked point cloud as input, M$^3$CS introduces two decoders to predict masked representations and the original points simultaneously. While an extra decoder doubles parameters for the decoding process and may lead to overfitting, we propose siamese decoders to keep the amount of learnable parameters unchanged. Further, we propose an online codebook projecting continuous tokens into discrete ones before reconstructing masked points. In such way, we can enforce the decoder to take effect through the combinations of tokens rather than remembering each token. Comprehensive experiments show that M$^3$CS achieves superior performance at both classification and segmentation tasks, outperforming existing methods.
SelFLoc: Selective Feature Fusion for Large-scale Point Cloud-based Place Recognition
Jun 05, 2023



Point cloud-based place recognition is crucial for mobile robots and autonomous vehicles, especially when the global positioning sensor is not accessible. LiDAR points are scattered on the surface of objects and buildings, which have strong shape priors along different axes. To enhance message passing along particular axes, Stacked Asymmetric Convolution Block (SACB) is designed, which is one of the main contributions in this paper. Comprehensive experiments demonstrate that asymmetric convolution and its corresponding strategies employed by SACB can contribute to the more effective representation of point cloud feature. On this basis, Selective Feature Fusion Block (SFFB), which is formed by stacking point- and channel-wise gating layers in a predefined sequence, is proposed to selectively boost salient local features in certain key regions, as well as to align the features before fusion phase. SACBs and SFFBs are combined to construct a robust and accurate architecture for point cloud-based place recognition, which is termed SelFLoc. Comparative experimental results show that SelFLoc achieves the state-of-the-art (SOTA) performance on the Oxford and other three in-house benchmarks with an improvement of 1.6 absolute percentages on mean average recall@1.
PriorLane: A Prior Knowledge Enhanced Lane Detection Approach Based on Transformer
Sep 15, 2022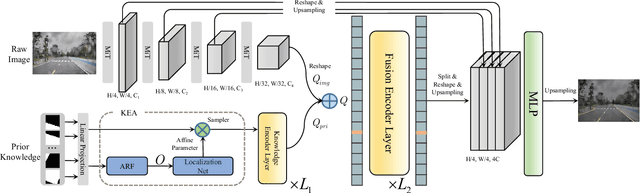
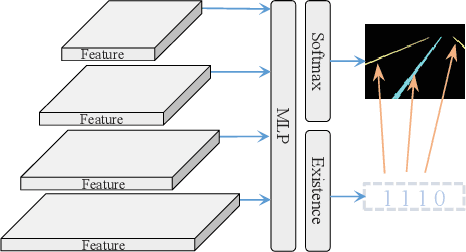

