 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersona Non Grata: Single-Method Safety Evaluation Is Incomplete for Persona-Imbued LLMs
Apr 14, 2026Personality imbuing customizes LLM behavior, but safety evaluations almost always study prompt-based personas alone. We show this is incomplete: prompting and activation steering expose *different*, architecture-dependent vulnerability profiles, and testing with only one method can miss a model's dominant failure mode. Across 5,568 judged conditions on four standard models from three architecture families, persona danger rankings under system prompting are preserved across all architectures ($ρ= 0.71$--$0.96$), but activation-steering vulnerability diverges sharply and cannot be predicted from prompt-side rankings: Llama-3.1-8B is substantially more AS-vulnerable, whereas Gemma-3-27B and Qwen3.5 are more vulnerable to prompting. The most striking illustration of this divergence is the *prosocial persona paradox*: on Llama-3.1-8B, P12 (high conscientiousness + high agreeableness) is among the safest personas under prompting yet becomes the highest-ASR activation-steered persona (ASR ~0.818). This is an inversion robust to coefficient ablation and matched-strength calibration, and replicated on DeepSeek-R1-Distill-Qwen-32B. A trait refusal alignment framework, in which conscientiousness is strongly anti-aligned with refusal on Llama-3.1-8B, offers a partial geometric account. Reasoning provides only partial protection: two 32B reasoning models reach 15--18% prompt-side ASR, and activation steering separates them sharply in both baseline susceptibility and persona-specific vulnerability. Heuristic trace diagnostics suggest that the safer model retains stronger policy recall and self-correction behavior, not merely longer reasoning.
Say Something Else: Rethinking Contextual Privacy as Information Sufficiency
Apr 07, 2026LLM agents increasingly draft messages on behalf of users, yet users routinely overshare sensitive information and disagree on what counts as private. Existing systems support only suppression (omitting sensitive information) and generalization (replacing information with an abstraction), and are typically evaluated on single isolated messages, leaving both the strategy space and evaluation setting incomplete. We formalize privacy-preserving LLM communication as an \textbf{Information Sufficiency (IS)} task, introduce \textbf{free-text pseudonymization} as a third strategy that replaces sensitive attributes with functionally equivalent alternatives, and propose a \textbf{conversational evaluation protocol} that assesses strategies under realistic multi-turn follow-up pressure. Across 792 scenarios spanning three power-relation types (institutional, peer, intimate) and three sensitivity categories (discrimination risk, social cost, boundary), we evaluate seven frontier LLMs on privacy at two granularities, covertness, and utility. Pseudonymization yields the strongest privacy\textendash utility tradeoff overall, and single-message evaluation systematically underestimates leakage, with generalization losing up to 16.3 percentage points of privacy under follow-up.
Stylistic Evolution and LLM Neutrality in Singlish Language
Jan 10, 2026Singlish is a creole rooted in Singapore's multilingual environment and continues to evolve alongside social and technological change. This study investigates the evolution of Singlish over a decade of informal digital text messages. We propose a stylistic similarity framework that compares lexico-structural, pragmatic, psycholinguistic, and encoder-derived features across years to quantify temporal variation. Our analysis reveals notable diachronic changes in tone, expressivity and sentence construction over the years. Conversely, while some LLMs were able to generate superficially realistic Singlish messages, they do not produce temporally neutral outputs, and residual temporal signals remain detectable despite prompting and fine-tuning. Our findings highlight the dynamic evolution of Singlish, as well as the capabilities and limitations of current LLMs in modeling sociolectal and temporal variations in the colloquial language.
