 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollective Memory and Narrative Cohesion: A Computational Study of Palestinian Refugee Oral Histories in Lebanon
Jan 23, 2025This study uses the Palestinian Oral History Archive (POHA) to investigate how Palestinian refugee groups in Lebanon sustain a cohesive collective memory of the Nakba through shared narratives. Grounded in Halbwachs' theory of group memory, we employ statistical analysis of pairwise similarity of narratives, focusing on the influence of shared gender and location. We use textual representation and semantic embeddings of narratives to represent the interviews themselves. Our analysis demonstrates that shared origin is a powerful determinant of narrative similarity across thematic keywords, landmarks, and significant figures, as well as in semantic embeddings of the narratives. Meanwhile, shared residence fosters cohesion, with its impact significantly amplified when paired with shared origin. Additionally, women's narratives exhibit heightened thematic cohesion, particularly in recounting experiences of the British occupation, underscoring the gendered dimensions of memory formation. This research deepens the understanding of collective memory in diasporic settings, emphasizing the critical role of oral histories in safeguarding Palestinian identity and resisting erasure.
You don't need a personality test to know these models are unreliable: Assessing the Reliability of Large Language Models on Psychometric Instruments
Nov 16, 2023The versatility of Large Language Models (LLMs) on natural language understanding tasks has made them popular for research in social sciences. In particular, to properly understand the properties and innate personas of LLMs, researchers have performed studies that involve using prompts in the form of questions that ask LLMs of particular opinions. In this study, we take a cautionary step back and examine whether the current format of prompting enables LLMs to provide responses in a consistent and robust manner. We first construct a dataset that contains 693 questions encompassing 39 different instruments of persona measurement on 115 persona axes. Additionally, we design a set of prompts containing minor variations and examine LLM's capabilities to generate accurate answers, as well as consistency variations to examine their consistency towards simple perturbations such as switching the option order. Our experiments on 15 different open-source LLMs reveal that even simple perturbations are sufficient to significantly downgrade a model's question-answering ability, and that most LLMs have low negation consistency. Our results suggest that the currently widespread practice of prompting is insufficient to accurately capture model perceptions, and we discuss potential alternatives to improve such issues.
Exploring Linguistic Style Matching in Online Communities: The Role of Social Context and Conversation Dynamics
Jul 06, 2023



Linguistic style matching (LSM) in conversations can be reflective of several aspects of social influence such as power or persuasion. However, how LSM relates to the outcomes of online communication on platforms such as Reddit is an unknown question. In this study, we analyze a large corpus of two-party conversation threads in Reddit where we identify all occurrences of LSM using two types of style: the use of function words and formality. Using this framework, we examine how levels of LSM differ in conversations depending on several social factors within Reddit: post and subreddit features, conversation depth, user tenure, and the controversiality of a comment. Finally, we measure the change of LSM following loss of status after community banning. Our findings reveal the interplay of LSM in Reddit conversations with several community metrics, suggesting the importance of understanding conversation engagement when understanding community dynamics.
Bidimensional Leaderboards: Generate and Evaluate Language Hand in Hand
Dec 08, 2021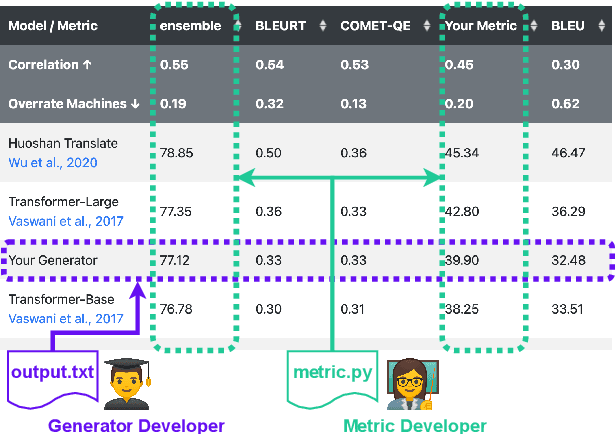
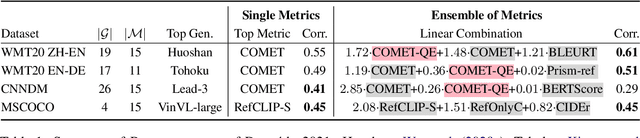
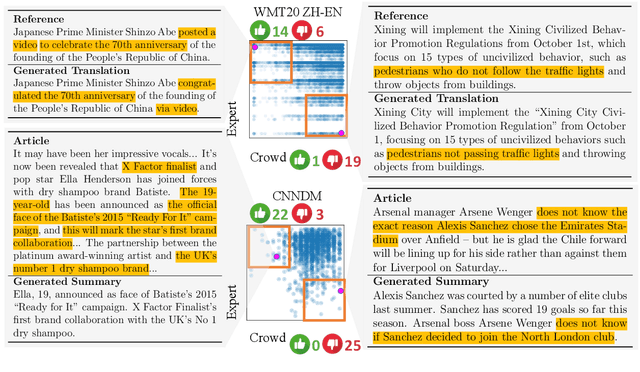