Lane detection is one of the fundamental modules in self-driving. In this paper we employ a transformer-only method for lane detection, thus it could benefit from the blooming development of fully vision transformer and achieves the state-of-the-art (SOTA) performance on both CULane and TuSimple benchmarks, by fine-tuning the weight fully pre-trained on large datasets. More importantly, this paper proposes a novel and general framework called PriorLane, which is used to enhance the segmentation performance of the fully vision transformer by introducing the low-cost local prior knowledge. PriorLane utilizes an encoder-only transformer to fuse the feature extracted by a pre-trained segmentation model with prior knowledge embeddings. Note that a Knowledge Embedding Alignment (KEA) module is adapted to enhance the fusion performance by aligning the knowledge embedding. Extensive experiments on our Zjlab dataset show that Prior-Lane outperforms SOTA lane detection methods by a 2.82% mIoU, and the code will be released at: https://github. com/vincentqqb/PriorLane.
CVR-LSE: Compact Vectorization Representation of Local Static Environments for Unmanned Ground Vehicles
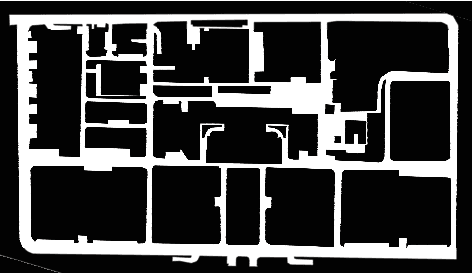
Jun 14, 2022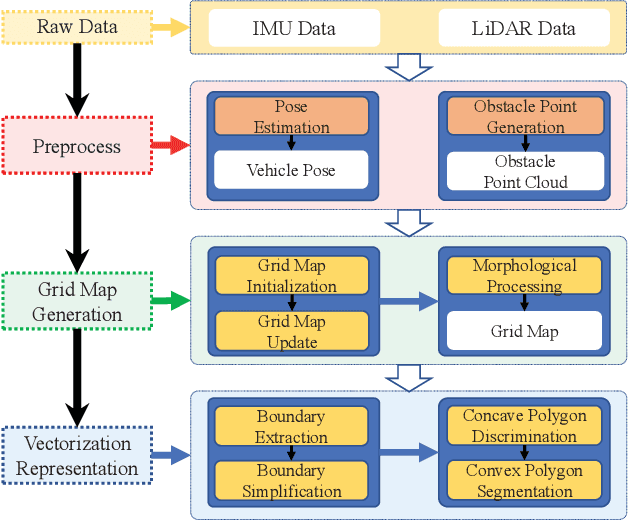
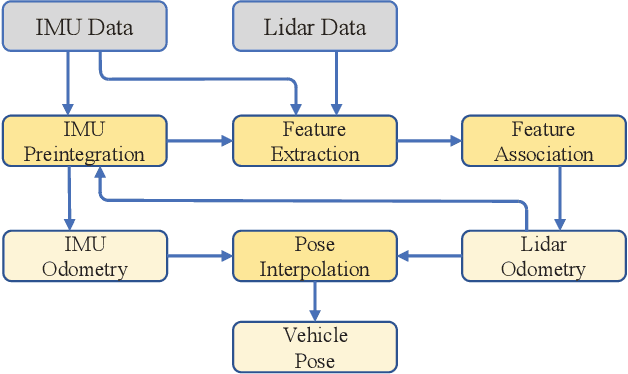
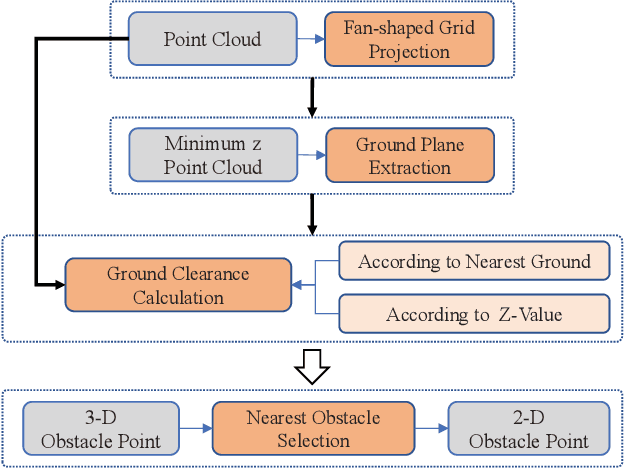
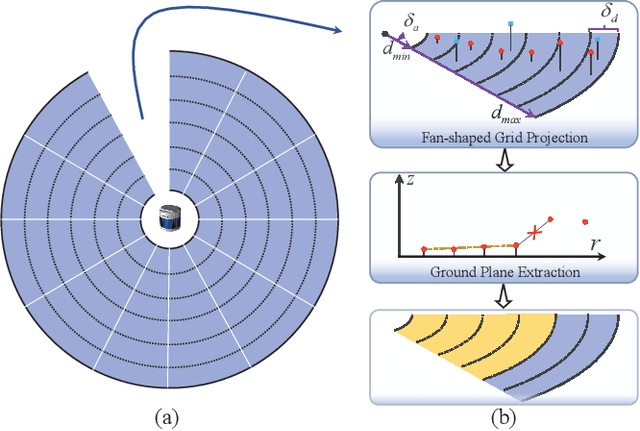
According to the requirement of general static obstacle detection, this paper proposes a compact vectorization representation approach of local static environments for unmanned ground vehicles. At first, by fusing the data of LiDAR and IMU, high-frequency pose information is obtained. Then, through the two-dimensional (2D) obstacle points generation, the process of grid map maintenance with a fixed size is proposed. Finally, the local static environment is described via multiple convex polygons, which is realized throungh the double threshold-based boundary simplification and the convex polygon segmentation. Our proposed approach has been applied in a practical driverless project in the park, and the qualitative experimental results on typical scenes verify the effectiveness and robustness. In addition, the quantitative evaluation shows the superior performance on making use of fewer number of points information (decreased by about 60%) to represent the local static environment compared with the traditional grid map-based methods. Furthermore, the performance of running time (15ms) shows that the proposed approach can be used for real-time local static environment perception. The corresponding code can be accessed at https://github.com/ghm0819/cvr_lse.
EffMoP: Efficient Motion Planning Based on Heuristic-Guided Motion Primitives Pruning and Path Optimization With Sparse-Banded Structure
Dec 16, 2020



