 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-Centering Humans in LLM Personalization
Jun 04, 2026Despite growing interest, most evaluations of large language models' (LLMs') personalization abilities have relied on synthetic data. It remains unclear how well current personalization systems work for real users. In this paper, we study the gap in LLM personalization performance when using synthetic versus human data. We collect human conversations (550 conversations) and judgments across three stages of personalization: extracting user attributes from conversations (5,949 judgments), pairing relevant attributes with new prompts (11,919), and incorporating relevant attributes into a personalized response (1,101). Incorporating human data reveals system limitations at each stage. Models struggle to extract attributes from human conversations, disagree with human judgments on relevant attributes, and generate personalized responses that humans judge no better than generic responses (though that LLM judges widely rate as better). We introduce two lightweight training-based interventions that shift automated personalization evaluation closer to human data in our first two stages. However, in our third stage we find that learned reward models achieve only modest correlation with human ratings, suggesting that human-aligned personalization quality judgments are difficult to model directly. Our collected data provides a foundation for studying how models should extract, select, and incorporate user information in ways that humans find useful.
NLOS-Aided Joint OTA Synchronization and Off-Grid Imaging for Distributed MIMO Systems
Mar 14, 2026Distributed multiple-input multiple-output (MIMO) architectures enable large-scale integrated sensing and communication (ISAC) by providing high spatial resolution and robustness through spatial diversity. However, practical phase-coherent sensing is challenged by phase synchronization errors and modeling mismatch caused by grid discretization. Existing over-the-air (OTA) synchronization methods typically treat synchronization and sensing tasks separately, which may lead to inaccurate phase alignment when multipath components are used for imaging. In this paper, we propose a non-line-of-sight (NLOS)-aided joint OTA synchronization and off-grid imaging framework for distributed MIMO ISAC systems. First, a line-of-sight (LOS)-assisted coarse synchronization is performed to establish initial phase coherence across distributed links. Subsequently, an iterative refinement stage exploits reconstructed NLOS components obtained from imaging results. By modeling off-grid effects via a first-order Taylor expansion, we transform measurements with nonlinear off-grid offset into an augmented linear model with jointly sparse reflectivity and off-set variables. The imaging problem is reformulated as a structured sparse recovery task and solved using a tailored off-grid approximate message passing (OG-AMP) algorithm. The imaging and synchronization modules are coupled within a closed-loop alternative optimization framework, where improved imaging enables more accurate phase refinement, and vice versa. Numerical results show that the proposed framework achieves accurate synchronization and imaging under phase errors. Compared with conventional approaches, it shows superior robustness and accuracy.
Skill-Aware Data Selection and Fine-Tuning for Data-Efficient Reasoning Distillation
Jan 15, 2026Large reasoning models such as DeepSeek-R1 and their distilled variants achieve strong performance on complex reasoning tasks. Yet, distilling these models often demands large-scale data for supervised fine-tuning (SFT), motivating the pursuit of data-efficient training methods. To address this, we propose a skill-centric distillation framework that efficiently transfers reasoning ability to weaker models with two components: (1) Skill-based data selection, which prioritizes examples targeting the student model's weaker skills, and (2) Skill-aware fine-tuning, which encourages explicit skill decomposition during problem solving. With only 1,000 training examples selected from a 100K teacher-generated corpus, our method surpasses random SFT baselines by +1.6% on Qwen3-4B and +1.4% on Qwen3-8B across five mathematical reasoning benchmarks. Further analysis confirms that these gains concentrate on skills emphasized during training, highlighting the effectiveness of skill-centric training for efficient reasoning distillation.
VeriFact: Enhancing Long-Form Factuality Evaluation with Refined Fact Extraction and Reference Facts
May 14, 2025Large language models (LLMs) excel at generating long-form responses, but evaluating their factuality remains challenging due to complex inter-sentence dependencies within the generated facts. Prior solutions predominantly follow a decompose-decontextualize-verify pipeline but often fail to capture essential context and miss key relational facts. In this paper, we introduce VeriFact, a factuality evaluation framework designed to enhance fact extraction by identifying and resolving incomplete and missing facts to support more accurate verification results. Moreover, we introduce FactRBench , a benchmark that evaluates both precision and recall in long-form model responses, whereas prior work primarily focuses on precision. FactRBench provides reference fact sets from advanced LLMs and human-written answers, enabling recall assessment. Empirical evaluations show that VeriFact significantly enhances fact completeness and preserves complex facts with critical relational information, resulting in more accurate factuality evaluation. Benchmarking various open- and close-weight LLMs on FactRBench indicate that larger models within same model family improve precision and recall, but high precision does not always correlate with high recall, underscoring the importance of comprehensive factuality assessment.
