 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping the Podcast Ecosystem with the Structured Podcast Research Corpus
Nov 12, 2024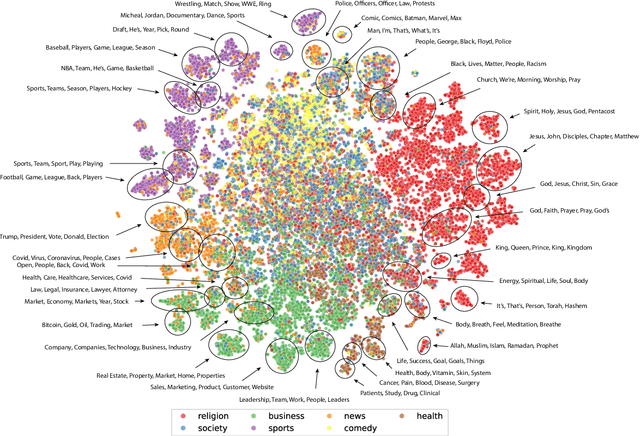

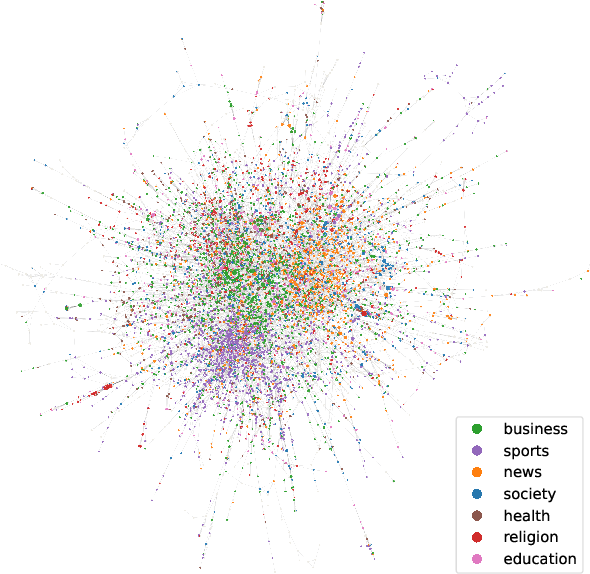

Podcasts provide highly diverse content to a massive listener base through a unique on-demand modality. However, limited data has prevented large-scale computational analysis of the podcast ecosystem. To fill this gap, we introduce a massive dataset of over 1.1M podcast transcripts that is largely comprehensive of all English language podcasts available through public RSS feeds from May and June of 2020. This data is not limited to text, but rather includes audio features and speaker turns for a subset of 370K episodes, and speaker role inferences and other metadata for all 1.1M episodes. Using this data, we also conduct a foundational investigation into the content, structure, and responsiveness of this ecosystem. Together, our data and analyses open the door to continued computational research of this popular and impactful medium.
When it Rains, it Pours: Modeling Media Storms and the News Ecosystem
Dec 04, 2023



Most events in the world receive at most brief coverage by the news media. Occasionally, however, an event will trigger a media storm, with voluminous and widespread coverage lasting for weeks instead of days. In this work, we develop and apply a pairwise article similarity model, allowing us to identify story clusters in corpora covering local and national online news, and thereby create a comprehensive corpus of media storms over a nearly two year period. Using this corpus, we investigate media storms at a new level of granularity, allowing us to validate claims about storm evolution and topical distribution, and provide empirical support for previously hypothesized patterns of influence of storms on media coverage and intermedia agenda setting.
Exploring Linguistic Style Matching in Online Communities: The Role of Social Context and Conversation Dynamics
Jul 06, 2023



Linguistic style matching (LSM) in conversations can be reflective of several aspects of social influence such as power or persuasion. However, how LSM relates to the outcomes of online communication on platforms such as Reddit is an unknown question. In this study, we analyze a large corpus of two-party conversation threads in Reddit where we identify all occurrences of LSM using two types of style: the use of function words and formality. Using this framework, we examine how levels of LSM differ in conversations depending on several social factors within Reddit: post and subreddit features, conversation depth, user tenure, and the controversiality of a comment. Finally, we measure the change of LSM following loss of status after community banning. Our findings reveal the interplay of LSM in Reddit conversations with several community metrics, suggesting the importance of understanding conversation engagement when understanding community dynamics.