 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaLogic: Robustness Evaluation of Text-to-Image Models via Logically Equivalent Prompts
Oct 01, 2025Recent advances in text-to-image (T2I) models, especially diffusion-based architectures, have significantly improved the visual quality of generated images. However, these models continue to struggle with a critical limitation: maintaining semantic consistency when input prompts undergo minor linguistic variations. Despite being logically equivalent, such prompt pairs often yield misaligned or semantically inconsistent images, exposing a lack of robustness in reasoning and generalisation. To address this, we propose MetaLogic, a novel evaluation framework that detects T2I misalignment without relying on ground truth images. MetaLogic leverages metamorphic testing, generating image pairs from prompts that differ grammatically but are semantically identical. By directly comparing these image pairs, the framework identifies inconsistencies that signal failures in preserving the intended meaning, effectively diagnosing robustness issues in the model's logic understanding. Unlike existing evaluation methods that compare a generated image to a single prompt, MetaLogic evaluates semantic equivalence between paired images, offering a scalable, ground-truth-free approach to identifying alignment failures. It categorises these alignment errors (e.g., entity omission, duplication, positional misalignment) and surfaces counterexamples that can be used for model debugging and refinement. We evaluate MetaLogic across multiple state-of-the-art T2I models and reveal consistent robustness failures across a range of logical constructs. We find that even the SOTA text-to-image models like Flux.dev and DALLE-3 demonstrate a 59 percent and 71 percent misalignment rate, respectively. Our results show that MetaLogic is not only efficient and scalable, but also effective in uncovering fine-grained logical inconsistencies that are overlooked by existing evaluation metrics.
MSVIT: Improving Spiking Vision Transformer Using Multi-scale Attention Fusion
May 19, 2025The combination of Spiking Neural Networks(SNNs) with Vision Transformer architectures has attracted significant attention due to the great potential for energy-efficient and high-performance computing paradigms. However, a substantial performance gap still exists between SNN-based and ANN-based transformer architectures. While existing methods propose spiking self-attention mechanisms that are successfully combined with SNNs, the overall architectures proposed by these methods suffer from a bottleneck in effectively extracting features from different image scales. In this paper, we address this issue and propose MSVIT, a novel spike-driven Transformer architecture, which firstly uses multi-scale spiking attention (MSSA) to enrich the capability of spiking attention blocks. We validate our approach across various main data sets. The experimental results show that MSVIT outperforms existing SNN-based models, positioning itself as a state-of-the-art solution among SNN-transformer architectures. The codes are available at https://github.com/Nanhu-AI-Lab/MSViT.
PP-SSL : Priority-Perception Self-Supervised Learning for Fine-Grained Recognition
