 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCIT: Rethinking Class-incremental Semantic Segmentation with a Class Independent Transformation
Paper and Code
Nov 05, 2024


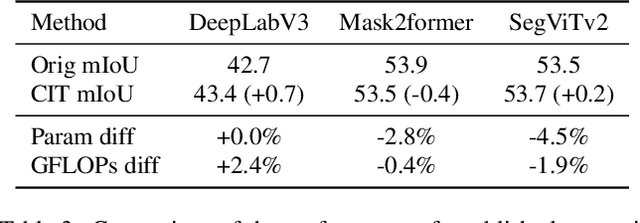
Class-incremental semantic segmentation (CSS) requires that a model learn to segment new classes without forgetting how to segment previous ones: this is typically achieved by distilling the current knowledge and incorporating the latest data. However, bypassing iterative distillation by directly transferring outputs of initial classes to the current learning task is not supported in existing class-specific CSS methods. Via Softmax, they enforce dependency between classes and adjust the output distribution at each learning step, resulting in a large probability distribution gap between initial and current tasks. We introduce a simple, yet effective Class Independent Transformation (CIT) that converts the outputs of existing semantic segmentation models into class-independent forms with negligible cost or performance loss. By utilizing class-independent predictions facilitated by CIT, we establish an accumulative distillation framework, ensuring equitable incorporation of all class information. We conduct extensive experiments on various segmentation architectures, including DeepLabV3, Mask2Former, and SegViTv2. Results from these experiments show minimal task forgetting across different datasets, with less than 5% for ADE20K in the most challenging 11 task configurations and less than 1% across all configurations for the PASCAL VOC 2012 dataset.