 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePriorLane: A Prior Knowledge Enhanced Lane Detection Approach Based on Transformer
Paper and Code
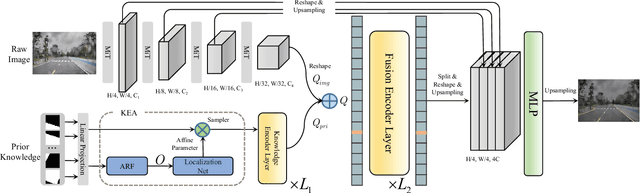
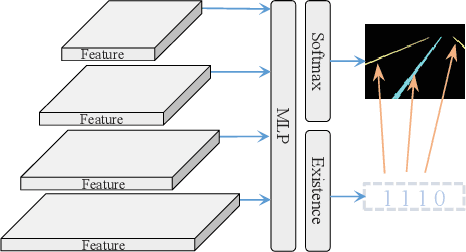

Lane detection is one of the fundamental modules in self-driving. In this paper we employ a transformer-only method for lane detection, thus it could benefit from the blooming development of fully vision transformer and achieves the state-of-the-art (SOTA) performance on both CULane and TuSimple benchmarks, by fine-tuning the weight fully pre-trained on large datasets. More importantly, this paper proposes a novel and general framework called PriorLane, which is used to enhance the segmentation performance of the fully vision transformer by introducing the low-cost local prior knowledge. PriorLane utilizes an encoder-only transformer to fuse the feature extracted by a pre-trained segmentation model with prior knowledge embeddings. Note that a Knowledge Embedding Alignment (KEA) module is adapted to enhance the fusion performance by aligning the knowledge embedding. Extensive experiments on our Zjlab dataset show that Prior-Lane outperforms SOTA lane detection methods by a 2.82% mIoU, and the code will be released at: https://github. com/vincentqqb/PriorLane.