 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Cropping and Rotation: Automated Evolution of Powerful Task-Specific Augmentations with Generative Models
Feb 03, 2026Data augmentation has long been a cornerstone for reducing overfitting in vision models, with methods like AutoAugment automating the design of task-specific augmentations. Recent advances in generative models, such as conditional diffusion and few-shot NeRFs, offer a new paradigm for data augmentation by synthesizing data with significantly greater diversity and realism. However, unlike traditional augmentations like cropping or rotation, these methods introduce substantial changes that enhance robustness but also risk degrading performance if the augmentations are poorly matched to the task. In this work, we present EvoAug, an automated augmentation learning pipeline, which leverages these generative models alongside an efficient evolutionary algorithm to learn optimal task-specific augmentations. Our pipeline introduces a novel approach to image augmentation that learns stochastic augmentation trees that hierarchically compose augmentations, enabling more structured and adaptive transformations. We demonstrate strong performance across fine-grained classification and few-shot learning tasks. Notably, our pipeline discovers augmentations that align with domain knowledge, even in low-data settings. These results highlight the potential of learned generative augmentations, unlocking new possibilities for robust model training.
AutoURDF: Unsupervised Robot Modeling from Point Cloud Frames Using Cluster Registration
Dec 07, 2024


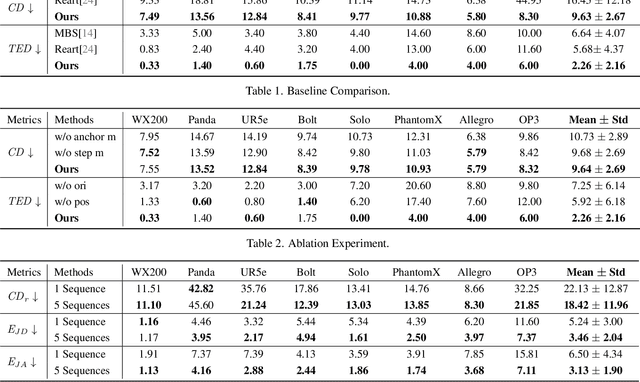
Robot description models are essential for simulation and control, yet their creation often requires significant manual effort. To streamline this modeling process, we introduce AutoURDF, an unsupervised approach for constructing description files for unseen robots from point cloud frames. Our method leverages a cluster-based point cloud registration model that tracks the 6-DoF transformations of point clusters. Through analyzing cluster movements, we hierarchically address the following challenges: (1) moving part segmentation, (2) body topology inference, and (3) joint parameter estimation. The complete pipeline produces robot description files that are fully compatible with existing simulators. We validate our method across a variety of robots, using both synthetic and real-world scan data. Results indicate that our approach outperforms previous methods in registration and body topology estimation accuracy, offering a scalable solution for automated robot modeling.
Teaching Robots to Build Simulations of Themselves
Nov 20, 2023Simulation enables robots to plan and estimate the outcomes of prospective actions without the need to physically execute them. We introduce a self-supervised learning framework to enable robots model and predict their morphology, kinematics and motor control using only brief raw video data, eliminating the need for extensive real-world data collection and kinematic priors. By observing their own movements, akin to humans watching their reflection in a mirror, robots learn an ability to simulate themselves and predict their spatial motion for various tasks. Our results demonstrate that this self-learned simulation not only enables accurate motion planning but also allows the robot to detect abnormalities and recover from damage.