Towards Global AI Inclusivity: A Large-Scale Multilingual Terminology Dataset
Dec 24, 2024The field of machine translation has achieved significant advancements, yet domain-specific terminology translation, particularly in AI, remains challenging. We introduced GIST, a large-scale multilingual AI terminology dataset containing 5K terms extracted from top AI conference papers spanning 2000 to 2023. The terms were translated into Arabic, Chinese, French, Japanese, and Russian using a hybrid framework that combines LLMs for extraction with human expertise for translation. The dataset's quality was benchmarked against existing resources, demonstrating superior translation accuracy through crowdsourced evaluation. GIST was integrated into translation workflows using post-translation refinement methods that required no retraining, where LLM prompting consistently improved BLEU and COMET scores. A web demonstration on the ACL Anthology platform highlights its practical application, showcasing improved accessibility for non-English speakers. This work aims to address critical gaps in AI terminology resources and fosters global inclusivity and collaboration in AI research.
AutoURDF: Unsupervised Robot Modeling from Point Cloud Frames Using Cluster Registration
Dec 07, 2024


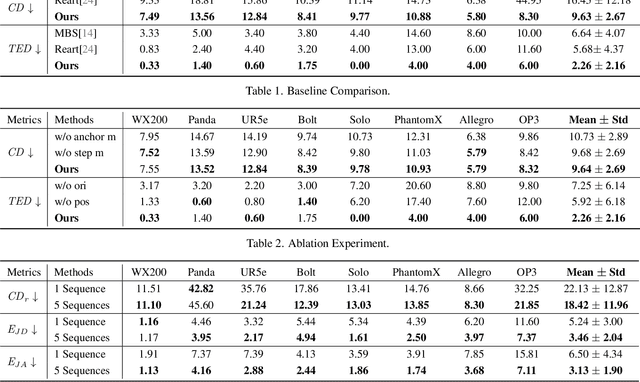
Robot description models are essential for simulation and control, yet their creation often requires significant manual effort. To streamline this modeling process, we introduce AutoURDF, an unsupervised approach for constructing description files for unseen robots from point cloud frames. Our method leverages a cluster-based point cloud registration model that tracks the 6-DoF transformations of point clusters. Through analyzing cluster movements, we hierarchically address the following challenges: (1) moving part segmentation, (2) body topology inference, and (3) joint parameter estimation. The complete pipeline produces robot description files that are fully compatible with existing simulators. We validate our method across a variety of robots, using both synthetic and real-world scan data. Results indicate that our approach outperforms previous methods in registration and body topology estimation accuracy, offering a scalable solution for automated robot modeling.
FactBench: A Dynamic Benchmark for In-the-Wild Language Model Factuality Evaluation
Oct 29, 2024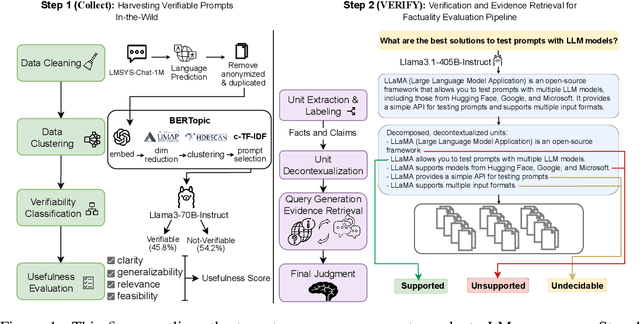
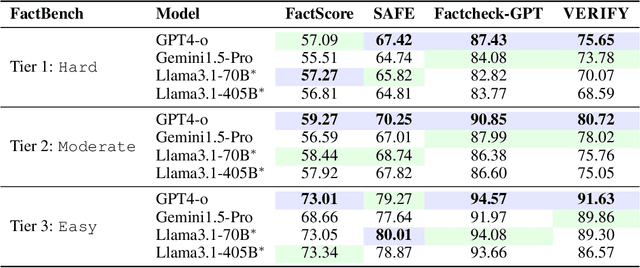

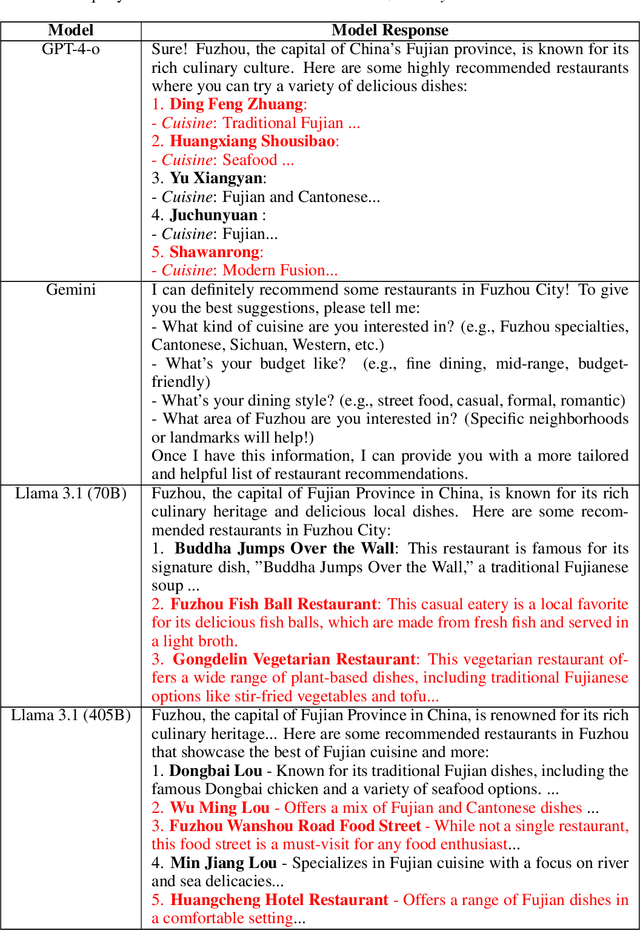
Language models (LMs) are widely used by an increasing number of users, underscoring the challenge of maintaining factuality across a broad range of topics. We first present VERIFY (Verification and Evidence RetrIeval for FactualitY evaluation), a pipeline to evaluate LMs' factuality in real-world user interactions. VERIFY considers the verifiability of LM-generated content and categorizes content units as supported, unsupported, or undecidable based on the retrieved evidence from the Web. Importantly, factuality judgment by VERIFY correlates better with human evaluations than existing methods. Using VERIFY, we identify "hallucination prompts" across diverse topics, i.e., those eliciting the highest rates of incorrect and inconclusive LM responses. These prompts form FactBench, a dataset of 1K prompts across 150 fine-grained topics. Our dataset captures emerging factuality challenges in real-world LM interactions and can be regularly updated with new prompts. We benchmark widely-used LMs from GPT, Gemini, and Llama3.1 family on FactBench, yielding the following key findings: (i) Proprietary models exhibit better factuality, with performance declining from Easy to Hard hallucination prompts. (ii) Llama3.1-405B-Instruct shows comparable or lower factual accuracy than Llama3.1-70B-Instruct across all evaluation methods due to its higher subjectivity that leads to more content labeled as undecidable. (iii) Gemini1.5-Pro shows a significantly higher refusal rate, with over-refusal in 25% of cases. Our code and data are publicly available at https://huggingface.co/spaces/launch/factbench.