Measuring Fine-Grained Negotiation Tactics of Humans and LLMs in Diplomacy
Dec 20, 2025The study of negotiation styles dates back to Aristotle's ethos-pathos-logos rhetoric. Prior efforts primarily studied the success of negotiation agents. Here, we shift the focus towards the styles of negotiation strategies. Our focus is the strategic dialogue board game Diplomacy, which affords rich natural language negotiation and measures of game success. We used LLM-as-a-judge to annotate a large human-human set of Diplomacy games for fine-grained negotiation tactics from a sociologically-grounded taxonomy. Using a combination of the It Takes Two and WebDiplomacy datasets, we demonstrate the reliability of our LLM-as-a-Judge framework and show strong correlations between negotiation features and success in the Diplomacy setting. Lastly, we investigate the differences between LLM and human negotiation strategies and show that fine-tuning can steer LLM agents toward more human-like negotiation behaviors.
User Perceptions of Privacy and Helpfulness in LLM Responses to Privacy-Sensitive Scenarios
Oct 23, 2025Large language models (LLMs) have seen rapid adoption for tasks such as drafting emails, summarizing meetings, and answering health questions. In such uses, users may need to share private information (e.g., health records, contact details). To evaluate LLMs' ability to identify and redact such private information, prior work developed benchmarks (e.g., ConfAIde, PrivacyLens) with real-life scenarios. Using these benchmarks, researchers have found that LLMs sometimes fail to keep secrets private when responding to complex tasks (e.g., leaking employee salaries in meeting summaries). However, these evaluations rely on LLMs (proxy LLMs) to gauge compliance with privacy norms, overlooking real users' perceptions. Moreover, prior work primarily focused on the privacy-preservation quality of responses, without investigating nuanced differences in helpfulness. To understand how users perceive the privacy-preservation quality and helpfulness of LLM responses to privacy-sensitive scenarios, we conducted a user study with 94 participants using 90 scenarios from PrivacyLens. We found that, when evaluating identical responses to the same scenario, users showed low agreement with each other on the privacy-preservation quality and helpfulness of the LLM response. Further, we found high agreement among five proxy LLMs, while each individual LLM had low correlation with users' evaluations. These results indicate that the privacy and helpfulness of LLM responses are often specific to individuals, and proxy LLMs are poor estimates of how real users would perceive these responses in privacy-sensitive scenarios. Our results suggest the need to conduct user-centered studies on measuring LLMs' ability to help users while preserving privacy. Additionally, future research could investigate ways to improve the alignment between proxy LLMs and users for better estimation of users' perceived privacy and utility.
1-2-3 Check: Enhancing Contextual Privacy in LLM via Multi-Agent Reasoning
Aug 11, 2025Addressing contextual privacy concerns remains challenging in interactive settings where large language models (LLMs) process information from multiple sources (e.g., summarizing meetings with private and public information). We introduce a multi-agent framework that decomposes privacy reasoning into specialized subtasks (extraction, classification), reducing the information load on any single agent while enabling iterative validation and more reliable adherence to contextual privacy norms. To understand how privacy errors emerge and propagate, we conduct a systematic ablation over information-flow topologies, revealing when and why upstream detection mistakes cascade into downstream leakage. Experiments on the ConfAIde and PrivacyLens benchmark with several open-source and closed-sourced LLMs demonstrate that our best multi-agent configuration substantially reduces private information leakage (\textbf{18\%} on ConfAIde and \textbf{19\%} on PrivacyLens with GPT-4o) while preserving the fidelity of public content, outperforming single-agent baselines. These results highlight the promise of principled information-flow design in multi-agent systems for contextual privacy with LLMs.
