 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuseBarControl: Enhancing Fine-Grained Control in Symbolic Music Generation through Pre-Training and Counterfactual Loss
Paper and Code


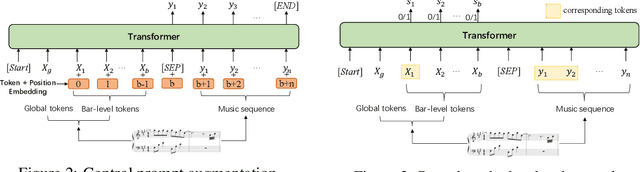
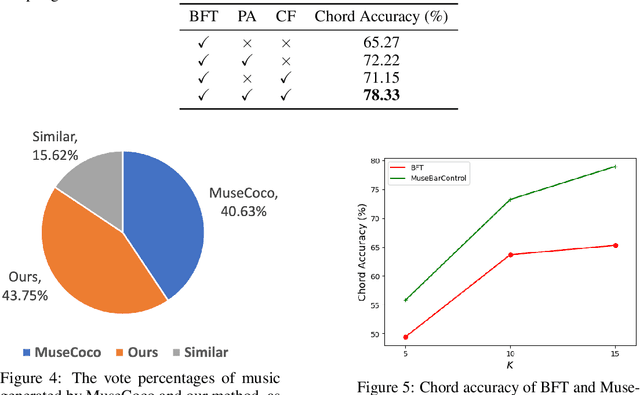
Automatically generating symbolic music-music scores tailored to specific human needs-can be highly beneficial for musicians and enthusiasts. Recent studies have shown promising results using extensive datasets and advanced transformer architectures. However, these state-of-the-art models generally offer only basic control over aspects like tempo and style for the entire composition, lacking the ability to manage finer details, such as control at the level of individual bars. While fine-tuning a pre-trained symbolic music generation model might seem like a straightforward method for achieving this finer control, our research indicates challenges in this approach. The model often fails to respond adequately to new, fine-grained bar-level control signals. To address this, we propose two innovative solutions. First, we introduce a pre-training task designed to link control signals directly with corresponding musical tokens, which helps in achieving a more effective initialization for subsequent fine-tuning. Second, we implement a novel counterfactual loss that promotes better alignment between the generated music and the control prompts. Together, these techniques significantly enhance our ability to control music generation at the bar level, showing a 13.06\% improvement over conventional methods. Our subjective evaluations also confirm that this enhanced control does not compromise the musical quality of the original pre-trained generative model.