 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSVIT: Improving Spiking Vision Transformer Using Multi-scale Attention Fusion
May 19, 2025The combination of Spiking Neural Networks(SNNs) with Vision Transformer architectures has attracted significant attention due to the great potential for energy-efficient and high-performance computing paradigms. However, a substantial performance gap still exists between SNN-based and ANN-based transformer architectures. While existing methods propose spiking self-attention mechanisms that are successfully combined with SNNs, the overall architectures proposed by these methods suffer from a bottleneck in effectively extracting features from different image scales. In this paper, we address this issue and propose MSVIT, a novel spike-driven Transformer architecture, which firstly uses multi-scale spiking attention (MSSA) to enrich the capability of spiking attention blocks. We validate our approach across various main data sets. The experimental results show that MSVIT outperforms existing SNN-based models, positioning itself as a state-of-the-art solution among SNN-transformer architectures. The codes are available at https://github.com/Nanhu-AI-Lab/MSViT.
Generative Compositor for Few-Shot Visual Information Extraction
Mar 21, 2025Visual Information Extraction (VIE), aiming at extracting structured information from visually rich document images, plays a pivotal role in document processing. Considering various layouts, semantic scopes, and languages, VIE encompasses an extensive range of types, potentially numbering in the thousands. However, many of these types suffer from a lack of training data, which poses significant challenges. In this paper, we propose a novel generative model, named Generative Compositor, to address the challenge of few-shot VIE. The Generative Compositor is a hybrid pointer-generator network that emulates the operations of a compositor by retrieving words from the source text and assembling them based on the provided prompts. Furthermore, three pre-training strategies are employed to enhance the model's perception of spatial context information. Besides, a prompt-aware resampler is specially designed to enable efficient matching by leveraging the entity-semantic prior contained in prompts. The introduction of the prompt-based retrieval mechanism and the pre-training strategies enable the model to acquire more effective spatial and semantic clues with limited training samples. Experiments demonstrate that the proposed method achieves highly competitive results in the full-sample training, while notably outperforms the baseline in the 1-shot, 5-shot, and 10-shot settings.
SOOD++: Leveraging Unlabeled Data to Boost Oriented Object Detection
Jul 01, 2024Semi-supervised object detection (SSOD), leveraging unlabeled data to boost object detectors, has become a hot topic recently. However, existing SSOD approaches mainly focus on horizontal objects, leaving multi-oriented objects common in aerial images unexplored. At the same time, the annotation cost of multi-oriented objects is significantly higher than that of their horizontal counterparts. Therefore, in this paper, we propose a simple yet effective Semi-supervised Oriented Object Detection method termed SOOD++. Specifically, we observe that objects from aerial images are usually arbitrary orientations, small scales, and aggregation, which inspires the following core designs: a Simple Instance-aware Dense Sampling (SIDS) strategy is used to generate comprehensive dense pseudo-labels; the Geometry-aware Adaptive Weighting (GAW) loss dynamically modulates the importance of each pair between pseudo-label and corresponding prediction by leveraging the intricate geometric information of aerial objects; we treat aerial images as global layouts and explicitly build the many-to-many relationship between the sets of pseudo-labels and predictions via the proposed Noise-driven Global Consistency (NGC). Extensive experiments conducted on various multi-oriented object datasets under various labeled settings demonstrate the effectiveness of our method. For example, on the DOTA-V1.5 benchmark, the proposed method outperforms previous state-of-the-art (SOTA) by a large margin (+2.92, +2.39, and +2.57 mAP under 10%, 20%, and 30% labeled data settings, respectively) with single-scale training and testing. More importantly, it still improves upon a strong supervised baseline with 70.66 mAP, trained using the full DOTA-V1.5 train-val set, by +1.82 mAP, resulting in a 72.48 mAP, pushing the new state-of-the-art. The code will be made available.
