 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for 3D Scene Understanding
Jul 03, 2024
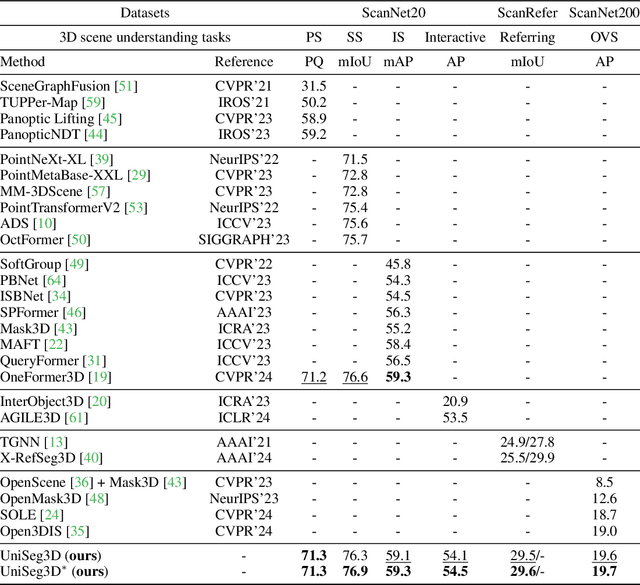


We propose UniSeg3D, a unified 3D segmentation framework that achieves panoptic, semantic, instance, interactive, referring, and open-vocabulary semantic segmentation tasks within a single model. Most previous 3D segmentation approaches are specialized for a specific task, thereby limiting their understanding of 3D scenes to a task-specific perspective. In contrast, the proposed method unifies six tasks into unified representations processed by the same Transformer. It facilitates inter-task knowledge sharing and, therefore, promotes comprehensive 3D scene understanding. To take advantage of multi-task unification, we enhance the performance by leveraging task connections. Specifically, we design a knowledge distillation method and a contrastive learning method to transfer task-specific knowledge across different tasks. Benefiting from extensive inter-task knowledge sharing, our UniSeg3D becomes more powerful. Experiments on three benchmarks, including the ScanNet20, ScanRefer, and ScanNet200, demonstrate that the UniSeg3D consistently outperforms current SOTA methods, even those specialized for individual tasks. We hope UniSeg3D can serve as a solid unified baseline and inspire future work. The code will be available at https://dk-liang.github.io/UniSeg3D/.
SOOD++: Leveraging Unlabeled Data to Boost Oriented Object Detection
Jul 01, 2024Semi-supervised object detection (SSOD), leveraging unlabeled data to boost object detectors, has become a hot topic recently. However, existing SSOD approaches mainly focus on horizontal objects, leaving multi-oriented objects common in aerial images unexplored. At the same time, the annotation cost of multi-oriented objects is significantly higher than that of their horizontal counterparts. Therefore, in this paper, we propose a simple yet effective Semi-supervised Oriented Object Detection method termed SOOD++. Specifically, we observe that objects from aerial images are usually arbitrary orientations, small scales, and aggregation, which inspires the following core designs: a Simple Instance-aware Dense Sampling (SIDS) strategy is used to generate comprehensive dense pseudo-labels; the Geometry-aware Adaptive Weighting (GAW) loss dynamically modulates the importance of each pair between pseudo-label and corresponding prediction by leveraging the intricate geometric information of aerial objects; we treat aerial images as global layouts and explicitly build the many-to-many relationship between the sets of pseudo-labels and predictions via the proposed Noise-driven Global Consistency (NGC). Extensive experiments conducted on various multi-oriented object datasets under various labeled settings demonstrate the effectiveness of our method. For example, on the DOTA-V1.5 benchmark, the proposed method outperforms previous state-of-the-art (SOTA) by a large margin (+2.92, +2.39, and +2.57 mAP under 10%, 20%, and 30% labeled data settings, respectively) with single-scale training and testing. More importantly, it still improves upon a strong supervised baseline with 70.66 mAP, trained using the full DOTA-V1.5 train-val set, by +1.82 mAP, resulting in a 72.48 mAP, pushing the new state-of-the-art. The code will be made available.