SPRIG: Improving Large Language Model Performance by System Prompt Optimization
Oct 18, 2024Large Language Models (LLMs) have shown impressive capabilities in many scenarios, but their performance depends, in part, on the choice of prompt. Past research has focused on optimizing prompts specific to a task. However, much less attention has been given to optimizing the general instructions included in a prompt, known as a system prompt. To address this gap, we propose SPRIG, an edit-based genetic algorithm that iteratively constructs prompts from prespecified components to maximize the model's performance in general scenarios. We evaluate the performance of system prompts on a collection of 47 different types of tasks to ensure generalizability. Our study finds that a single optimized system prompt performs on par with task prompts optimized for each individual task. Moreover, combining system and task-level optimizations leads to further improvement, which showcases their complementary nature. Experiments also reveal that the optimized system prompts generalize effectively across model families, parameter sizes, and languages. This study provides insights into the role of system-level instructions in maximizing LLM potential.
Real or Robotic? Assessing Whether LLMs Accurately Simulate Qualities of Human Responses in Dialogue
Sep 16, 2024Studying and building datasets for dialogue tasks is both expensive and time-consuming due to the need to recruit, train, and collect data from study participants. In response, much recent work has sought to use large language models (LLMs) to simulate both human-human and human-LLM interactions, as they have been shown to generate convincingly human-like text in many settings. However, to what extent do LLM-based simulations \textit{actually} reflect human dialogues? In this work, we answer this question by generating a large-scale dataset of 100,000 paired LLM-LLM and human-LLM dialogues from the WildChat dataset and quantifying how well the LLM simulations align with their human counterparts. Overall, we find relatively low alignment between simulations and human interactions, demonstrating a systematic divergence along the multiple textual properties, including style and content. Further, in comparisons of English, Chinese, and Russian dialogues, we find that models perform similarly. Our results suggest that LLMs generally perform better when the human themself writes in a way that is more similar to the LLM's own style.
CUDA-Accelerated Soft Robot Neural Evolution with Large Language Model Supervision
Apr 12, 2024This paper addresses the challenge of co-designing morphology and control in soft robots via a novel neural network evolution approach. We propose an innovative method to implicitly dual-encode soft robots, thus facilitating the simultaneous design of morphology and control. Additionally, we introduce the large language model to serve as the control center during the evolutionary process. This advancement considerably optimizes the evolution speed compared to traditional soft-bodied robot co-design methods. Further complementing our work is the implementation of Gaussian positional encoding - an approach that augments the neural network's comprehension of robot morphology. Our paper offers a new perspective on soft robot design, illustrating substantial improvements in efficiency and comprehension during the design and evolutionary process.