Roadside Monocular 3D Detection via 2D Detection Prompting
Apr 04, 2024



The problem of roadside monocular 3D detection requires detecting objects of interested classes in a 2D RGB frame and predicting their 3D information such as locations in bird's-eye-view (BEV). It has broad applications in traffic control, vehicle-vehicle communication, and vehicle-infrastructure cooperative perception. To approach this problem, we present a novel and simple method by prompting the 3D detector using 2D detections. Our method builds on a key insight that, compared with 3D detectors, a 2D detector is much easier to train and performs significantly better w.r.t detections on the 2D image plane. That said, one can exploit 2D detections of a well-trained 2D detector as prompts to a 3D detector, being trained in a way of inflating such 2D detections to 3D towards 3D detection. To construct better prompts using the 2D detector, we explore three techniques: (a) concatenating both 2D and 3D detectors' features, (b) attentively fusing 2D and 3D detectors' features, and (c) encoding predicted 2D boxes x, y, width, height, label and attentively fusing such with the 3D detector's features. Surprisingly, the third performs the best. Moreover, we present a yaw tuning tactic and a class-grouping strategy that merges classes based on their functionality; these techniques improve 3D detection performance further. Comprehensive ablation studies and extensive experiments demonstrate that our method resoundingly outperforms prior works, achieving the state-of-the-art on two large-scale roadside 3D detection benchmarks.
3D-SceneDreamer: Text-Driven 3D-Consistent Scene Generation
Mar 14, 2024Text-driven 3D scene generation techniques have made rapid progress in recent years. Their success is mainly attributed to using existing generative models to iteratively perform image warping and inpainting to generate 3D scenes. However, these methods heavily rely on the outputs of existing models, leading to error accumulation in geometry and appearance that prevent the models from being used in various scenarios (e.g., outdoor and unreal scenarios). To address this limitation, we generatively refine the newly generated local views by querying and aggregating global 3D information, and then progressively generate the 3D scene. Specifically, we employ a tri-plane features-based NeRF as a unified representation of the 3D scene to constrain global 3D consistency, and propose a generative refinement network to synthesize new contents with higher quality by exploiting the natural image prior from 2D diffusion model as well as the global 3D information of the current scene. Our extensive experiments demonstrate that, in comparison to previous methods, our approach supports wide variety of scene generation and arbitrary camera trajectories with improved visual quality and 3D consistency.
Long-Tailed 3D Detection via 2D Late Fusion
Dec 18, 2023Autonomous vehicles (AVs) must accurately detect objects from both common and rare classes for safe navigation, motivating the problem of Long-Tailed 3D Object Detection (LT3D). Contemporary LiDAR-based 3D detectors perform poorly on rare classes (e.g., CenterPoint only achieves 5.1 AP on stroller) as it is difficult to recognize objects from sparse LiDAR points alone. RGB images provide visual evidence to help resolve such ambiguities, motivating the study of RGB-LiDAR fusion. In this paper, we delve into a simple late-fusion framework that ensembles independently trained RGB and LiDAR detectors. Unlike recent end-to-end methods which require paired multi-modal training data, our late-fusion approach can easily leverage large-scale uni-modal datasets, significantly improving rare class detection.In particular, we examine three critical components in this late-fusion framework from first principles, including whether to train 2D or 3D RGB detectors, whether to match RGB and LiDAR detections in 3D or the projected 2D image plane, and how to fuse matched detections.Extensive experiments reveal that 2D RGB detectors achieve better recognition accuracy than 3D RGB detectors, matching on the 2D image plane mitigates depth estimation errors, and fusing scores probabilistically with calibration leads to state-of-the-art LT3D performance. Our late-fusion approach achieves 51.4 mAP on the established nuScenes LT3D benchmark, improving over prior work by 5.9 mAP.