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
Towards Understanding Deep Learning Model in Image Recognition via Coverage Test
May 12, 2025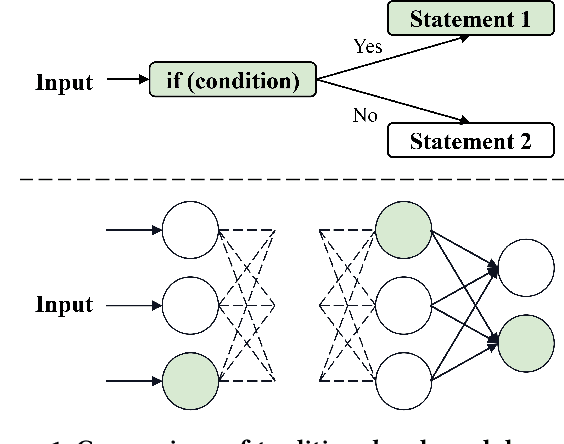
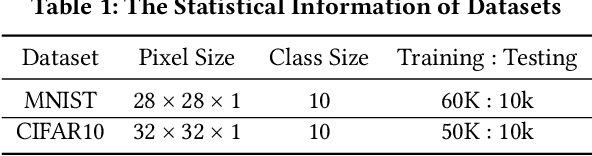
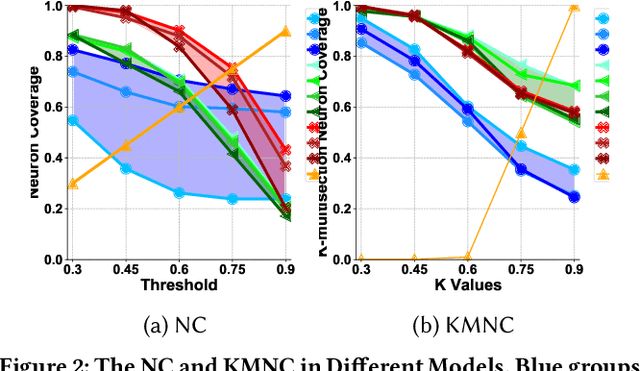
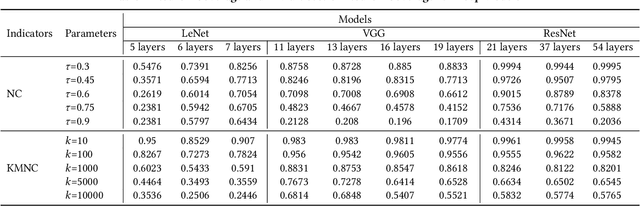
Deep neural networks (DNNs) play a crucial role in the field of artificial intelligence, and their security-related testing has been a prominent research focus. By inputting test cases, the behavior of models is examined for anomalies, and coverage metrics are utilized to determine the extent of neurons covered by these test cases. With the widespread application and advancement of DNNs, different types of neural behaviors have garnered attention, leading to the emergence of various coverage metrics for neural networks. However, there is currently a lack of empirical research on these coverage metrics, specifically in analyzing the relationships and patterns between model depth, configuration information, and neural network coverage. This paper aims to investigate the relationships and patterns of four coverage metrics: primary functionality, boundary, hierarchy, and structural coverage. A series of empirical experiments were conducted, selecting LeNet, VGG, and ResNet as different DNN architectures, along with 10 models of varying depths ranging from 5 to 54 layers, to compare and study the relationships between different depths, configuration information, and various neural network coverage metrics. Additionally, an investigation was carried out on the relationships between modified decision/condition coverage and dataset size. Finally, three potential future directions are proposed to further contribute to the security testing of DNN Models.
Mining Characteristics of Vulnerable Smart Contracts Across Lifecycle Stages
Apr 21, 2025



Smart contracts are the cornerstone of decentralized applications and financial protocols, which extend the application of digital currency transactions. The applications and financial protocols introduce significant security challenges, resulting in substantial economic losses. Existing solutions predominantly focus on code vulnerabilities within smart contracts, accounting for only 50% of security incidents. Therefore, a more comprehensive study of security issues related to smart contracts is imperative. The existing empirical research realizes the static analysis of smart contracts from the perspective of the lifecycle and gives the corresponding measures for each stage. However, they lack the characteristic analysis of vulnerabilities in each stage and the distinction between the vulnerabilities. In this paper, we present the first empirical study on the security of smart contracts throughout their lifecycle, including deployment and execution, upgrade, and destruction stages. It delves into the security issues at each stage and provides at least seven feature descriptions. Finally, utilizing these seven features, five machine-learning classification models are used to identify vulnerabilities at different stages. The classification results reveal that vulnerable contracts exhibit distinct transaction features and ego network properties at various stages.