 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState Rank Dynamics in Linear Attention LLMs
Feb 02, 2026Linear Attention Large Language Models (LLMs) offer a compelling recurrent formulation that compresses context into a fixed-size state matrix, enabling constant-time inference. However, the internal dynamics of this compressed state remain largely opaque. In this work, we present a comprehensive study on the runtime state dynamics of state-of-the-art Linear Attention models. We uncover a fundamental phenomenon termed State Rank Stratification, characterized by a distinct spectral bifurcation among linear attention heads: while one group maintains an effective rank oscillating near zero, the other exhibits rapid growth that converges to an upper bound. Extensive experiments across diverse inference contexts reveal that these dynamics remain strikingly consistent, indicating that the identity of a head,whether low-rank or high-rank,is an intrinsic structural property acquired during pre-training, rather than a transient state dependent on the input data. Furthermore, our diagnostic probes reveal a surprising functional divergence: low-rank heads are indispensable for model reasoning, whereas high-rank heads exhibit significant redundancy. Leveraging this insight, we propose Joint Rank-Norm Pruning, a zero-shot strategy that achieves a 38.9\% reduction in KV-cache overhead while largely maintaining model accuracy.
Advances and Innovations in the Multi-Agent Robotic System (MARS) Challenge
Jan 26, 2026Recent advancements in multimodal large language models and vision-languageaction models have significantly driven progress in Embodied AI. As the field transitions toward more complex task scenarios, multi-agent system frameworks are becoming essential for achieving scalable, efficient, and collaborative solutions. This shift is fueled by three primary factors: increasing agent capabilities, enhancing system efficiency through task delegation, and enabling advanced human-agent interactions. To address the challenges posed by multi-agent collaboration, we propose the Multi-Agent Robotic System (MARS) Challenge, held at the NeurIPS 2025 Workshop on SpaVLE. The competition focuses on two critical areas: planning and control, where participants explore multi-agent embodied planning using vision-language models (VLMs) to coordinate tasks and policy execution to perform robotic manipulation in dynamic environments. By evaluating solutions submitted by participants, the challenge provides valuable insights into the design and coordination of embodied multi-agent systems, contributing to the future development of advanced collaborative AI systems.
Toward Efficient Agents: Memory, Tool learning, and Planning
Jan 20, 2026Recent years have witnessed increasing interest in extending large language models into agentic systems. While the effectiveness of agents has continued to improve, efficiency, which is crucial for real-world deployment, has often been overlooked. This paper therefore investigates efficiency from three core components of agents: memory, tool learning, and planning, considering costs such as latency, tokens, steps, etc. Aimed at conducting comprehensive research addressing the efficiency of the agentic system itself, we review a broad range of recent approaches that differ in implementation yet frequently converge on shared high-level principles including but not limited to bounding context via compression and management, designing reinforcement learning rewards to minimize tool invocation, and employing controlled search mechanisms to enhance efficiency, which we discuss in detail. Accordingly, we characterize efficiency in two complementary ways: comparing effectiveness under a fixed cost budget, and comparing cost at a comparable level of effectiveness. This trade-off can also be viewed through the Pareto frontier between effectiveness and cost. From this perspective, we also examine efficiency oriented benchmarks by summarizing evaluation protocols for these components and consolidating commonly reported efficiency metrics from both benchmark and methodological studies. Moreover, we discuss the key challenges and future directions, with the goal of providing promising insights.
VIKI-R: Coordinating Embodied Multi-Agent Cooperation via Reinforcement Learning
Jun 10, 2025Coordinating multiple embodied agents in dynamic environments remains a core challenge in artificial intelligence, requiring both perception-driven reasoning and scalable cooperation strategies. While recent works have leveraged large language models (LLMs) for multi-agent planning, a few have begun to explore vision-language models (VLMs) for visual reasoning. However, these VLM-based approaches remain limited in their support for diverse embodiment types. In this work, we introduce VIKI-Bench, the first hierarchical benchmark tailored for embodied multi-agent cooperation, featuring three structured levels: agent activation, task planning, and trajectory perception. VIKI-Bench includes diverse robot embodiments, multi-view visual observations, and structured supervision signals to evaluate reasoning grounded in visual inputs. To demonstrate the utility of VIKI-Bench, we propose VIKI-R, a two-stage framework that fine-tunes a pretrained vision-language model (VLM) using Chain-of-Thought annotated demonstrations, followed by reinforcement learning under multi-level reward signals. Our extensive experiments show that VIKI-R significantly outperforms baselines method across all task levels. Furthermore, we show that reinforcement learning enables the emergence of compositional cooperation patterns among heterogeneous agents. Together, VIKI-Bench and VIKI-R offer a unified testbed and method for advancing multi-agent, visual-driven cooperation in embodied AI systems.