Beyond Isolation: Multi-Agent Synergy for Improving Knowledge Graph Construction
Dec 05, 2023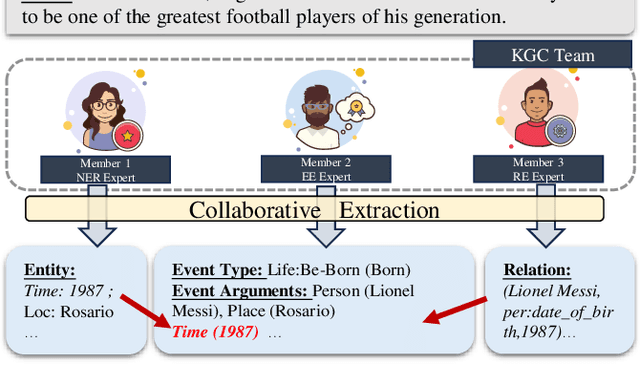


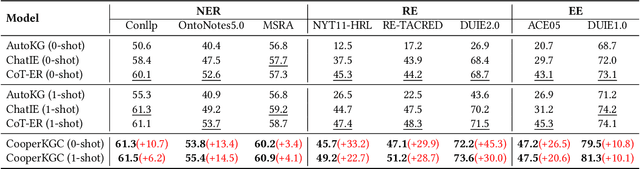
Knowledge graph construction (KGC) is a multifaceted undertaking involving the extraction of entities, relations, and events. Traditionally, large language models (LLMs) have been viewed as solitary task-solving agents in this complex landscape. However, this paper challenges this paradigm by introducing a novel framework, CooperKGC. Departing from the conventional approach, CooperKGC establishes a collaborative processing network, assembling a KGC collaboration team capable of concurrently addressing entity, relation, and event extraction tasks. Our experiments unequivocally demonstrate that fostering collaboration and information interaction among diverse agents within CooperKGC yields superior results compared to individual cognitive processes operating in isolation. Importantly, our findings reveal that the collaboration facilitated by CooperKGC enhances knowledge selection, correction, and aggregation capabilities across multiple rounds of interactions.
Holistic Inverse Rendering of Complex Facade via Aerial 3D Scanning
Nov 20, 2023



In this work, we use multi-view aerial images to reconstruct the geometry, lighting, and material of facades using neural signed distance fields (SDFs). Without the requirement of complex equipment, our method only takes simple RGB images captured by a drone as inputs to enable physically based and photorealistic novel-view rendering, relighting, and editing. However, a real-world facade usually has complex appearances ranging from diffuse rocks with subtle details to large-area glass windows with specular reflections, making it hard to attend to everything. As a result, previous methods can preserve the geometry details but fail to reconstruct smooth glass windows or verse vise. In order to address this challenge, we introduce three spatial- and semantic-adaptive optimization strategies, including a semantic regularization approach based on zero-shot segmentation techniques to improve material consistency, a frequency-aware geometry regularization to balance surface smoothness and details in different surfaces, and a visibility probe-based scheme to enable efficient modeling of the local lighting in large-scale outdoor environments. In addition, we capture a real-world facade aerial 3D scanning image set and corresponding point clouds for training and benchmarking. The experiment demonstrates the superior quality of our method on facade holistic inverse rendering, novel view synthesis, and scene editing compared to state-of-the-art baselines.
M$^3$CS: Multi-Target Masked Point Modeling with Learnable Codebook and Siamese Decoders
Sep 23, 2023Masked point modeling has become a promising scheme of self-supervised pre-training for point clouds. Existing methods reconstruct either the original points or related features as the objective of pre-training. However, considering the diversity of downstream tasks, it is necessary for the model to have both low- and high-level representation modeling capabilities to capture geometric details and semantic contexts during pre-training. To this end, M$^3$CS is proposed to enable the model with the above abilities. Specifically, with masked point cloud as input, M$^3$CS introduces two decoders to predict masked representations and the original points simultaneously. While an extra decoder doubles parameters for the decoding process and may lead to overfitting, we propose siamese decoders to keep the amount of learnable parameters unchanged. Further, we propose an online codebook projecting continuous tokens into discrete ones before reconstructing masked points. In such way, we can enforce the decoder to take effect through the combinations of tokens rather than remembering each token. Comprehensive experiments show that M$^3$CS achieves superior performance at both classification and segmentation tasks, outperforming existing methods.
Cognitive Mirage: A Review of Hallucinations in Large Language Models
Sep 13, 2023



As large language models continue to develop in the field of AI, text generation systems are susceptible to a worrisome phenomenon known as hallucination. In this study, we summarize recent compelling insights into hallucinations in LLMs. We present a novel taxonomy of hallucinations from various text generation tasks, thus provide theoretical insights, detection methods and improvement approaches. Based on this, future research directions are proposed. Our contribution are threefold: (1) We provide a detailed and complete taxonomy for hallucinations appearing in text generation tasks; (2) We provide theoretical analyses of hallucinations in LLMs and provide existing detection and improvement methods; (3) We propose several research directions that can be developed in the future. As hallucinations garner significant attention from the community, we will maintain updates on relevant research progress.