 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeriFact: Enhancing Long-Form Factuality Evaluation with Refined Fact Extraction and Reference Facts
May 14, 2025Large language models (LLMs) excel at generating long-form responses, but evaluating their factuality remains challenging due to complex inter-sentence dependencies within the generated facts. Prior solutions predominantly follow a decompose-decontextualize-verify pipeline but often fail to capture essential context and miss key relational facts. In this paper, we introduce VeriFact, a factuality evaluation framework designed to enhance fact extraction by identifying and resolving incomplete and missing facts to support more accurate verification results. Moreover, we introduce FactRBench , a benchmark that evaluates both precision and recall in long-form model responses, whereas prior work primarily focuses on precision. FactRBench provides reference fact sets from advanced LLMs and human-written answers, enabling recall assessment. Empirical evaluations show that VeriFact significantly enhances fact completeness and preserves complex facts with critical relational information, resulting in more accurate factuality evaluation. Benchmarking various open- and close-weight LLMs on FactRBench indicate that larger models within same model family improve precision and recall, but high precision does not always correlate with high recall, underscoring the importance of comprehensive factuality assessment.
FactBench: A Dynamic Benchmark for In-the-Wild Language Model Factuality Evaluation
Oct 29, 2024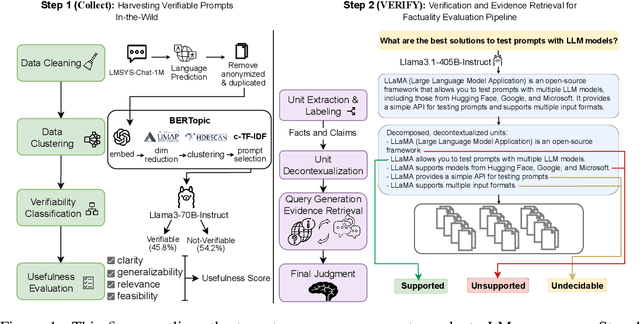
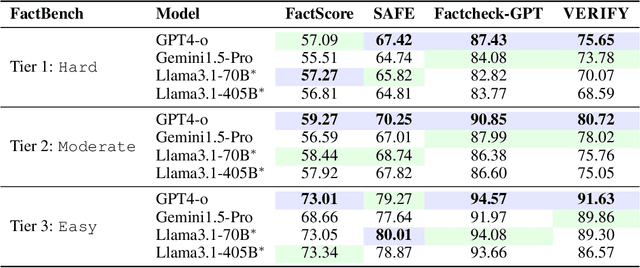

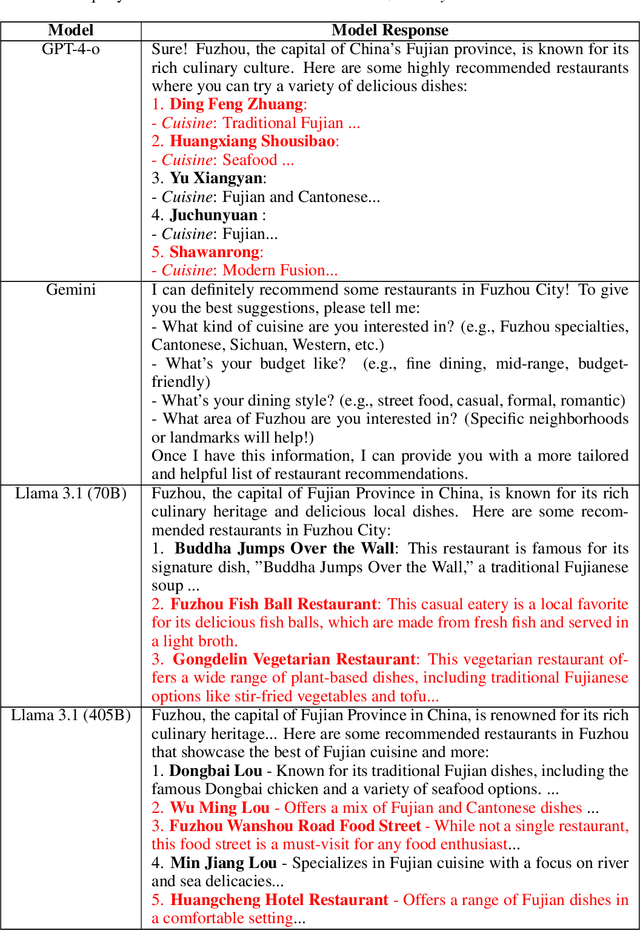
Language models (LMs) are widely used by an increasing number of users, underscoring the challenge of maintaining factuality across a broad range of topics. We first present VERIFY (Verification and Evidence RetrIeval for FactualitY evaluation), a pipeline to evaluate LMs' factuality in real-world user interactions. VERIFY considers the verifiability of LM-generated content and categorizes content units as supported, unsupported, or undecidable based on the retrieved evidence from the Web. Importantly, factuality judgment by VERIFY correlates better with human evaluations than existing methods. Using VERIFY, we identify "hallucination prompts" across diverse topics, i.e., those eliciting the highest rates of incorrect and inconclusive LM responses. These prompts form FactBench, a dataset of 1K prompts across 150 fine-grained topics. Our dataset captures emerging factuality challenges in real-world LM interactions and can be regularly updated with new prompts. We benchmark widely-used LMs from GPT, Gemini, and Llama3.1 family on FactBench, yielding the following key findings: (i) Proprietary models exhibit better factuality, with performance declining from Easy to Hard hallucination prompts. (ii) Llama3.1-405B-Instruct shows comparable or lower factual accuracy than Llama3.1-70B-Instruct across all evaluation methods due to its higher subjectivity that leads to more content labeled as undecidable. (iii) Gemini1.5-Pro shows a significantly higher refusal rate, with over-refusal in 25% of cases. Our code and data are publicly available at https://huggingface.co/spaces/launch/factbench.