Natural language processing researchers have identified limitations of evaluation methodology for generation tasks, with new questions raised about the validity of automatic metrics and of crowdworker judgments. Meanwhile, efforts to improve generation models tend to focus on simple n-gram overlap metrics (e.g., BLEU, ROUGE). We argue that new advances on models and metrics should each more directly benefit and inform the other. We therefore propose a generalization of leaderboards, bidimensional leaderboards (Billboards), that simultaneously tracks progress in language generation tasks and metrics for their evaluation. Unlike conventional unidimensional leaderboards that sort submitted systems by predetermined metrics, a Billboard accepts both generators and evaluation metrics as competing entries. A Billboard automatically creates an ensemble metric that selects and linearly combines a few metrics based on a global analysis across generators. Further, metrics are ranked based on their correlations with human judgments. We release four Billboards for machine translation, summarization, and image captioning. We demonstrate that a linear ensemble of a few diverse metrics sometimes substantially outperforms existing metrics in isolation. Our mixed-effects model analysis shows that most automatic metrics, especially the reference-based ones, overrate machine over human generation, demonstrating the importance of updating metrics as generation models become stronger (and perhaps more similar to humans) in the future.
Transparent Human Evaluation for Image Captioning
Nov 17, 2021

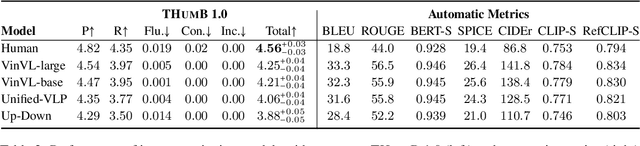
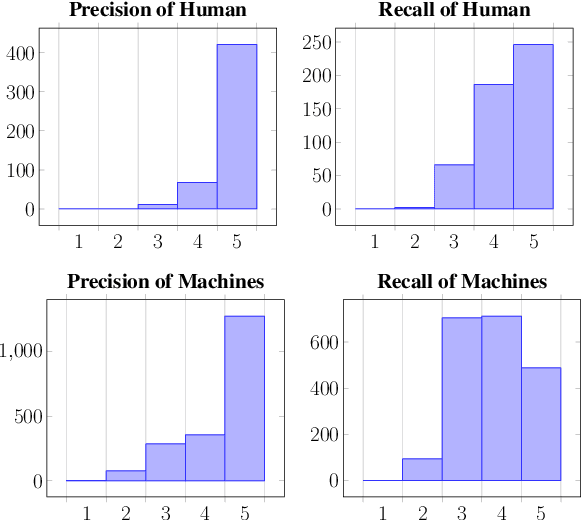
We establish a rubric-based human evaluation protocol for image captioning models. Our scoring rubrics and their definitions are carefully developed based on machine- and human-generated captions on the MSCOCO dataset. Each caption is evaluated along two main dimensions in a tradeoff (precision and recall) as well as other aspects that measure the text quality (fluency, conciseness, and inclusive language). Our evaluations demonstrate several critical problems of the current evaluation practice. Human-generated captions show substantially higher quality than machine-generated ones, especially in coverage of salient information (i.e., recall), while all automatic metrics say the opposite. Our rubric-based results reveal that CLIPScore, a recent metric that uses image features, better correlates with human judgments than conventional text-only metrics because it is more sensitive to recall. We hope that this work will promote a more transparent evaluation protocol for image captioning and its automatic metrics.