Nov 28, 2024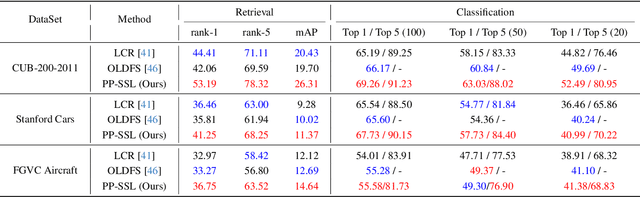
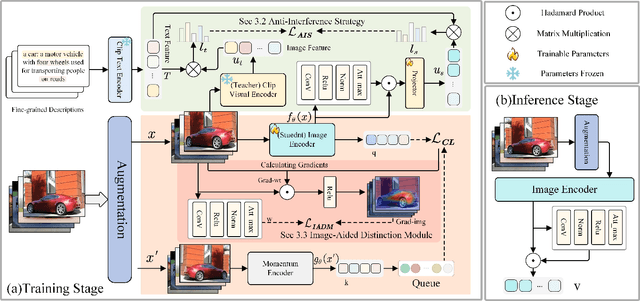
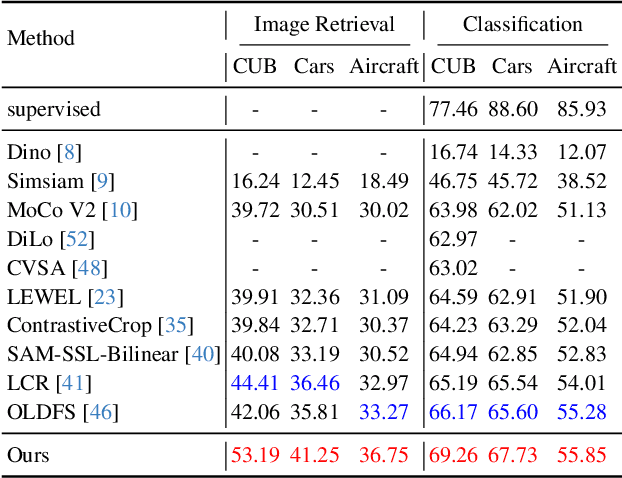

Self-supervised learning is emerging in fine-grained visual recognition with promising results. However, existing self-supervised learning methods are often susceptible to irrelevant patterns in self-supervised tasks and lack the capability to represent the subtle differences inherent in fine-grained visual recognition (FGVR), resulting in generally poorer performance. To address this, we propose a novel Priority-Perception Self-Supervised Learning framework, denoted as PP-SSL, which can effectively filter out irrelevant feature interference and extract more subtle discriminative features throughout the training process. Specifically, it composes of two main parts: the Anti-Interference Strategy (AIS) and the Image-Aided Distinction Module (IADM). In AIS, a fine-grained textual description corpus is established, and a knowledge distillation strategy is devised to guide the model in eliminating irrelevant features while enhancing the learning of more discriminative and high-quality features. IADM reveals that extracting GradCAM from the original image effectively reveals subtle differences between fine-grained categories. Compared to features extracted from intermediate or output layers, the original image retains more detail, allowing for a deeper exploration of the subtle distinctions among fine-grained classes. Extensive experimental results indicate that the PP-SSL significantly outperforms existing methods across various datasets, highlighting its effectiveness in fine-grained recognition tasks. Our code will be made publicly available upon publication.
CIT: Rethinking Class-incremental Semantic Segmentation with a Class Independent Transformation
Nov 05, 2024


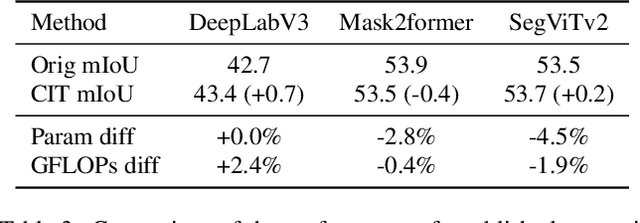
Class-incremental semantic segmentation (CSS) requires that a model learn to segment new classes without forgetting how to segment previous ones: this is typically achieved by distilling the current knowledge and incorporating the latest data. However, bypassing iterative distillation by directly transferring outputs of initial classes to the current learning task is not supported in existing class-specific CSS methods. Via Softmax, they enforce dependency between classes and adjust the output distribution at each learning step, resulting in a large probability distribution gap between initial and current tasks. We introduce a simple, yet effective Class Independent Transformation (CIT) that converts the outputs of existing semantic segmentation models into class-independent forms with negligible cost or performance loss. By utilizing class-independent predictions facilitated by CIT, we establish an accumulative distillation framework, ensuring equitable incorporation of all class information. We conduct extensive experiments on various segmentation architectures, including DeepLabV3, Mask2Former, and SegViTv2. Results from these experiments show minimal task forgetting across different datasets, with less than 5% for ADE20K in the most challenging 11 task configurations and less than 1% across all configurations for the PASCAL VOC 2012 dataset.