Swarm Intelligence Enhanced Reasoning: A Density-Driven Framework for LLM-Based Multi-Agent Optimization
May 21, 2025Recently, many approaches, such as Chain-of-Thought (CoT) prompting and Multi-Agent Debate (MAD), have been proposed to further enrich Large Language Models' (LLMs) complex problem-solving capacities in reasoning scenarios. However, these methods may fail to solve complex problems due to the lack of ability to find optimal solutions. Swarm Intelligence has been serving as a powerful tool for finding optima in the field of traditional optimization problems. To this end, we propose integrating swarm intelligence into the reasoning process by introducing a novel Agent-based Swarm Intelligence (ASI) paradigm. In this paradigm, we formulate LLM reasoning as an optimization problem and use a swarm intelligence scheme to guide a group of LLM-based agents in collaboratively searching for optimal solutions. To avoid swarm intelligence getting trapped in local optima, we further develop a Swarm Intelligence Enhancing Reasoning (SIER) framework, which develops a density-driven strategy to enhance the reasoning ability. To be specific, we propose to perform kernel density estimation and non-dominated sorting to optimize both solution quality and diversity simultaneously. In this case, SIER efficiently enhances solution space exploration through expanding the diversity of the reasoning path. Besides, a step-level quality evaluation is used to help agents improve solution quality by correcting low-quality intermediate steps. Then, we use quality thresholds to dynamically control the termination of exploration and the selection of candidate steps, enabling a more flexible and efficient reasoning process. Extensive experiments are ...
Multi-scale Frequency Enhancement Network for Blind Image Deblurring
Nov 11, 2024Image deblurring is an essential image preprocessing technique, aiming to recover clear and detailed images form blurry ones. However, existing algorithms often fail to effectively integrate multi-scale feature extraction with frequency enhancement, limiting their ability to reconstruct fine textures. Additionally, non-uniform blur in images also restricts the effectiveness of image restoration. To address these issues, we propose a multi-scale frequency enhancement network (MFENet) for blind image deblurring. To capture the multi-scale spatial and channel information of blurred images, we introduce a multi-scale feature extraction module (MS-FE) based on depthwise separable convolutions, which provides rich target features for deblurring. We propose a frequency enhanced blur perception module (FEBP) that employs wavelet transforms to extract high-frequency details and utilizes multi-strip pooling to perceive non-uniform blur, combining multi-scale information with frequency enhancement to improve the restoration of image texture details. Experimental results on the GoPro and HIDE datasets demonstrate that the proposed method achieves superior deblurring performance in both visual quality and objective evaluation metrics. Furthermore, in downstream object detection tasks, the proposed blind image deblurring algorithm significantly improves detection accuracy, further validating its effectiveness androbustness in the field of image deblurring.
SS3DM: Benchmarking Street-View Surface Reconstruction with a Synthetic 3D Mesh Dataset
Oct 29, 2024


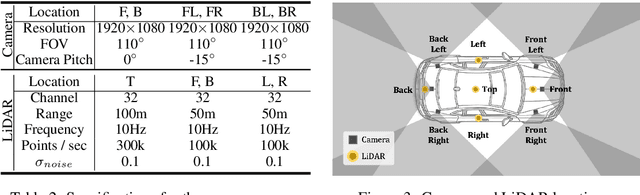
Reconstructing accurate 3D surfaces for street-view scenarios is crucial for applications such as digital entertainment and autonomous driving simulation. However, existing street-view datasets, including KITTI, Waymo, and nuScenes, only offer noisy LiDAR points as ground-truth data for geometric evaluation of reconstructed surfaces. These geometric ground-truths often lack the necessary precision to evaluate surface positions and do not provide data for assessing surface normals. To overcome these challenges, we introduce the SS3DM dataset, comprising precise \textbf{S}ynthetic \textbf{S}treet-view \textbf{3D} \textbf{M}esh models exported from the CARLA simulator. These mesh models facilitate accurate position evaluation and include normal vectors for evaluating surface normal. To simulate the input data in realistic driving scenarios for 3D reconstruction, we virtually drive a vehicle equipped with six RGB cameras and five LiDAR sensors in diverse outdoor scenes. Leveraging this dataset, we establish a benchmark for state-of-the-art surface reconstruction methods, providing a comprehensive evaluation of the associated challenges. For more information, visit our homepage at https://ss3dm.top.
