 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing the Future, Perceiving the Future: A Unified Driving World Model for Future Generation and Perception
Mar 17, 2025



We present UniFuture, a simple yet effective driving world model that seamlessly integrates future scene generation and perception within a single framework. Unlike existing models focusing solely on pixel-level future prediction or geometric reasoning, our approach jointly models future appearance (i.e., RGB image) and geometry (i.e., depth), ensuring coherent predictions. Specifically, during the training, we first introduce a Dual-Latent Sharing scheme, which transfers image and depth sequence in a shared latent space, allowing both modalities to benefit from shared feature learning. Additionally, we propose a Multi-scale Latent Interaction mechanism, which facilitates bidirectional refinement between image and depth features at multiple spatial scales, effectively enhancing geometry consistency and perceptual alignment. During testing, our UniFuture can easily predict high-consistency future image-depth pairs by only using the current image as input. Extensive experiments on the nuScenes dataset demonstrate that UniFuture outperforms specialized models on future generation and perception tasks, highlighting the advantages of a unified, structurally-aware world model. The project page is at https://github.com/dk-liang/UniFuture.
HERMES: A Unified Self-Driving World Model for Simultaneous 3D Scene Understanding and Generation
Jan 24, 2025



Driving World Models (DWMs) have become essential for autonomous driving by enabling future scene prediction. However, existing DWMs are limited to scene generation and fail to incorporate scene understanding, which involves interpreting and reasoning about the driving environment. In this paper, we present a unified Driving World Model named HERMES. We seamlessly integrate 3D scene understanding and future scene evolution (generation) through a unified framework in driving scenarios. Specifically, HERMES leverages a Bird's-Eye View (BEV) representation to consolidate multi-view spatial information while preserving geometric relationships and interactions. We also introduce world queries, which incorporate world knowledge into BEV features via causal attention in the Large Language Model (LLM), enabling contextual enrichment for understanding and generation tasks. We conduct comprehensive studies on nuScenes and OmniDrive-nuScenes datasets to validate the effectiveness of our method. HERMES achieves state-of-the-art performance, reducing generation error by 32.4% and improving understanding metrics such as CIDEr by 8.0%. The model and code will be publicly released at https://github.com/LMD0311/HERMES.
A Unified Framework for 3D Scene Understanding
Jul 03, 2024
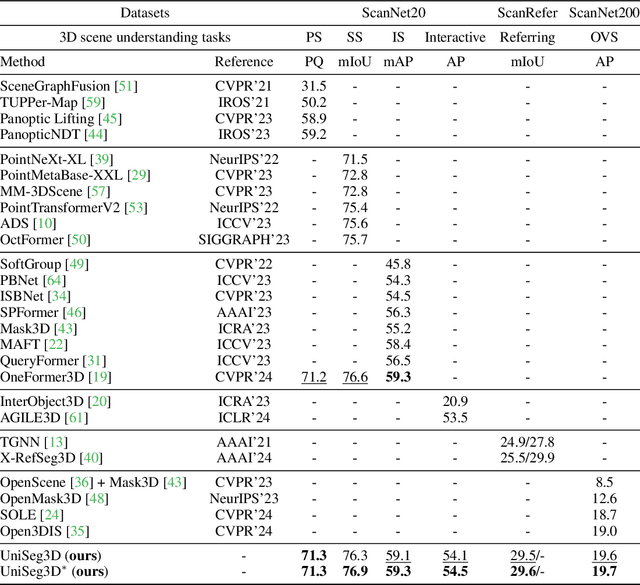


We propose UniSeg3D, a unified 3D segmentation framework that achieves panoptic, semantic, instance, interactive, referring, and open-vocabulary semantic segmentation tasks within a single model. Most previous 3D segmentation approaches are specialized for a specific task, thereby limiting their understanding of 3D scenes to a task-specific perspective. In contrast, the proposed method unifies six tasks into unified representations processed by the same Transformer. It facilitates inter-task knowledge sharing and, therefore, promotes comprehensive 3D scene understanding. To take advantage of multi-task unification, we enhance the performance by leveraging task connections. Specifically, we design a knowledge distillation method and a contrastive learning method to transfer task-specific knowledge across different tasks. Benefiting from extensive inter-task knowledge sharing, our UniSeg3D becomes more powerful. Experiments on three benchmarks, including the ScanNet20, ScanRefer, and ScanNet200, demonstrate that the UniSeg3D consistently outperforms current SOTA methods, even those specialized for individual tasks. We hope UniSeg3D can serve as a solid unified baseline and inspire future work. The code will be available at https://dk-liang.github.io/UniSeg3D/.