MuseBarControl: Enhancing Fine-Grained Control in Symbolic Music Generation through Pre-Training and Counterfactual Loss
Jul 05, 2024

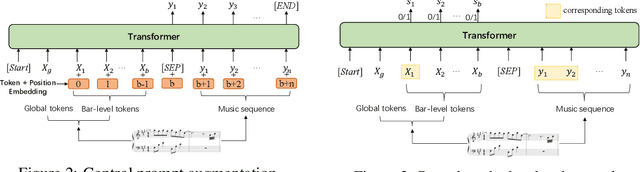
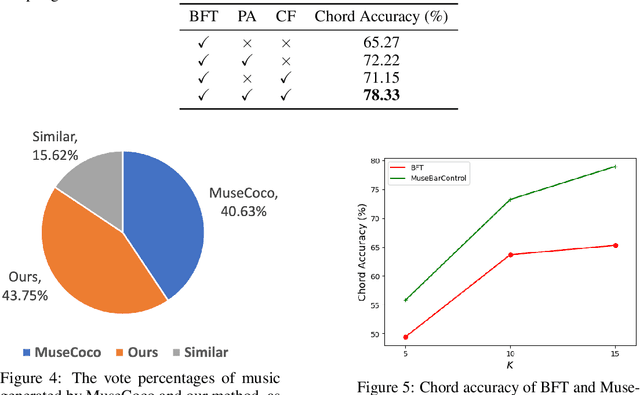
Automatically generating symbolic music-music scores tailored to specific human needs-can be highly beneficial for musicians and enthusiasts. Recent studies have shown promising results using extensive datasets and advanced transformer architectures. However, these state-of-the-art models generally offer only basic control over aspects like tempo and style for the entire composition, lacking the ability to manage finer details, such as control at the level of individual bars. While fine-tuning a pre-trained symbolic music generation model might seem like a straightforward method for achieving this finer control, our research indicates challenges in this approach. The model often fails to respond adequately to new, fine-grained bar-level control signals. To address this, we propose two innovative solutions. First, we introduce a pre-training task designed to link control signals directly with corresponding musical tokens, which helps in achieving a more effective initialization for subsequent fine-tuning. Second, we implement a novel counterfactual loss that promotes better alignment between the generated music and the control prompts. Together, these techniques significantly enhance our ability to control music generation at the bar level, showing a 13.06\% improvement over conventional methods. Our subjective evaluations also confirm that this enhanced control does not compromise the musical quality of the original pre-trained generative model.
Source-Free Unsupervised Domain Adaptation with Hypothesis Consolidation of Prediction Rationale
Feb 02, 2024Source-Free Unsupervised Domain Adaptation (SFUDA) is a challenging task where a model needs to be adapted to a new domain without access to target domain labels or source domain data. The primary difficulty in this task is that the model's predictions may be inaccurate, and using these inaccurate predictions for model adaptation can lead to misleading results. To address this issue, this paper proposes a novel approach that considers multiple prediction hypotheses for each sample and investigates the rationale behind each hypothesis. By consolidating these hypothesis rationales, we identify the most likely correct hypotheses, which we then use as a pseudo-labeled set to support a semi-supervised learning procedure for model adaptation. To achieve the optimal performance, we propose a three-step adaptation process: model pre-adaptation, hypothesis consolidation, and semi-supervised learning. Extensive experimental results demonstrate that our approach achieves state-of-the-art performance in the SFUDA task and can be easily integrated into existing approaches to improve their performance. The codes are available at \url{https://github.com/GANPerf/HCPR}.
Learning Common Rationale to Improve Self-Supervised Representation for Fine-Grained Visual Recognition Problems
Mar 03, 2023



Self-supervised learning (SSL) strategies have demonstrated remarkable performance in various recognition tasks. However, both our preliminary investigation and recent studies suggest that they may be less effective in learning representations for fine-grained visual recognition (FGVR) since many features helpful for optimizing SSL objectives are not suitable for characterizing the subtle differences in FGVR. To overcome this issue, we propose learning an additional screening mechanism to identify discriminative clues commonly seen across instances and classes, dubbed as common rationales in this paper. Intuitively, common rationales tend to correspond to the discriminative patterns from the key parts of foreground objects. We show that a common rationale detector can be learned by simply exploiting the GradCAM induced from the SSL objective without using any pre-trained object parts or saliency detectors, making it seamlessly to be integrated with the existing SSL process. Specifically, we fit the GradCAM with a branch with limited fitting capacity, which allows the branch to capture the common rationales and discard the less common discriminative patterns. At the test stage, the branch generates a set of spatial weights to selectively aggregate features representing an instance. Extensive experimental results on four visual tasks demonstrate that the proposed method can lead to a significant improvement in different evaluation settings.