CALF: Benchmarking Evaluation of LFQA Using Chinese Examinations
Oct 02, 2024



Long-Form Question Answering (LFQA) refers to generating in-depth, paragraph-level responses to open-ended questions. Although lots of LFQA methods are developed, evaluating LFQA effectively and efficiently remains challenging due to its high complexity and cost. Therefore, there is no standard benchmark for LFQA evaluation till now. To address this gap, we make the first attempt by proposing a well-constructed, reference-based benchmark named Chinese exAmination for LFQA Evaluation (CALF), aiming to rigorously assess the performance of automatic evaluation metrics for LFQA. The CALF benchmark is derived from Chinese examination questions that have been translated into English. It includes up to 1476 examples consisting of knowledge-intensive and nuanced responses. Our evaluation comprises three different settings to ana lyze the behavior of automatic metrics comprehensively. We conducted extensive experiments on 7 traditional evaluation metrics, 3 prompt-based metrics, and 3 trained evaluation metrics, and tested on agent systems for the LFQA evaluation. The results reveal that none of the current automatic evaluation metrics shows comparable performances with humans, indicating that they cannot capture dense information contained in long-form responses well. In addition, we provide a detailed analysis of the reasons why automatic evaluation metrics fail when evaluating LFQA, offering valuable insights to advance LFQA evaluation systems. Dataset and associated codes can be accessed at our GitHub repository.
Structure Gaussian SLAM with Manhattan World Hypothesis
May 30, 2024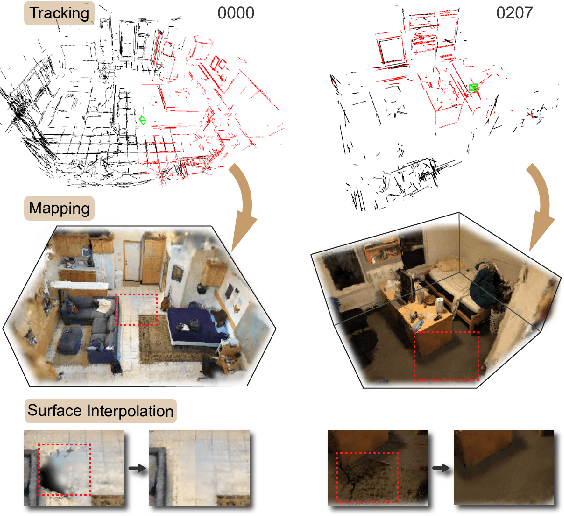


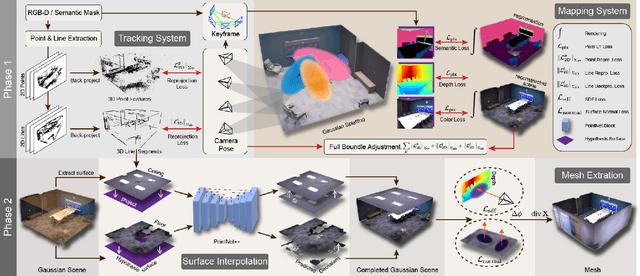
Gaussian SLAM systems have made significant advancements in improving the efficiency and fidelity of real-time reconstructions. However, these systems often encounter incomplete reconstructions in complex indoor environments, characterized by substantial holes due to unobserved geometry caused by obstacles or limited view angles. To address this challenge, we present Manhattan Gaussian SLAM (MG-SLAM), an RGB-D system that leverages the Manhattan World hypothesis to enhance geometric accuracy and completeness. By seamlessly integrating fused line segments derived from structured scenes, MG-SLAM ensures robust tracking in textureless indoor areas. Moreover, The extracted lines and planar surface assumption allow strategic interpolation of new Gaussians in regions of missing geometry, enabling efficient scene completion. Extensive experiments conducted on both synthetic and real-world scenes demonstrate that these advancements enable our method to achieve state-of-the-art performance, marking a substantial improvement in the capabilities of Gaussian SLAM systems.
An Evidential-enhanced Tri-Branch Consistency Learning Method for Semi-supervised Medical Image Segmentation
Apr 10, 2024Semi-supervised segmentation presents a promising approach for large-scale medical image analysis, effectively reducing annotation burdens while achieving comparable performance. This methodology holds substantial potential for streamlining the segmentation process and enhancing its feasibility within clinical settings for translational investigations. While cross-supervised training, based on distinct co-training sub-networks, has become a prevalent paradigm for this task, addressing critical issues such as predication disagreement and label-noise suppression requires further attention and progress in cross-supervised training. In this paper, we introduce an Evidential Tri-Branch Consistency learning framework (ETC-Net) for semi-supervised medical image segmentation. ETC-Net employs three branches: an evidential conservative branch, an evidential progressive branch, and an evidential fusion branch. The first two branches exhibit complementary characteristics, allowing them to address prediction diversity and enhance training stability. We also integrate uncertainty estimation from the evidential learning into cross-supervised training, mitigating the negative impact of erroneous supervision signals. Additionally, the evidential fusion branch capitalizes on the complementary attributes of the first two branches and leverages an evidence-based Dempster-Shafer fusion strategy, supervised by more reliable and accurate pseudo-labels of unlabeled data. Extensive experiments conducted on LA, Pancreas-CT, and ACDC datasets demonstrate that ETC-Net surpasses other state-of-the-art methods for semi-supervised segmentation. The code will be made available in the near future at https://github.com/Medsemiseg.