To solve the autonomous navigation problem in complex environments, an efficient motion planning approach called EffMoP is presented in this paper. Considering the challenges from large-scale, partially unknown complex environments, a three-layer motion planning framework is elaborately designed, including global path planning, local path optimization, and time-optimal velocity planning. Compared with existing approaches, the novelty of this work is twofold: 1) a heuristic-guided pruning strategy of motion primitives is newly designed and fully integrated into the search-based global path planner to improve the computational efficiency of graph search, and 2) a novel soft-constrained local path optimization approach is proposed, wherein the sparse-banded system structure of the underlying optimization problem is fully exploited to efficiently solve the problem. We validate the safety, smoothness, flexibility, and efficiency of EffMoP in various complex simulation scenarios and challenging real-world tasks. It is shown that the computational efficiency is improved by 66.21% in the global planning stage and the motion efficiency of the robot is improved by 22.87% compared with the recent quintic B\'{e}zier curve-based state space sampling approach.
CAE-RLSM: Consistent and Efficient Redundant Line Segment Merging for Online Feature Map Building
Jan 07, 2019

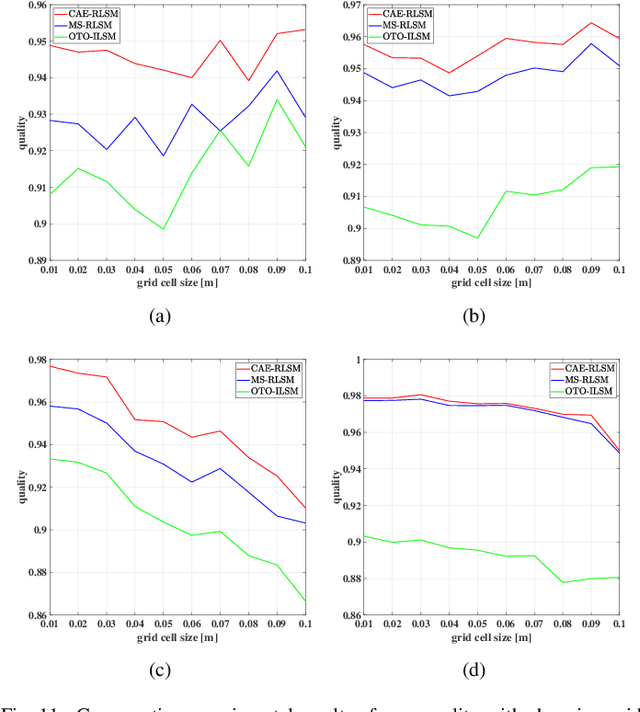

In order to obtain a compact line segment-based map representation for localization and planning of mobile robots, it is necessary to merge redundant line segments which physically represent the same part of the environment in different scans. In this paper, a consistent and efficient redundant line segment merging approach (CAE-RLSM) is proposed for online feature map building. The proposed CAE-RLSM is composed of two newly proposed modules: one-to-many incremental line segment merging (OTM-ILSM) and multi-processing global map adjustment (MP-GMA). Different from state-of-the-art offline merging approaches, the proposed CAE-RLSM can achieve real-time mapping performance, which not only reduces the redundancy of incremental merging with high efficiency, but also solves the problem of global map adjustment after loop closing to guarantee global consistency. Furthermore, a new correlation-based evaluation metric is proposed for the quality evaluation of line segment maps. This evaluation metric does not require manual measurement of the environmental metric information, instead it makes full use of globally consistent laser scans obtained by simultaneous localization and mapping (SLAM) systems to compare the performance of different line segment-based mapping approaches in an objective and fair manner. Comparative experimental results with respect to a mean shift-based offline redundant line segment merging approach (MS-RLSM) and an offline version of one-to-one incremental line segment merging approach (OTO-ILSM) on both public data sets and self-recorded data set are presented to show the superior performance of CAE-RLSM in terms of efficiency and map quality in different scenarios.