Improving Fine-Grained Visual Recognition in Low Data Regimes via Self-Boosting Attention Mechanism
Aug 01, 2022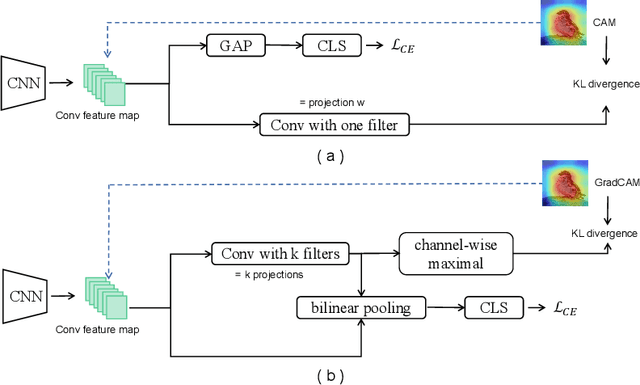
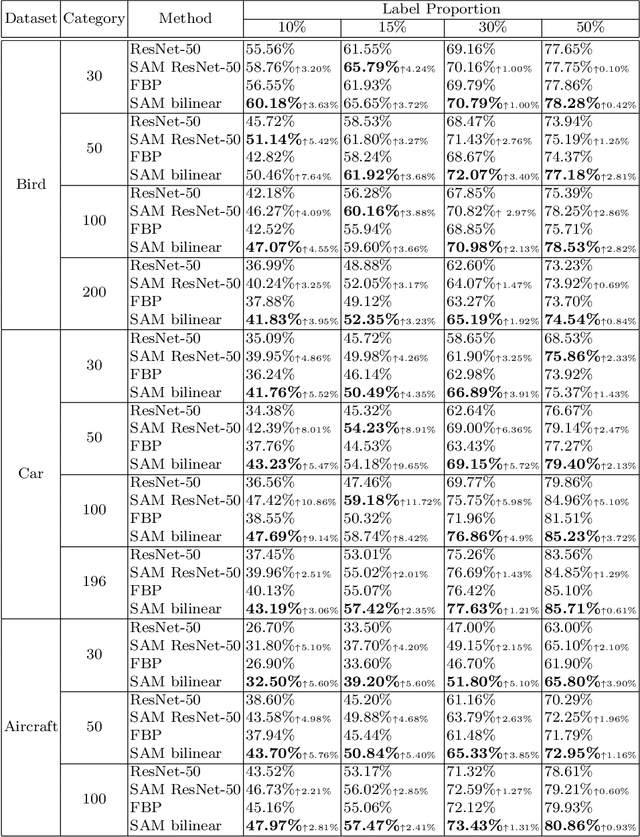
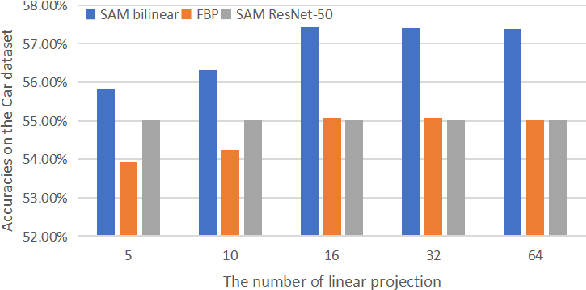
The challenge of fine-grained visual recognition often lies in discovering the key discriminative regions. While such regions can be automatically identified from a large-scale labeled dataset, a similar method might become less effective when only a few annotations are available. In low data regimes, a network often struggles to choose the correct regions for recognition and tends to overfit spurious correlated patterns from the training data. To tackle this issue, this paper proposes the self-boosting attention mechanism, a novel method for regularizing the network to focus on the key regions shared across samples and classes. Specifically, the proposed method first generates an attention map for each training image, highlighting the discriminative part for identifying the ground-truth object category. Then the generated attention maps are used as pseudo-annotations. The network is enforced to fit them as an auxiliary task. We call this approach the self-boosting attention mechanism (SAM). We also develop a variant by using SAM to create multiple attention maps to pool convolutional maps in a style of bilinear pooling, dubbed SAM-Bilinear. Through extensive experimental studies, we show that both methods can significantly improve fine-grained visual recognition performance on low data regimes and can be incorporated into existing network architectures. The source code is publicly available at: https://github.com/GANPerf/SAM